Deep Learning is learning to represent knowledge with composition of continuous functions.
- overview
- research
- theory
- bayesian deep learning
- unsupervised learning
- generative models
- architectures
- interesting papers
overview by Ian Goodfellow, Yoshua Bengio, Aaron Courville
overview by Yann LeCun, Yoshua Bengio, Geoffrey Hinton
overview by Ilya Sutskever
overview by Juergen Schmidhuber video
overview by Geoffrey Hinton video
overview by Yann LeCun video
overview by Yoshua Bengio video
"The Limitations of Deep Learning" by Francois Chollet (talk video)
"The Future of Deep Learning" by Francois Chollet (talk video)
http://scholarpedia.org/article/Deep_Learning
"A 'Brief' History of Neural Nets and Deep Learning" by Andrey Kurenkov
"On the Origin of Deep Learning" by Wand and Raj paper
Deep Learning: Practice and Trends by Oriol Vinyals and Scott Reed video (slides)
Deep Learning Summer School video
"Deep Learning" by Andrew Ng (videos)
"Neural Networks" by Hugo Larochelle (videos)
"Deep Learning" by Nando de Freitas (videos)
"Neural Networks for Machine Learning" by Geoffrey Hinton (videos)
"Convolutional Neural Networks for Visual Recognition" by Andrej Karpathy (videos)
"Topics in Deep Learning" by Ruslan Salakhutdinov (videos)
"Neural Networks in Machine Learning" by Daniil Polykovsky and Kuzma Hrabrov in russian (videos)
"Deep Learning" by Anton Osokin in russian (videos)
"Deep Learning" by Ian Goodfellow, Yoshua Bengio, Aaron Courville (pdf)
"Neural Networks and Deep Learning" by Michael Nielsen
"Deep Learning with Python" by Francois Chollet
reinforcement learning
bayesian inference and learning
probabilistic programming
knowledge representation and reasoning
natural language processing
recommender systems
information retrieval
- supervised representation learning
- unsupervised representation learning
- large sample complexity
- modeling temporal data with long-term dependencies long-term dependencies
- generative modeling
- marrying representation learning with reasoning
- marrying representation learning with structured prediction
- marrying representation learning and reinforcement learning
- efficient bayesian inference for deep learning
- using learning to speed up the solution of complex inference problems
- understanding the landscape of objective functions in deep learning
- do reasoning and learning representations simultaneously
- metric learning and kernel learning
- dimensionality expansion, sparse modeling
- compositional / hierarchical models
- architecture engineering
"Lessons from Optics, The Other Deep Learning" by Ali Rahimi (theory)
"The Linearization Principle" by Benjamin Recht (theory)
"A Statistical View of Deep Learning: Retrospective" by Shakir Mohamed (theory)
"The Holy Grail of Deep Learning: Modelling Invariances" by Ferenc Huszar (priors)
"Representation Learning and the Information Bottleneck Approach" by Ferenc Huszar (priors)
"Regularization for Deep Learning: A Taxonomy" by Kukacka et al. (priors)
"Modern Theory of Deep Learning: Why Does It Work so Well" by Dmytrii S. (generalization)
"Everything that Works Works Because it's Bayesian: Why Deep Nets Generalize?" (generalization)
"Bottoming Out" by Benjamin Recht (generalization)
"Back-propagation, An Introduction" by Sanjeev Arora and Tengyu Ma (gradient of loss function)
"Calculus on Computational Graphs: Backpropagation" by Chris Olah (gradient of loss function)
"Calculus and Backpropagation" by Massimiliano Tomassoli (gradient of loss function)
"The Zen of Gradient Descent" by Moritz Hardt (optimization of loss function)
"An Overview of Gradient Descent Optimization Algorithms" by Sebastian Ruder (optimization of loss function)
"Why Momentum Really Works" by Gabriel Goh (optimization of loss function)
"Hessian Free Optimization" by Andrew Gibiansky (optimization of loss function)
"The Natural Gradient" by Nick Foti (optimization of loss function)
"Transfer Learning - Machine Learning's Next Frontier" by Sebastian Ruder (representation learning)
"An Overview of Multi-Task Learning in Deep Neural Networks" by Sebastian Ruder (representation learning)
"Toward Theoretical Understanding of Deep Learning" by Sanjeev Arora video
"Interplay between Optimization and Generalization in Deep Neural Networks" by Keerthi Selvaraj video
"Theories of Deep Learning" course from Stanford (videos)
The big difference between deep learning and classical statistical machine learning is that one goes beyond the smoothness assumption and adds other priors on data generating distribution.
-
smoothness
This is the assumption that f(x+de)≈f(x) for unit d and small e. This assumption allows the learner to generalize from training examples to nearby points in input space. Many machine learning algorithms leverage this idea, but it is insufficient to overcome the curse of dimensionality. -
linearity
Many learning algorithms assume that relationships between some variables are linear. This allows the algorithm to make predictions even very far from the observed data, but can sometimes lead to overly extreme predictions. Most simple machine learning algorithms that do not make the smoothness assumption instead make the linearity assumption. These are in fact different assumptions - linear functions with large weights applied to high-dimensional spaces may not be very smooth. -
multiple explanatory factors
Many representation learning algorithms are motivated by the assumption that the data is generated by multiple underlying explanatory factors, and that most tasks can be solved easily given the state of each of these factors. Learning the structure of p(x) requires learning some of the same features that are useful for modeling p(y|x) because both refer to the same underlying explanatory factors. -
causal factors
The model is constructed in such a way that it treats the factors of variation described by the learned representation h as the causes of the observed data x, and not vice-versa. This is advantageous for semi-supervised learning and makes the learned model more robust when the distribution over the underlying causes changes or when we use the model for a new task. -
depth or hierarchical organization of explanatory factors
High-level, abstract concepts can be defined in terms of simple concepts, forming a hierarchy. From another point of view, the use of a deep architecture expresses our belief that the task should be accomplished via a multi-step program with each step referring back to the output of the processing accomplished via previous steps. -
shared factors across tasks
In the context where we have many tasks, corresponding to different yi variables sharing the same input x or where each task is associated with a subset or a function fi(x) of a global input x, the assumption is that each yi is associated with a different subset from a common pool of relevant factors h. Because these subsets overlap, learning all the P(yi|x) via a shared intermediate representation P(h|x) allows sharing of statistical strength between the tasks. -
manifolds
Probability mass concentrates, and the regions in which it concentrates are locally connected and occupy a tiny volume. In the continuous case, these regions can be approximated by low-dimensional manifolds with a much smaller dimensionality than the original space where the data lives. Many machine learning algorithms behave sensibly only on this manifold. Some machine learning algorithms, especially autoencoders, attempt to explicitly learn the structure of the manifold. -
natural clustering
Many machine learning algorithms assume that each connected manifold in the input space may be assigned to a single class. The data may lie on many disconnected manifolds, but the class remains constant within each one of these. This assumption motivates a variety of learning algorithms, including adversarial training. -
temporal and spatial coherence
Slow feature analysis and related algorithms make the assumption that the most important explanatory factors change slowly over time, or at least that it is easier to predict the true underlying explanatory factors than to predict raw observations such as pixel values. -
sparsity
Most features should presumably not be relevant to describing most inputs - there is no need to use a feature that detects elephant trunkswhen representing an image of a cat. It is therefore reasonable to impose a prior that any feature that can be interpreted as “present” or “absent” should be absent most of the time. -
simplicity of factor dependencies
In good high-level representations, the factors are related to each other through simple dependencies. The simplest possible is marginal independence, P(h) = Πi P(hi), but linear dependencies or those captured by a shallow autoencoder are also reasonable assumptions. This can be seen in many laws of physics, and is assumed when plugging a linear predictor or a factorized prior on top of a learned representation.
(Ian Goodfellow, Youshua Bengio, Aaron Courville)
"Learning algorithms that learn to represent functions with many levels of composition (more than 2 or 3) are said to have a deep architecture. Results in computational theory of circuits strongly suggest that, compared to their shallow counterparts, deep architectures are much more efficient in terms of representation, that is, can require a smaller number of computational elements or of parameters to approximate a target function. In spite of the fact that 2-level architectures (such as one-hidden layer neural network or kernel machine) are able to represent any function, they may need a huge number of elements and, consequently, of training examples."
"What is the architectural depth of decision trees and decision forests? It depends on what elementary units of computation are allowed on each level. By analogy with disjunctive normal form (which is usually assigned an architectural depth of two) one would assign an architectural depth of two to a decision tree, and of three to decision forests or boosted trees. The top-level disjunction computed by a decision tree is a sum over the terms associated with each leaf. A first-level conjunctive term is a product of the indicator functions associated with each internal node and with the predicted constant associated with the leaf. With this interpretation, a decision forest has an architectural depth of three. An extra summation layer is added. Note how this summation layer is very different from the top layer of the decision tree architecture. Although both perform a summation, the decision tree top layer sums over mutually exclusive terms, whereas the decision forest sums over terms which are generally nonzero, allowing an exponential number of combinations of leaves (one from each tree) to be added."
"Whereas other nonparametric learning algorithms also suffer from the curse of dimensionality, the way in which the problem appears in the case of decision trees is different and helps to focus on the fundamental difficulty. The general problem is not really dimensionality, nor is it about a predictor that is a sum of purely local terms (like kernel machines). The problem arises from dividing the input space in regions (in a hard way in the case of decision trees) and having separate parameters for each region. Unless the parameters are tied in some way or regularized using strong prior knowledge, the number of available examples thus limits the complexity one can capture, that is, the number of independent regions that can be distinguished."
"Non-local generalization refers to the ability to generalize to a huge space of possible configurations of the underlying causes of the data, potentially very far from observed training data, going beyond linear combinations of training examples that have been seen in the neighborhood of given input. Nearest-neighbor methods and related ones like kernel machines and decision trees can only generalize in some neighborhood around the training examples, in a way that is simple (like linear interpolation or extrapolation). Because the number of possible configurations of the underlying concepts that explain the data is exponentially large, this kind of generalization is good but not sufficient at all."
"Decision trees and many other machine learning algorithms are doomed to generalize poorly because they partition the input space and then allocate separate parameters to each region. Thus no generalization to new regions or across regions. No way you can learn a function which needs to vary across a number of distinguished regions that is greater than the number of training examples. Neural nets do not suffer from that and can generalize "non-locally" because each parameter is re-used over many regions (typically half of all the input space, in a regular neural net)."
"The basic reason we get potentially exponential gains in deep neural networks is that we have compositionality of the parameters, i.e., the same parameters can be re-used in many contexts, so O(N) parameters can allow to distinguish O(2^N) regions in input space, whereas with nearest-neighbor-like things, you need O(N) parameters (i.e. O(N) examples) to characterize a function that can distinguish betwen O(N) regions."
"This "gain" is only for some target functions, or more generally, we can think of it like a prior. If the prior is applicable to our target distribution, we can gain a lot. As usual in machine learning, there is no real free lunch. The good news is that this prior is very broad and seems to cover most of the things that humans learn about. What it basically says is that the data we observe are explained by a bunch of underlying factors, and that you can learn about each of these factors without requiring to see all of the configurations of the other factors. This is how you are able to generalize to new configurations and get this exponential statistical gain."
"Being a universal approximator does not tell you how many hidden units you will need. For arbitrary functions, depth does not buy you anything. However, if your function has structure that can be expressed as a composition, then depth could help you save big, both in a statistical sense (less parameters can express a function that has a lot of variations, and so need less examples to be learned) and in a computational sense (less parameters = less computation)."
"There are many kinds of intractabilities that show up in different places with various learning algorithms. The more tractable the easier to deal with in general, but it should not be at the price of losing crucial expressive power. All the interesting models suffer from intractability of minimizing the training criterion wrt the parameters (i.e. training is fundamentally hard, at least in theory). SVMs and other related kernel machines do not suffer from that problem, but they may suffer from poor generalization unless you provide them with the right feature space (which is precisely what is hard, and what deep learning is trying to do)."
(Yoshua Bengio)
"Our understanding of deep learning is still far from complete. A satisfactory characterization of deep learning should cover the following parts:
- representation power — what types of functions could deep neural networks represent and what are the advantages over using shallow models?
- optimization of the empirical loss — can we characterize the convergence of stochastic gradient descent on the non-convex empirical loss encountered in deep learning?
- generalization — why do deep learning models, despite being highly over-parameterized, could still generalize well?"
("Theory of Deep Learning III: Generalization Properties of SGD" by Zhang et al. paper)
"There are two main gaps in our understanding of neural networks: optimization hardness and generalization performance."
"Training a neural network requires solving a highly non-convex optimization problem in high dimensions. Current training algorithms are all based on gradient descent, which only guarantees convergence to a critical point (local minimum or saddle point). In fact, Anandkumar & Ge 2016 proved that finding even a local minimum is NP-hard, which means that (assuming P != NP) there exist "bad", hard to escape, saddle points in the error surface. Yet, these training algorithms are empirically effective for many practical problems, and we don't know why. There have been theoretical papers such as Choromanska et al. 2016 and Kawaguchi 2016 which prove that under certain assumptions the local minima are essentially as good as the global minima, but the assumptions they make are somewhat unrealistic and they don't address the issue of the bad saddle points."
"The other main gap in our understanding is generalization performance: how well does the model perform on novel examples not seen during training? It's easy to show that in the limit of an infinite number of training examples (sampled i.i.d. from a stationary distribution), the training error converges to the expected error on novel examples (provided that you could train to the global optimum). But since we don't have infinite training examples, we are interested in how many examples are needed to achieve a given difference between training and generalization error. Statistical learning theory studies these generalization bounds. Empirically, training a large modern neural network requires a large number of training examples, but not that monumentally large to be practically unfeasible. But if you apply the best known bounds from statistical learning theory (for instance Gao & Zhou 2014) you typically get these unfeasibly huge numbers. Therefore these bounds are very far from being tight, at least for practical problems."
"One of the reasons might be that these bounds tend to assume very little about the data generating distribution, hence they reflect the worst-case performance against adversarial environments, while "natural" environments tend to be more "learnable". It is possible to write distribution-dependent generalization bounds, but we don't know how to formally characterize a distribution over "natural" environments. Approaches such as algorithmic information theory are still unsatisfactory. Therefore we still don't know why neural networks can be trained without overfitting."
"Furthermore, it should be noted that these two main issues seem to be related in a still poorly understood way: the generalization bounds from statistical learning theory assume that the model is trained to the global optimum on the training set, but in a practical setting you would never train a neural network until convergence even to a saddle point, as to do so would typically cause overfitting. Instead you stop training when the error on a held-out validation set (which is a proxy for the generalization error) stops improving. This is known as "early stopping". So in a sense all this theoretical research on bounding the generalization error of the global optimum may be quite irrelevant: not only we can't efficiently find it, but even if we could, we would not want to, since it would perform worse on novel examples than many "sub-optimal" solutions. It may be the case that optimization hardness is not a flaw of neural network, on the contrary, maybe neural networks can work at all precisely because they are hard to optimize."
"All these observations are empirical and there is no good theory that explains them. There is also no theory that explains how to set the hyperparameters of neural networks (hidden layer width and depth, learning rates, architectural details, etc.). Practitioners use their intuition honed by experience and lots of trial and error to come up with effective values, while a theory could allow us to design neural networks in a more systematic way."
(Antonio Valerio Miceli-Barone)
bayesian inference and learning
"Bayesian Reasoning and Deep Learning in Agent-based Systems" by Shakir Mohamed video
"Is Bayesian Deep Learning the Most Brilliant Thing Ever" panel discussion video
"Neurobayesian Approach for Machine Learning" by Dmitry Vetrov video in russian
(write-up in russian)
"Bayesian Methods in Deep Learning" school in russian
(videos in russian)
"Marrying Graphical Models & Deep Learning" by Max Welling video
"Graphical Models" chapter of "Deep Learning" book by Goodfellow, Bengio, Courville
"A Neural Network is a Monference, Not a Model" by Jacob Andreas
"Deep Learning and Graphical Models" by Yann LeCun
variational inference
variational autoencoder
"A History of Bayesian Neural Networks" by Zoubin Ghahramani video
"Bayesian Neural Networks" by Dmitry Molchanov video in russian
(slides in english)
"Deep Learning: Efficiency is the Driver of Uncertainty" by Neil Lawrence
"Deep Learning Is Not Good Enough, We Need Bayesian Deep Learning for Safe AI" by Alex Kendall
"Scalable and Flexible Models of Uncertainty" course by Roger Grosse
"What My Deep Model Doesn't Know..." by Yarin Gal
"Uncertainty In Deep Learning" by Yarin Gal
"Information Theory, Pattern Recognition and Neural Networks" course by David MacKay video
"A Statistical View of Deep Learning" by Shakir Mohamed:
- "Recursive GLMs"
- "Auto-encoders and Free Energy"
- "Memory and Kernels"
- "Recurrent Nets and Dynamical Systems"
- "Generalisation and Regularisation"
- "What is Deep?"
"Everything that Works Works Because it's Bayesian: Why Deep Nets Generalize?" by Ferenc Huszar
bayesian deep learning - bayesian concepts applied to deep learning methods
deep bayesian learning - deep learning concepts applied to bayesian methods
deep learning (framework for constructing flexible models):
- (plus) rich non-linear models for classification and sequence prediction
- (plus) scalable learning using stochastic approximations and conceptually simple
- (plus) easily composable with other gradient-based methods
- (minus) only point estimates
- (minus) hard to score models and do model selection
- (minus) hard to do complexity penalisation
bayesian reasoning (framework for inference and decision making):
- (plus) unified framework for model building, inference, prediction and decision making
- (plus) explicit accounting for uncertainty and variability of outcomes
- (plus) robust to overfitting
- (plus) tools for model selection and composition
- (minus) mainly conjugate and linear models
- (minus) potentially intractable inference leading to expensive computation or long simulation times
"Unsupervised learning, one notion or many?" by Sanjeev Arora and Andrej Risteski
"Goals and Principles of Representation Learning" by Ferenc Huszar video
"Representation Learning and the Information Bottleneck Approach" by Ference Huszar
"Is Maximum Likelihood Useful for Representation Learning?" by Ference Huszar
potential benefits of unsupervised learning:
- take advantage of huge quantitities of unlabeled data
- answer new questions not seen during training about any subset of observed variables given any other subset
- regularizer to help disentangle underlying factors of variation and to solve new tasks from very few examples
- easier optimization by divide and conquer
- structured output - variable to be predicted is high-dimensional composite object like an image or a sentence
approaches to unsupervised learning:
- predict one variable given the others (pseudolikelihood)
- predict a subset of variables given the others (generalized pseudolikelihood)
- predict a variable given the previous ones in some order (fully-visible Bayes nets, autoregressive nets, NADE, generative RNNs)
- given a corrupted observation, recover the original clean point (denoising)
- predict whether the input comes from the data generating distribution or some other distribution (as a probabilistic classifier) (Noise-Constrastive Estimation)
- learn an invertible function such that the transformed distribution is as factorial as possible (NICE, and when considering approximately invertible functions, VAE)
- learn a stochastic transformation so that if we were to apply it many times we would converge to something close to the data generating distribution (Generative Stochastic Networks, generative denoising autoencoders, diffusion inversion = nonequilibrium thermodynamics)
- learn to generate samples that cannot be distinguished by a classifier from the training samples (GAN)
- maximize the likelihood of the data under some probabilistic model
"Deep Generative Models" chapter of "Deep Learning" book by Goodfellow, Bengio, Courville
overview by Ian Goodfellow video
overview by Aaron Courville video
overview by Shakir Mohamed and Danilo Rezende video
"Building Machines that Imagine and Reason: Principles and Applications of Deep Generative Models" by Shakir Mohamed video
"Differentiable Inference and Generative Models" course by David Duvenaud
"A generative model should be able to draw samples from p(x); however estimating p(x) may be computationally intractable. Instead, we often learn a function that maps a vector to an image sample x. The vector may be either be a noise vector, z, drawn from a prior distribution, a label vector, y, or a combination of the two. Probabilistically, these may be interpreted as conditional probabilities: p(x|z), p(x|y) or p(x|z,y). By sampling these conditional probabilities appropriately, novel samples of x may be generated."
"Generative models provide a solution to the problem of unsupervised learning, in which a machine learning system is required to discover the structure hidden within unlabelled data streams. Because they are generative, such models can form a rich imagery of the world in which they are used: an imagination that can harnessed to explore variations in data, to reason about the structure and behaviour of the world, and ultimately, for decision-making and acting."
why generative models?
-
data efficiency and semi-supervised learning
Generative models can reduce the amount of data required. As a simple example, building an image classifier p(class|image) requires estimating a very high-dimenisonal function, possibly requiring a lot of data, or clever assumptions. In contrast, we could model the data as being generated from some low-dimensional or sparse latent variables z, as in p(image)=∫p(image|z)p(z)dzp(image)=∫p(image|z)p(z)dz. Then, to do classification, we only need to learn p(class|z), which will usually be a much simpler function. This approach also lets us take advantage of unlabeled data - also known as semi-supervised learning. -
model checking by sampling
Understanding complex regression and classification models is hard - it's often not clear what these models have learned from the data and what they missed. There is a simple way to sanity-check and inspect generative models - simply sample from them, and compare the sampled data to the real data to see if anything is missing. -
understanding
Generative models usually assume that each datapoint is generated from a (usually low-dimensional) latent variable. These latent variables are often interpretable, and sometimes can tell us about the hidden causes of a phenomenon. These latent variables can also sometimes let us do interesting things such as interpolating between examples.
applications of generative models:
- conditional generative models (rich data -> rich data)
- speech synthesis: text -> speech
- machine translation: french -> english
- image -> image segmentation
- environment simulator (simulated experience)
- reinforcement learning
- planning
- leverage unlabeled data (features for supervised tasks)
generative models:
-
implicit density
generative adversarial networks
A way to train generative models by optimizing them to fool a classifier, the discriminator network, that tries to distinguish between real data and data generated by the generator network. -
approximate explicit density
variational autoencoders
Latent variable models that use a neural network to do approximate inference. The recognition network looks at each datapoint x and outputs an approximate posterior on the latents q(z|x) for that datapoint.restricted boltzmann machine
Latent variable model with hidden units conditionally independent given the visible states, so we can quickly get an unbiased sample from the posterior distribution when given a data vector. -
tractable explicit density
autoregressive models
Another way to model p(x) is to break the model into a series of conditional distributions: p(x)=p(x1)p(x2|x1)p(x3|x2,x1)…p(x)=p(x1)p(x2|x1)p(x3|x2,x1)… This is the approach used, for example, by recurrent neural networks. These models are also realitvely easy to train, but the downside is that they don't support all of the same queries we can make of latent variable models.invertible density estimation
A way to specify complex generative models by transforming a simple latent distribution with a series of invertible functions. These approaches are restricted to a more limited set of possible operations, but sidestep the difficult integrals required to train standard latent variable models.
"For models, there are Boltzmann machines, exponential families, PCA, FA, ICA, SFA, graphical models, NICE and followups, deep energy models, and gazillions of other things. For approximation/learning techniques, there's pseudolikelihood, score matching, moment matching, contrastive divergence, and gazillions of other things that don't fit into these three "broad" categories."
"Restricted Boltzmann Machines and Deep Boltzmann Machines were successfully trained by taking advantage of the conditional independence property of their bipartite structure to allow efficient exact or approximate posterior inference on latent variables. However, because of the intractability of their associated marginal distribution, their training, evaluation and sampling procedures necessitate the use of approximations like Mean Field inference and Markov Chain Monte Carlo, whose convergence time for such complex models remains undetermined. Furthermore, these approximations can often hinder their performance."
"Directed graphical models rely on an ancestral sampling procedure, which is appealing both for its conceptual and computational simplicity. They lack, however, the conditional independence structure of undirected models, making exact and approximate posterior inference on latent variables cumbersome. Recent advances in stochastic variational inference and amortized inference, allowed efficient approximate inference and learning of deep directed graphical models by maximizing a variational lower bound on the log-likelihood. In particular, the variational autoencoder algorithm simultaneously learns a generative network, that maps gaussian latent variables z to samples x, and semantically meaningful features by exploiting the reparametrization trick. Still, the approximation in the inference process limits its ability to learn high dimensional deep representations."
"Such approximations can be avoided altogether by abstaining from using latent variables. Autoregressive models can implement this strategy while typically retaining a great deal of flexibility. This class of algorithms tractably models the joint distribution by decomposing it into a product of conditionals using the probability chain rule according to an fixed ordering over dimensions, simplifying log-likelihood evaluation and sampling. PixelRNN trains a network that models the conditional distribution of every individual pixel given previous pixels (to the left and to the top). This is similar to plugging the pixels of the image into a char-rnn, but the RNNs run both horizontally and vertically over the image instead of just a 1D sequence of characters. But the ordering of the dimensions, although often arbitrary, can be critical to the training of the model. The sequential nature of this model limits its computational efficiency. For example, its sampling procedure is sequential and non-parallelizable. Additionally, there is no natural latent representation associated with autoregressive models, and they have not been shown to be useful for semi-supervised learning."
"Generative adversarial networks on the other hand can train any differentiable generative network by avoiding the maximum likelihood principle altogether. Instead, the generative network is associated with a discriminator network whose task is to distinguish between samples and real data. Rather than using an intractable log-likelihood, this discriminator network provides the training signal in an adversarial fashion. The training process can be seen as a game between generative network and discriminative network that tries to classify samples as either coming from the true distribution or the model distribution. Every time discriminator notices a difference between the two distributions the generator adjusts its parameters slightly to make it go away, until at the end (in theory) the generator exactly reproduces the true data distribution and the discriminator is guessing at random, unable to find a difference."
(Laurent Dinh)
"Variational Autoencoder is a probabilistic graphical model whose explicit goal is latent variable modeling, and accounting for or marginalizing out certain variables as part of the modeling process."
"VAE can make good generations (Inverse Autoregressive Flow, discriminative regularization) though it is ideal in settings where latent variables are important (Variational Fair Autoencoder)."
"VAE naturally collapses most dimensions in the latent representations, and you generally get very interpretable dimensions out, although the training dynamics is generally a bit weird."
"VAE's ability to set complex priors for latent variables is also nice especially in cases where you know something should make sense or you have a desired latent distribution. One can also do distributed latent variables and priors over time as in VRNN or fixed latents over a sequence as in VRAE, STORN, and Generating Sentences from a Continuous Latent Space. These all learn interesting and powerful latent representations for sequences, and can be combined with many existing models for sequence modeling."
"Generative Adversarial Networks are explicitly set up to optimize for generative tasks, though it also gained a set of models with a true latent space (BiGAN, ALI). One open problem is evaluation - GANs have no real likelihood barring (poor) Parzen window estimates, though samples are generally quite good (LAPGAN, DCGAN, improved GAN). Semi-supervised recognition is a decent proxy but still evaluation is tough."
"There is some worry that VAE models spread probability mass to places it might not make sense, whereas GAN models may miss modes of true distribution altogether. This stuff is hard to measure and test for but is key for improving our models - some initial approaches based on MMD and various divergences are trying to improve this. GANs can be trained to do conditional generation or amazing text to image generation. There are also models which try to combine GAN and VAE (Autoencoding beyond Pixels, Adversarial Autoencoders) in interesting ways."
"We also have pixelCNN, pixelRNN and real NVP which show that directly optimizing likelihood can also give high quality samples, with none of the training fussiness that GANs have and no component collapse/wasted capacity issues of the VAE. NICE and to an extent Normalizing Flows (though it uses a bound) have pointed this way before."
(Kyle Kastner)
"It's not like one of generative models will win - they will be useful in different situations. The objective function a learning method optimises should ideally match the task we want to apply them for. In this sense, theory suggests that:
- GANs should be best at generating nice looking samples - avoiding generating samples that don't look plausible, at the cost of potentially underestimating the entropy of data.
- VAEs should be best at compressing data, as they maximise (a lower bound to) the likelihood. That said, evaluating the likelihood in VAE models is intractable, so it cannot be used very directly for direct entropy encoding.
- There are many models these days where the likelihood can be computed, such as pixel-RNNs, spatial LSTMs, RIDE, NADE, NICE, etc These should also be best in terms of compression performance."
"Neither GANs or VAEs address semi-supervised representation learning in a very direct or elegant way in their objective functions. The fact that you can use them for semi-supervised learning is kind of a coincidence, although one would intuitively expect them to do something meaningful. If you wanted to do semi-supervised representation learning, I think the most sensible approach is the information bottleneck formulation, to which VAEs are a bit closer."
"Similarly, neither methods do directly address disentangling factors of variation, although both are in a way latent variable models with independent hidden variables, so in a way can be thought of as nonlinear ICA models, trained with a different objective function."
"VAE objective and generally, maximum likelihood, is a more promising training objective for latent variable models from a representation learning viewpoint."
(Ferenc Huszar)
- generative adversarial networks
- variational autoencoder
- autoregressive models
- restricted boltzmann machine
"Deep Generative Models" chapter (section 20.10.4) of "Deep Learning" book by Goodfellow, Bengio, Courville
"NIPS 2016 Tutorial: Generative Adversarial Networks" by Ian Goodfellow paper
tutorial by Ian Goodfellow video (slides)
"The GAN Landscape: Losses, Architectures, Regularization, and Normalization" by Kurach et al. paper
"What Are GANs Useful For?" by Omlos et al. paper
"Probabilistic Deep Learning" by Sebastian Nowozin video
"Implicit Generative Models: Dual and Primal Approaches" by Iliya Tolstikhin video
"Implicit Generative Models" by Dmitry Ulyanov video in russian
(slides in english)
"How to Train Your Generative Models? And Why Does Adversarial Training Work So Well?" by Ferenc Huszar
"An Alternative Update Rule for Generative Adversarial Networks" by Ferenc Huszar
"Adversarial Preference Loss" by Ferenc Huszar
"New Perspectives on Adversarial Training" by Ferenc Huszar
"Some Open Questions" by Sanjeev Arora
"Generalization and Equilibrium in Generative Adversarial Networks" by Sanjeev Arora (talk video)
"Do GANs Actually Do Distribution Learning?" by Sanjeev Arora
"Data distribution is learned via a game between a generator (the generative model) and a discriminator (a teacher providing training signal) that each minimize their own cost. GANs are designed to reach a Nash equilibrium at which each player cannot reduce their cost without changing the other player’s parameters."
"Consists of a generator which converts random noise into samples and a discriminator which tries to distinguish between generated and real samples from training set. The training procedure establishes a minimax game between the generator and the discriminator as follows. On one hand, the discriminator is trained to differentiate between natural samples sampled from the true data distribution, and synthetic samples produced by the generator. On the other hand, the generator is trained to produce samples that confuse the discriminator into mistaking them for genuine samples. The goal is for the generator to produce increasingly more realistic samples as the discriminator learns to pick up on increasingly more subtle inaccuracies that allow it to tell apart real and fake images."
"We let the discriminator and generator play a series of games against each other. We first show the discriminator a mixed batch of real samples from our training set and of fake samples produced by the generator. We then simultaneously optimize the discriminator to answer NO to fake samples and YES to real samples and optimize the generator to fool the discriminator into believing that the fake samples were real. This corresponds to minimizing the classification error wrt. the discriminator and maximizing it wrt. the generator. With careful optimization both generator and discriminator will improve and the generator will eventually start generating convincing samples."
"The cost function used to train a generative model should fit the purpose of the model. If the model is intended for tasks such as generating perceptually correct samples, it is beneficial to maximise the likelihood of a sample drawn from the model, Q, coming from the same distribution as the training data, P. This is equivalent to minimising the Kullback-Leibler distance, DKL[Q||P]. However, if the model is intended for tasks such as retrieval or classification it is beneficial to maximise the likelihood that a sample drawn from the training data is captured by the model, equivalent to minimising DKL[P||Q]. The cost function used in adversarial training optimises the Jensen-Shannon entropy which can be seen as an even interpolation between DKL[Q||P] and DKL[P||Q]."
(Antonia Creswell)
"Adversarial training is powerful when all else fails to quantify divergence between complicated, potentially degenerate distributions in high dimensions, such as images or video. Our toolkit for dealing with images is limited, CNNs are the best tool we have, so it makes sense to incorporate them in training generative models for images. Adversarial training makes no assumptions about the distributions compared, other than sampling from them. This comes very handy when both p and q are nasty such as in the generative adversarial network scenario: there, p is the distribution of natural images, q is a super complicated, degenerate distribution produced by squashing noise through a deep convnet. The price we pay for this flexibility is this: when p or q are actually easy to work with, adversarial training cannot exploit that, it still has to sample."
(Ferenc Huszar)
"All the theory says GANs should be great at the Nash equilibrium, but gradient descent is only guaranteed to get to the Nash equilibrium in the convex case. When both players are represented by neural nets, it’s possible for them to keep adapting their strategies forever without actually arriving at the equilibrium."
- "How do you address the fact that the minimax game between the generator and discriminator may never approach an equilibrium? In other words, how do you build a system using GANs so that you know that it will converge to a good solution?"
- "Even if they do converge, current systems still have issues with global structure: they cannot count (e.g. the number of eyes on a dog) and frequently get long-range connections wrong (e.g. they show multiple perspectives as part of the same image)."
- "How can we use GANs in discrete settings, such as for generating text?"
(Ian Goodfellow)
Unlike autoencoders, which minimize an explicit reconstruction error, forcing a model to remember "perceptually irrelevant" details of data, GANs circumvent this need via parametric discriminator.
In contrast to probabilistic generative models (such as variational autoencoders) GANs don't allow to calculate likelihood of generated sample and don't allow to assess quality of model on test data.
Another disadvantage of GANs is that in their original formulation there is no clear way to perform inference in the model, i.e. to recover the posterior distribution p(z|x).
One can additionally argue that GANs learning process and the lack of a heuristic cost function (such as pixel-wise independent mean-square error) are attractive to representation learning.
Training requires discriminator network to be reoptimised every time generative network changes. Gradient descent in the inner loop of gradient descent makes optimization unstable and slow.
GANs require differentiation through the visible units and thus cannot model discrete data, while VAEs require differentiation through the hidden units and thus can't have discrete latent variables.
generative adversarial networks:
- generator gets local features right but not global structure
- possible underfitting due to non-convergence of optimization
- generator never sees the data
- need REINFORCE to learn discrete visible variables
variational autoencoders:
- gets global image composition right but blurs details
- possible underfitting due to variational approximation
- generator gets direct output target
- need REINFORCE to learn discrete latent variables
"The GAN framework can train any kind of generator net (in theory - in practice, it’s pretty hard to use REINFORCE to train generator nets with discrete outputs). Most other frameworks require that the generator net has some particular functional form, like the output layer being Gaussian. Essentially all of the other frameworks require that the generator net put non-zero mass everywhere. GANs can learn models that generate points only on a thin manifold that goes near the data. There’s no need to design the model to obey any kind of factorization. Any generator net and any discriminator net will work.
Compared to the PixelRNN, the runtime to generate a sample is smaller. GANs produce a sample in one shot, while PixelRNNs need to produce a sample one pixel at a time.
Compared to the VAE, there is no variational lower bound. If the discriminator net fits perfectly, then the generator net recovers the training distribution perfectly. In other words, GANs are asymptotically consistent, while the VAE has some bias.
Compared to deep Boltzmann machines, there is neither a variational lower bound, nor an intractable partition function. The samples are generated in one shot, instead of generated by repeatedly applying a Markov chain operator.
Compared to GSNs, the samples are generated in one shot, instead of generated by repeatedly applying a Markov chain operator.
Compared to NICE and Real NVE, there’s no restriction on the size of the latent code."
(Ian Goodfellow)
"While most deep generative models are trained by maximizing log likelihood or a lower bound on log likelihood, GANs take a radically different approach that does not require inference or explicit calculation of the data likelihood. Instead, two models are used to solve a minimax game: a generator which samples data, and a discriminator which classifies the data as real or generated. In theory these models are capable of modeling an arbitrarily complex probability distribution. When using the optimal discriminator for a given class of generators, the original GAN proposed by Goodfellow et al. minimizes the Jensen-Shannon divergence between the data distribution and the generator, and extensions generalize this to a wider class of divergences. The ability to train extremely flexible generating functions, without explicitly computing likelihoods or performing inference, and while targeting more mode-seeking divergences has made GANs extremely successful in image generation. In practice, however, GANs suffer from many issues, particularly during training. One common failure mode involves the generator collapsing to produce only a single sample or a small family of very similar samples. Another involves the generator and discriminator oscillating during training, rather than converging to a fixed point. In addition, if one agent becomes much more powerful than the other, the learning signal to the other agent becomes useless, and the system does not learn. The set of hyperparameters for which training is successful is generally very small in practice. Once converged, the generative models produced by the GAN training procedure normally do not cover the whole distribution, even when targeting a mode-covering divergence such as KL. Additionally, because it is intractable to compute the GAN training loss, and because approximate measures of performance such as Parzen window estimates suffer from major flaws, evaluation of GAN performance is challenging. Currently, human judgement of sample quality is one of the leading metrics for evaluating GANs. In practice this metric does not take into account mode dropping if the number of modes is greater than the number of samples one is visualizing. In fact, the mode dropping problem generally helps visual sample quality as the model can choose to focus on only the most common modes. These common modes correspond, by definition, to more typical samples. Additionally, the generative model is able to allocate more expressive power to the modes it does cover than it would if it attempted to cover all modes."
(Luke Metz)
"GANs don't minimise likelihood or other better understood things like that, and other than being superior at generating pretty samples it is unclear why they should work in the really interesting applications of generative models: representation, semi-supervised learning. A lot of papers are just various hacks to make them work. Plumbing GANs and VAEs and autoencoders and whatnots together until they produce pretty pictures. Many people in ML are very annoyed by this kind of wild-wild-west attitude, I-can-code-this-up-therefore-it-makes-sense work, this is why deep learning itself was not taken seriously for a long time. It's just one of those things that are overhyped today, and everybody wants to do GANs for X, at the cost of actually trying things that we have known to work well for X for ages. It's quite predictable that once we understand them better there won't be quite as much excitement around them. The same kind of hype and overfocus of attention happened around Bayesian nonparametrics, kernel methods, sparse LASSO-type stuff a few years ago. GANs don't really work today. Practically, they don't really converge, the results are highly cherry-picked with the training stopped when samples look good. If you change a hyperparameter it all falls apart. Fundamentally, it's minimising a lower bound which is dubious. Serious work needs to be done before they reach the maturity of variational inference or something like the EM algorithm."
(Ferenc Huszar)
"Deep Generative Models" chapter (section 20.10.3) of "Deep Learning" book by Goodfellow, Bengio, Courville
tutorial by Carl Doersch paper (code)
"Variational Inference & Deep Learning: A New Synthesis" by Diederik Kingma paper
overview by Aaron Courville video
overview by Dmitry Vetrov video in russian
"Probabilistic Deep Learning" by Sebastian Nowozin video
VAE diagram by Diederik Kingma
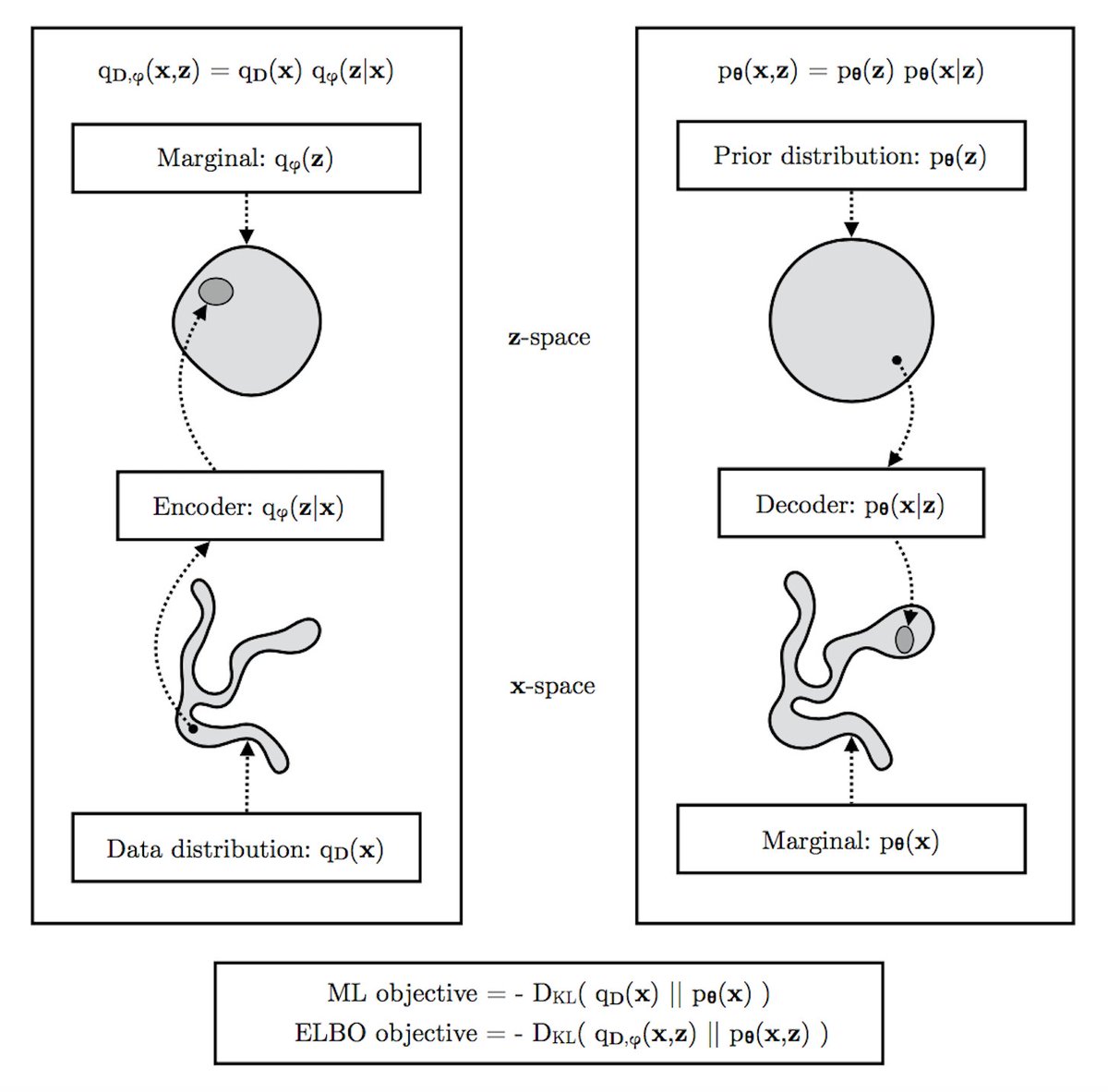{kind=link}
"Variational auto-encoders do not train complex generative models" by Dustin Tran
"VAE = EM" by David McAllester
comparison with generative adversarial networks:
- easier to train and get working
- relatively easy to implement and robust to hyperparameter choices
- tractable likelihood
- has an explicit inference network so it lets one do reconstruction
- if p(x|z) makes conditional independence assumptions then it might make blurring effect
"An advantage for VAEs is that there is a clear and recognized way to evaluate the quality of the model (log-likelihood, either estimated by importance sampling or lower-bounded). Right now it’s not clear how to compare two GANs or compare a GAN and other generative models except by visualizing samples.
A disadvantage of VAEs is that, because of the injected noise and imperfect reconstruction, and with the standard decoder (with factorized output distribution), the generated samples are much more blurred than those coming from GANs.
The fact that VAEs basically optimize likelihood while GANs optimize something else can be viewed both as an advantage or a disadvantage for either one. Maximizing likelihood yields an estimated density that always bleeds probability mass away from the estimated data manifold. GANs can be happy with a very sharp estimated density function even if it does not perfectly coincide with the data density (i.e. some training examples may come close to the generated images but might still have nearly zero probability under the generator, which would be infinitely bad in terms of likelihood)."
(Yoshua Bengio)
"One of the main issues in variational inference is finding the best approximation to an intractable posterior distribution of interest by searching through a class of known probability distributions. The class of approximations used is often limited, e.g., mean-field approximations, implying that no solution is ever able to resemble the true posterior distribution. This is a widely raised objection to variational methods, in that unlike MCMC, the true posterior distribution may not be recovered even in the asymptotic regime. Challenge for VAE-type generative models is to fit posterior approximators that are both flexible and computationally cheap to sample from and differentiate. Simple posterior approximations, like normal distributions with diagonal covariances, are often insufficiently capable of accurately modeling the true posterior distributions. This leads to looseness of the variational bound, meaning that the objective that is optimized (the variational bound) lies far from the objective we’re actually interested in (the marginal likelihood). This leads to many of the problems encountered when trying to scale VAEs up to high-dimensional spatiotemporal datasets."
(Mevlana Gemici)
"One of the benefits of VAE is that it generally gives interpretable latent variables - to do this it basically collapses all the dimensions it doesn't need i.e. 100, 1000 dimensions in the latent, but only a few are used. It is a challenge because this makes it hard to get "big" VAEs, since they tend to just throw away/not use parameters they don't need. Some of the papers are combatting this tendency. Inverse Autoregressive Flow fixes this to some extent. One can see it by training a VAE but having a multiplier (alpha) on the KL. Turning alpha lower and lower lets more and more of the latent be used, until alpha = 0 when it basically just becomes a regular autoencoder. It is an interesting attribute of the VAE, and one that is important to know about. The disentangling is a powerful thing VAEs can do, but it does have a cost if the goal is feature learning or generation."
(Kyle Kastner)
"Deep Generative Models" chapter (sections 20.10.7-20.10.10) of "Deep Learning" book by Goodfellow, Bengio, Courville
"Sequence-To-Sequence Modeling with Neural Networks" by Oriol Vinyals and Navdeep Jaitly video
"Generative Modelling as Sequence Learning" by Nal Kalchbrenner video
"Autoregressive Generative Models with Deep Learning" by Hugo Larochelle video
"Autoregressive Generative Models" by Hugo Larochelle, Vincent Dumoulin, Aaron Courville slides
- choose an ordering of the dimensions in input x
- define the conditionals in the product rule expression of p(x) = ∏ p(xk|x<k)
properties:
- pros: p(x) is tractable, so easy to train, easy to sample (though slower)
- cons: doesn't have a natural latent representation
examples:
- masked autoencoder distribution estimator (MADE), pixelCNN
- neural autoregressive distribution estimator (NADE), spatial LSTM, pixelRNN
RNNs:
- unbounded receptive field
- serial training compute: O(N) matrix-vector ops
- O(N) dependency steps
- size of state does not depend on captured context length: O(1)
Masked CNNs:
- finite (exponential) receptive field O(L) or O(2^L)
- parallel training compute: O(1) matrix-vector ops
- O(N) dependency steps or O(log N) for dilated conv
- size of state depends on captured context length: O(N) or O(log N)
Masked Self-Attention Nets:
- unbounded receptive field
- parallel compute: O(1) matrix-vector ops, but O(N^2) factor
- O(1) dependency steps
- the state is the captured context: O(N)
"Structured Probabilistic Models for Deep Learning" chapter (section 16.7.1) of "Deep Learning" book by Goodfellow, Bengio, Courville
"The Miracle of the Boltzmann Machine" by Ilya Sutskever
"Undirected Models are Better at Sampling" by Ilya Sutskever
introduction by Geoffrey Hinton:
- overview (9:00)
video - "Hopfield Nets and Boltzmann Machines"
video - "Restricted Boltzmann Machines"
video - "Stacking RBMs to Make Deep Belief Nets"
video - "Deep Neural Nets with Generative Pre-Training"
video
"Undirected Graphical Models" tutorial by Aaron Courville video
"Learning Deep Generative Models" tutorial by Ruslan Salakhutdinov paper
"RBM learns internal (not defined by the user) concepts that help to explain (that can generate) the observed data. These concepts are captured by random variables (called hidden units) that have a joint distribution (statistical dependencies) among themselves and with the data, and that allow the learner to capture highly non-linear and complex interactions between the parts (observed random variables) of any observed example (like the pixels in an image). One can also think of these higher-level factors or hidden units as another, more abstract, representation of the data. RBM is parametrized through simple two-way interactions between every pair of random variable involved (the observed ones as well as the hidden ones)."
- can characterize uncertainty
- deal with missing or noisy data
- can simulate from the model
"Deep Architecture Genealogy"
"The Neural Network Zoo"
"In classification task we want to model probability of a class label Y given some inputs or higher level features X=(X1...Xn).
- fully connected layers
We can't assume much about the features, and we want to model joint probability of all the features in a sample of X together.
p(X1, X2, ... Xn)
- convolutional layers
There is locality (or grouping in some sense), so we can model them in "blocks" (sometimes overlapping blocks) independently.
p(X1...Xm-1) * p(Xm-1...Xn) ...
- recurrent layers
Things are sequential, so we can model conditional on the things we have seen before but it can depend on everything that has come before.
p(Xn | X1...Xn-1) * p(Xn-1 | X1...Xn-2) ...
- Markov assumption
Things are sequential but only depend on what happened just before. Note that this looks a lot like a certain kind of convolution.
p(Xn | Xn-1) * p(Xn-1 | Xn-2) ...
- bidirectional recurrent layers
Look into the "past" and "future". This is good for some cases (text translation) but can be bad for others (one-pass generative modeling).
product of p(Xn | X!=n) for all indices in n
- conditioning/attention/loss layers
There is information here which is important to my task/goal.
p(Y|X) rather than just p(X)
"Bayes rule: p(Y | X) = p(X | Y) * p(Y) / p(X)
In supervised classification, we basically only care about p(Y | X); p(X) and p(Y) are basically thrown away if we don't know anything about X or Y. Note that we could probably do better if we did assume something about p(X) or P(Y), and that assumption was accurate.
In semi-supervised classification we generally care about both p(Y | X) and p(X) because we exploit p(X) on the way to p(Y | X) since we have way more X samples than known Y samples.
For unsupervised learning p(X) is all we know and usually all we care about, so we can optimize it directly (in general, with certain assumptions).
In many cases we assume no knowledge (aka uninformative priors) for X and Y, i.e. we don't know anything about p(X) and p(Y), so it just ends up approximated as p(Y | X) ~ p(X | Y).
Then we can maximize p(Y | X) (the predictive power of the model) by also maximizing p(X | Y) (probability of the data under its known label). Which is also the same thing as minimizing -log p(X | Y) aka the loss (like binary and categorical cross-entropy for classification).
For unsupervised models we would just minimize the negative log-probability (or just negative probability, though it is harder numerically) by having loss be -log p(X) (like mean squared error such as for autoencoders)."
(Kyle Kastner)
"A Statistical View of Deep Learning" by Shakir Mohamed
- convolutional neural network
- recurrent neural network
- attention
- compute and memory
- distributed representation
"Convolutional Neural Network" chapter of "Deep Learning" book by Goodfellow, Bengio, Courville
overview by Andrej Karpathy video
overview by Serena Young video
overview by Nando de Freitas video
overview by Rob Fergus video
overview by Ian Goodfellow video
overview by Victor Lempitsky video in russian
overview by Andrej Karpathy
"Conv Nets: A Modular Perspective" by Chris Olah
"Understanding Convolutions" by Chris Olah
"CNN Architectures" by Serena Young video
overview of architectures by Eugenio Culurciello
graph neural network
"Graph Neural Networks: Variations and Applications by Alexander Gaunt video
"Convolutional Neural Networks on Graphs" by Xavier Bresson video
"Large-scale Graph Representation Learning" by Jure Leskovec video
"Graph Convolutional Networks" by Thomas Kipf
http://geometricdeeplearning.com
"Geometric Deep Learning" tutorial by Bronstein, Bruna, Szlam, Bresson, LeCun video
"Geometric Deep Learning" by Michael Bronstein video
"Geometric Deep Learning" by Joan Bruna and Michael Bronstein audio
"Geometric Deep Learning: Going beyond Euclidean Data" by Bronstein, Bruna, LeCun, Szlam, Vandergheynst paper
"Compared to recurrent networks these models can have many, many layers which can make up for the lack of explicit state to some extent. Also the fact that they can be fully parallelised across time during training and don't require backpropagation through time is a considerable advantage. Not to mention that it's much easier to build models with large temporal receptive fields."
"Compared to recurrent networks using only the output as state is very limiting, and conversely, hidden states are extremely powerful. Most algorithms we design do not just use the outputs as variables, but there are rather hundreds or billions of states that determine the output. Recurrent networks are just notoriously hard to train, so it is a matter of finding the right regularization techniques."
"It is easy to imagine computations that would be vastly more efficient using hidden states. For example if you want to track a person hiding behind a wall. If you increase the time period the person spends hiding behind the wall, then at some point the advantages from cheap training of passive/hierarchical/diluted convolutional models will be outperformed by a NN with a state that is encoded at network level, protected by gates, or maintained by some recall mechanism."
"Recurrent Neural Network" chapter of "Deep Learning" book by Goodfellow, Bengio, Courville
overview by Andrej Karpathy video
overview by Justin Johnson video
overview by Ian Goodfellow video
overview by Yoshua Bengio video
"The Unreasonable Effectiveness of Recurrent Neural Networks" by Andrej Karpathy
"A Critical Review of Recurrent Neural Networks for Sequence Learning" by Lipton et al.
"Learning Over Long Time Lags" by Hojjat Salehinejad
Long Short Term Memory (LSTM)
overview by Andrej Karpathy video
"Understanding LSTM Networks" by Chris Olah
"Understanding, Deriving and Extending the LSTM"
"Backpropogating an LSTM: A Numerical Example" by Aidan Gomez
"Why LSTMs Stop Your Gradients From Vanishing: A View from the Backwards Pass" by Noah Weber
"LSTM is the most sensible RNN architecture. It can be derived directly from vanilla RNN in 2 steps:
- Don't multiply, use addition instead.
- Gate all operations so that you don't cram everything."
"First statement means instead of multiplying the previous hidden state by a matrix to get the new state, you add something to your old hidden state and get the new state (not called "hidden" but called "cell"). Why? Because multiplication ~ vanishing gradients. Now, we are capable of long term memory since we are not losing it by repeated multiplications. But is storing everything useful? Obviously no. Also, do we want to output everything we have stored at each instant? Again no."
"There are 3 projections in a vanilla RNN: input to hidden, hidden to hidden, hidden to output. LSTM regulates each one of them with input, forget and output gates respectively. Each of these gates are calculated as a function of what we already know, and current input i.e f(H_prev, X). Now our internal hidden state will become holy and the access to it becomes highly restricted. So it has a new name - the cell."
"Only certain information, iff it's deemed relavent considering the past can get in (use of "he" in a sentence means we now know the gender of the subject, we send it in - use of another "he" in same sentence is not useful, so throw it away). Some of it is forgotten with time or due to certain inputs (like forgetting the gender of the subject at the end of a sentence). And out of all the information we store, only some of it is sent out and this is regulated by the output gate (we don't want to keeping telling that the subject is male, we will only do so when we have to)."
"All in all, instead of multiplying with a fixed matrix, you instead calculate what should change in your cell and get the change as a result of an addition step. And, you send out only some your cell as the output."
(Pranav Shyam)
"Limitations of RNNs: A Computational Perspective" by Edward Grefenstette video
"Beyond Seq2Seq with Augmented RNNs" by Edward Grefenstette video
"Frontiers in Recurrent Neural Network Research" by Alex Graves video
"New Directions for Recurrent Neural Networks" by Alex Graves video
overview by Oriol Vinyals video
overview by Mikhail Figurnov video in russian
overview by Denny Britz
overview by Chris Olah and Shan Carter
overview by Alex Graves
"Attention Is All You Need" by Vaswani et al. paper summary
"Models that can do even more sequential computation should be more successful because they are able to express more intricate algorithms. It’s like allowing your parallel computer to run for more steps. We already see the beginning of this, in the form of attention models. In current approach, you take your input vector and give it to the neural network. The neural network runs it, applies several processing stages to it, and then gets an output. In an attention model, you have a neural network, but you run the neural network for much longer. There is a mechanism in the neural network, which decides which part of the input it wants to “look” at. Normally, if the input is very large, you need a large neural network to process it. But if you have an attention model, you can decide on the best size of the neural network, independent of the size of the input. Say you have a sentence, a sequence of, say, 100 words. The attention model will issue a query on the input sentence and create a distribution over the input words, such that a word that is more similar to the query will have higher probability, and words that are less similar to the query will have lower probability. Then you take the weighted average of them. Since every step is differentiable, we can train the attention model where to look with backpropagation, which is the reason for its appeal and success. Differentiable attention is computationally expensive because it requires accessing your entire input at each step of the model’s operation. And this is fine when the input is a sentence that’s only, say, 100 words, but it’s not practical when the input is a 10,000-word document. So, one of the main issues is speed. Attention should be fast, but differentiable attention is not fast. Reinforcement learning of attention is potentially faster, but training attentional control using reinforcement learning over thousands of objects would be non-trivial."
(Ilya Sutskever)
"The ability to focus on one thing and ignore others has a vital role in guiding cognition. Not only does this allow us to pick out salient information from noisy data (the cocktail party problem) it also allows us to pursue one thought at a time, remember one event rather than all events."
"Even with no explicit attention mechanism, neural networks learn a form of implicit attention where they respond more strongly to some parts of the data than others. Implicit attention is great, but there are still reasons to favour an explicit attention mechanism that limits the data presented to the network in some way:
- computational efficiency
- scalability (e.g. fixed size glimpse for any size image)
- don't have to learn to ignore things
- sequential processing of static data (e.g. gaze moving around image)"
types of attention:
- positional
- associative
hard (stochastic variables, learned via reinforcement) vs soft (continuous variables, learned via backpropagation) attention models:
- if you care about variables (want to read off the attention) then make them hard (optimization is quicker with hard decisions, randomization helps with better initializations for attention)
- if you don't care (just part of the process to get end result) then make them soft (inference is computationally easier than with graphical models of stochastic variables, determenistic attention prevents exploration)
soft attention models:
- computationally expensive (they had to examine every image location, hard to scale to large datasets)
- deterministic (can be trained by backprop)
hard attention models:
- computationally more efficient (the need to process only small part of each image frame)
- stochastic (require some form of sampling because they must make discrete choices)
"Deep Learning and Reasoning, Memory-Augmented Networks" by Rob Fergus video
"Reasoning, Attention and Memory" by Sumit Chopra video
"Beyond Seq2Seq with Augmented RNNs" by Edward Grefenstette video
"Attention and Augmented Recurrent Neural Networks" by Chris Olah and Shan Carter
"Neural Abstract Machines & Program Induction" workshop at NIPS 2016 (videos)
- Pointer Networks
- Grid LSTM
- Neural GPU
- Memory Networks
- Neural Stacks/Queues
- Neural Turing Machine
- Differentiable Neural Computer
"The main theoretical benefit of Neural Turing Machine and related architectures is that they decouple the number of model parameters from the memory size."
"In principle, this should allow the model to generalize over problem instance sizes different than those seen during training, something that humans can do but LSTMs (or other types of RNNs) can't do."
"For instance, if you show a human examples of string reversal up to length 5, they will infer the underlying algorithm and they will be able to reverse length 10 strings, or even much longer strings if they have access to paper and pencil (an external memory)."
"LSTMs can't do that: each model has a finite memory capacity fixed as a hyperparameter before training, and even if you give the model excess capacity, it still will not easily generalize over different instance sizes. Each element of the state vector has a finite number of bits and it is controlled by a set of parameters independent from those of any other element of the state vector, which means that if the model learns an algorithm that operates on a subset of bits of the state vectors, it will not generalize to a larger number of bits."
"Imagine coding in a programming language that has only fixed-size variables, with no pointers or any other form of indirect addressing and no recursion. Not only this language would be non-Turing-complete, but it would be also pretty inconvenient to code: if you write a program to reverse length 5 strings, it will not work on any other length. But that's what LSTMs are pretty much stuck with."
"In fact, it is even worse when you consider training sample complexity: the number of parameters of a LSTM grows quadratically with its state size, which means that even in a good training regime (sample complexity proportional to parameter number), the number of examples required to learn how to reverse a string will grow quadratically with the string length, even if it is essentially the same algorithm."
"In order to address this issue you need some kind of addressable memory (either location-based or content-based) or recursion or some way to build composable data structures such as linked lists. NTMs provide addressable memory in a very low-level way, while a hypothetical differentiable functional programming language would possibly provide recursion and/or composable data structures."
"Right now NTMs seem to learn with difficulty on toy algorithmic tasks, and have not been demonstrated on real-world tasks. I suppose that the main issue is optimization hardness, which might be addressed by better optimization algorithms and better hardware, as it has been the case with NNs in general."
"It could be also the case that many "real-world" experimental benchmarks that have been tried so far are not very "algorithmic", hence NTMs don't have an advantage over LSTMs, but experimental conditions where training and test examples are i.i.d. sampled from the same distribution are actually somewhat artificial, thus in more realistic applications the NTMs may benefit from an increased generalization ability. In any case, if the end goal is to reach at least human-level learning performance, being able to do this kind of generalization seems necessary."
(Antonio Valerio Miceli-Barone)
"The idea of distributed representations was introduced with reference to cognitive representations: a mental object can be represented efficiently (both in terms of number of bits and in terms of number of examples needed to generalize about it) by characterizing the object using many features, each of which can separately each be active or inactive. For example, with m binary features, one can describe up to 2^m different objects. The idea is that the brain would be learning and using such representations because they help it generalize to new objects that are similar to known ones in many respects. A distributed representation is opposed to a local representation, in which only one neuron (or very few) is active at each time, i.e., as with grandmother cells. One can view n-gram models as a mostly local representation: only the units associated with the specific subsequences of the input sequence are turned on. Hence the number of units needed to capture the possible sequences of interest grows exponentially with sequence length."
(Yoshua Bengio)
"Representation Learning" chapter of "Deep Learning" book by Goodfellow, Bengio, Courville
"Visualizing Representations" by Chris Colah
"We are attempting to replace symbols by vectors so we can replace logic by algebra."
(Yann LeCun)
"Aetherial Symbols" by Geoffrey Hinton slides
- words are the symbolic indicators of thought vectors
- words carry with each a probabilistic stream of potential further thoughts and links to past symbols
- much like implicit CFD, they are backward convolved with prior words to determine most likely hidden thought, and then forward solved to determine next word
- further, these streams are described with formal logic relationships based on the identities of the included words which can have levels of "meta-identity" (ie: I can't know some pair are brother and sister without having having been given the idea of bros/sis pairs or seen others)
- knowledge of more or varied relationships (and more logic paths) provides more efficient/accurate ways to solve an optimized path through the higher dimensions of word/symbol space
- in a sense, one may never know the idea of "bros/sis" but it is probabilistically highly likely that given a male and female with the same parents that they are also brothers/sisters
"Deep Meaning Beyond Thought Vectors" by David McAllester
distributed representation of natural language
neural architectures for reasoning
continuous space embeddings of words, sentences, texts, relational graphs
- approximate objects/relations/categories
- built in-similarity function
- generative function for relations/categories (no need to name everything)
- map objects (images, sentences, DNA sequences, commands, or combinations of these) to points in metric spaces (embeddings)
- combinatorial optimization problems becomes easier in metric spaces when casted as continuous optimization problems
- embeddings are efficient/flexible features and provide extra knowledge for many practical tasks
- embeddings can be decoded to produce structured outputs (parsing, sequential decision making, translation)
- distributed representations have exponential power and further gains arise from the use of layers (composition)
- embeddings can be learned with supervised or unsupervised training and can be learned for multiple tasks jointly
- scalable and parallelizable training with stochastic gradient descent using similarity ranking loss or log-likelihood loss
- more data and bigger the models, the more impressive the results
limitations:
- fixed capacity: one has to choose a dimension before training and it determines the capacity of the representation, then one can't increase it as more data comes in without retraining the whole thing from the scratch
- partial lack of interpretability: distributed representations are black boxes - they may preserve some semantic relations as vector algebraic properties, but one can't generally easily extract arbitrary information from them without a specifically trained neural network
open questions:
- should words/sentences/entities/relations/facts be vectors or matrices, or tensors, or distributions over them?
- better compression? improve memory capacity of embeddings and allow for one-shot learning of new symbols
- do we need non-linearities? most supervised problems are mostly tackled well by linear models
- can we fit the meaning of a sentence into a “single *&!**^ing vector”?
- what is the sentence space?
- are the sentence vectors contextual?
- how to compose words into sentences, entities and relations into facts? (addition, tensor product, inner products, ...)
- function words, logical operators, quantification, inference, ...?
- composing in other modalities (images, videos, ...)?
- what type of inferences do embeddings support?
- what is a proof in embeddings?
- how can explicit background knowledge be injected into embeddings?
- theory
- gradient estimation
- bayesian deep learning
- generative adversarial networks
- variational autoencoder
- autoregressive models
- architectures
- connections to neuroscience
- applications
"Understanding Deep Learning Requires Rethinking Generalization" Zhang, Bengio, Hardt, Recht, Vinyals
generalization
"Despite their massive size, successful deep artificial neural networks can exhibit a remarkably small difference between training and test performance. Conventional wisdom attributes small generalization error either to properties of the model family, or to the regularization techniques used during training. Through extensive systematic experiments, we show how these traditional approaches fail to explain why large neural networks generalize well in practice. Specifically, our experiments establish that state-of-the-art convolutional networks for image classification trained with stochastic gradient methods easily fit a random labeling of the training data. This phenomenon is qualitatively unaffected by explicit regularization, and occurs even if we replace the true images by completely unstructured random noise. We corroborate these experimental findings with a theoretical construction showing that simple depth two neural networks already have perfect finite sample expressivity as soon as the number of parameters exceeds the number of data points as it usually does in practice. We interpret our experimental findings by comparison with traditional models."
"1. The effective capacity of neural networks is large enough for a brute-force memorization of the entire data set.
2. Even optimization on random labels remains easy. In fact, training time increases only by a small constant factor compared with training on the true labels.
3. Randomizing labels is solely a data transformation, leaving all other properties of the learning problem unchanged."
"It is likely that learning in the traditional sense still occurs in part, but it appears to be deeply intertwined with massive memorization. Classical approaches are therefore poorly suited for reasoning about why these models generalize well.""Deep Learning networks are just massive associative memory stores! Deep Learning networks are capable of good generalization even when fitting random data. This is indeed strange in that many arguments for the validity of Deep Learning is on the conjecture that ‘natural’ data tends to exists in a very narrow manifold in multi-dimensional space. Random data however does not have that sort of tendency."
"Large, unregularized deep nets outperform shallower nets with regularization."
"SOTA models can fit arbitrary label patterns, even on large data-sets like ImageNet."
"Popular models can fit structureless noise."
"In the case of one-pass SGD, where each training point is only visited at most once, the algorithm is essentially optimizing the expected loss directly. Therefore, there is no need to define generalization. However, in practice, unless one has access to infinite training samples, one-pass SGD is rarely used. Instead, it is almost always better to run many passes of SGD over the same training set. In this case, the algorithm is optimizing the empirical loss, and the deviation between the empirical loss and the expected loss (i.e. the generalization error) needs to be controlled. In statistical learning theory, the deviation is typically controlled by restricting the complexity of the hypothesis space. For example, in binary classification, for a hypothesis space with VC-dimension d and n i.i.d. training samples, the generalization error could be upper bounded by O(sqrt(d/n)). In the distribution-free setting, the VC dimension also provide a lower bound for the generalization error. For example, if we are highly over-parameterized, i.e. d >> n, then there is a data distribution under which the generalization error could be arbitrarily bad. This worst case behavior is recently demonstrated by a randomization test on large neural networks that have the full capability of shattering the whole training set. In those experiments, zero-error minimizers for the empirical loss are found by SGD. Since the test performance could be only at the level of chance, the worst possible generalization error is observed. On the other hand, those same networks are found to generalize very well on natural image classification datasets, achieving the state-of-the-art performance on some standard benchmarks. This create a puzzle as our traditional characterization of generalization no longer readily apply in this scenario."
"You might assume that if you can fit each point in a random training set you would have bad generalization performance because because if your model class can do this then all of the standard learning theory bounds for generalization error are quite dire. VC theory gives generalization bounds in terms of the maximum number of points where you can achieve zero training error for every possible labelling (they call this "shattering"). Rademacher complexity gives tighter bounds, but they are in terms of the expected error of the model class over uniform random labellings of your data (the expectation is over the randomness in the random labels). If you model class is powerful enough to fit any arbitrary labelling of your data set then both of these theories give no guarantees at all about generalization error. They can't guarantee you will ever make a single correct prediction, even with infinite test samples. Obviously, experience says otherwise. Neural nets tend to generalize pretty well (often surprisingly well) in spite of the dire predictions of learning theory. That's why this result requires "rethinking generalization"; the stuff we know about generalization doesn't explain any of the success we see in practice."
videohttps://facebook.com/iclr.cc/videos/1710657292296663?t=1105 (Recht)videohttps://facebook.com/iclr.cc/videos/1710657292296663?t=3220 (Zhang)noteshttps://theneuralperspective.com/2017/01/24/understanding-deep-learning-requires-rethinking-generalization/noteshttps://blog.acolyer.org/2017/05/11/understanding-deep-learning-requires-re-thinking-generalization/noteshttps://reddit.com/r/MachineLearning/comments/6ailoh/r_understanding_deep_learning_requires_rethinking/dhis1hz/posthttp://www.offconvex.org/2017/12/08/generalization1/ (Arora)
"Sharp Minima Can Generalize For Deep Nets" Dinh, Pascanu, Bengio, Bengio
generalization
"Despite their overwhelming capacity to overfit, deep learning architectures tend to generalize relatively well to unseen data, allowing them to be deployed in practice. However, explaining why this is the case is still an open area of research. One standing hypothesis that is gaining popularity, e.g. Hochreiter & Schmidhuber (1997); Keskar et al. (2017), is that the flatness of minima of the loss function found by stochastic gradient based methods results in good generalization. This paper argues that most notions of flatness are problematic for deep models and can not be directly applied to explain generalization. Specifically, when focusing on deep networks with rectifier units, we can exploit the particular geometry of parameter space induced by the inherent symmetries that these architectures exhibit to build equivalent models corresponding to arbitrarily sharper minima. Furthermore, if we allow to reparametrize a function, the geometry of its parameters can change drastically without affecting its generalization properties."
videohttps://vimeo.com/237275513 (Dinh)
"A Closer Look at Memorization in Deep Networks" Arpit et al.
generalization
"We examine the role of memorization in deep learning, drawing connections to capacity, generalization, and adversarial robustness. While deep networks are capable of memorizing noise data, our results suggest that they tend to prioritize learning simple patterns first. In our experiments, we expose qualitative differences in gradient-based optimization of deep neural networks on noise vs. real data. We also demonstrate that for appropriately tuned explicit regularization (e.g., dropout) we can degrade DNN training performance on noise datasets without compromising generalization on real data. Our analysis suggests that the notions of effective capacity which are dataset independent are unlikely to explain the generalization performance of deep networks when trained with gradient based methods because training data itself plays an important role in determining the degree of memorization."
videohttps://vimeo.com/238241921 (Krueger)videohttp://videocrm.ca/Machine18/Machine18-20180423-5-YoshuaBengio.mp4 (42:27) (Bengio)
"Deep Learning and the Information Bottleneck Principle" Tishby, Zaslavsky
generalization
"Deep Neural Networks are analyzed via the theoretical framework of the information bottleneck principle. We first show that any DNN can be quantified by the mutual information between the layers and the input and output variables. Using this representation we can calculate the optimal information theoretic limits of the DNN and obtain finite sample generalization bounds. The advantage of getting closer to the theoretical limit is quantifiable both by the generalization bound and by the network’s simplicity. We argue that both the optimal architecture, number of layers and features/connections at each layer, are related to the bifurcation points of the information bottleneck tradeoff, namely, relevant compression of the input layer with respect to the output layer. The hierarchical representations at the layered network naturally correspond to the structural phase transitions along the information curve. We believe that this new insight can lead to new optimality bounds and deep learning algorithms."
"In this work we express this important insight using information theoretic concepts and formulate the goal of deep learning as an information theoretic tradeoff between compression and prediction. We first argue that the goal of any supervised learning is to capture and efficiently represent the relevant information in the input variable about the output - label - variable. Namely, to extract an approximate minimal sufficient statistics of the input with respect to the output. The information theoretic interpretation of minimal sufficient statistics suggests a principled way of doing that: find a maximally compressed mapping of the input variable that preserves as much as possible the information on the output variable. This is precisely the goal of the Information Bottleneck method."
"Several interesting issues arise when applying this principle to DNNs. First, the layered structure of the network generates a successive Markov chain of intermediate representations, which together form the (approximate) sufficient statistics. This is closely related to successive refinement of information in Rate Distortion Theory. Each layer in the network can now be quantified by the amount of information it retains on the input variable, on the (desired) output variable, as well as on the predicted output of the network. The Markovian structure and data processing inequalities enable us to examine the efficiency of the internal representations of the network’s hidden layers, which is not possible with other distortion/error measures. It also provides us with the information theoretic limits of the compression/prediction problem and theoretically quantify each proposed DNN for the given training data. In addition, this representation of DNNs gives a new theoretical sample complexity bound, using the known finite sample bounds on the IB."
"Another outcome of this representation is a possible explanation of the layered architecture of the network. Neurons, as non-linear (e.g. sigmoidal) functions of a dot-product of their input, can only capture linearly separable properties of their input layer. Linear separability is possible when the input layer units are close to conditional independence, given the output classification. This is generally not true for the data distribution and intermediate hidden layer are required. We suggest here that the break down of the linear-separability is associated with a representational phase transition (bifurcation) in the IB optimal curve, as both result from the second order dependencies in the data. Our analysis suggests new information theoretic optimality conditions, sample complexity bounds, and design principle for DNN models."
"We suggest a novel information theoretic analysis of deep neural networks based on the information bottleneck principle. Arguably, DNNs learn to extract efficient representations of the relevant features of the input layer X for predicting the output label Y, given a finite sample of the joint distribution p(X, Y). This representation can be compared with the theoretically optimal relevant compression of the variable X with respect to Y, provided by the information bottleneck (or information distortion) tradeoff. This is done by introducing a new information theoretic view of DNN training as an successive (Markovian) relevant compression of the input variable X, given the empirical training data. The DNN’s prediction is activating the trained compression layered hierarchy to generate a predicted label Yˆ. Maximizing the mutual information I(Y; Yˆ), for a sequence of evoking inputs X, emerges as the natural DNN optimization goal."
- https://en.wikipedia.org/wiki/Information_bottleneck_method
videohttps://youtube.com/watch?v=ei59sYLVuqA (Tishby)posthttp://inference.vc/representation-learning-and-compression-with-the-information-bottleneck/paper"The Information Bottleneck Method" by Tishby, Pereira, Bialek
"Opening the Black Box of Deep Neural Networks via Information" Shwartz-Ziv, Tishby
generalization
"Despite their great success, there is still no comprehensive theoretical understanding of learning with Deep Neural Networks or their inner organization. Previous work [Tishby & Zaslavsky (2015)] proposed to analyze DNNs in the Information Plane; i.e., the plane of the Mutual Information values that each layer preserves on the input and output variables. They suggested that the goal of the network is to optimize the Information Bottleneck tradeoff between compression and prediction, successively, for each layer. In this work we follow up on this idea and demonstrate the effectiveness of the Information-Plane visualization of DNNs. We first show that the stochastic gradient descent epochs have two distinct phases: fast empirical error minimization followed by slow representation compression, for each layer. We then argue that the DNN layers end up very close to the IB theoretical bound, and present a new theoretical argument for the computational benefit of the hidden layers."
"Our numerical experiments were motivated by the Information Bottleneck framework. We demonstrated that the visualization of the layers in the information plane reveals many - so far unknown - details about the inner working of Deep Learning and Deep Neural Networks. They revealed the distinct phases of the SGD optimization, drift and diffusion, which explain the ERM and the representation compression trajectories of the layers. The stochasticity of SGD methods is usually motivated as a way of escaping local minima of the training error. In this paper we give it a new, perhaps much more important role: it generates highly efficient internal representations through compression by diffusion. This is consistent with other recent suggestions on the role of noise in Deep Learning."
"We also argue that SGD seems an overkill during the diffusion phase, which consumes most of the training epochs, and that much simpler optimization algorithms, such as Monte-Carlo relaxations, can be more efficient. But the IB framework may provide even more. If the layers actually converge to the IB theoretical bounds, there is an analytic connection between the encoder and decoder distributions for each layer, which can be exploited during training. Combining the IB iterations with stochastic relaxation methods may significantly boost DNN training. To conclude, it seems fair to say, based on our experiments and analysis, that Deep Learning with DNN are in essence learning algorithms that effectively find efficient representations that are approximate minimal sufficient statistics in the IB sense."
"If our findings hold for general networks and tasks, the compression phase of the SGD and the convergence of the layers to the IB bound can explain the phenomenal success of Deep Learning."
"DNNs with SGD have two phases: error minimization, then representation compression"
" The Information Plane provides a unique visualization of DL:
- Most of the learning time goes to compression
- Layers are learnt bottom up - and "help" each other
- Layers converge to special (critical?) points on the IB bound
The advantage of the layers is mostly computational:
- Relaxation times are super-linear (exponential?) in the Entropy gap
- Hidden layers provide intermediate steps and boost convergence time
- Hidden layers help in avoiding critical slowing down
"
"We gave two independent theoretical arguments on why compression of representation dramatically improves generalization, and how stochastic relaxation, due to either noise of the SGD, OR a noisy training energy surface effectively adds noise also to BGD push the weights distribution to a Gibbs measure in the training error (this is an old argument we use in our statistical mechanics of learning papers 25 years ago, and is used today by many others, e.g. Tommy Poggio). Then we show that this weight Gibbs distribution leads directly (essentially through Bayes rule) to the IB optimal encoder of the layers."
"We also showed some of newer simulations, which include much larger and different problems (MNIST, Cifar-10, different architectures, CNN, etc.), including ReLU non-linearities and linear Networks. In all these networks we see essentially the same picture: the last hidden layer first improves generalization error (which is actually proved to be directly bounded by the mutual information on Y) by fitting the training data and adding more information on the inputs, and then further improve generalization by compressing the representation and “forget” the irrelevant details of the inputs. During both these phases of learning the information on the relevant components of the input increases monotonically. You can of course have compression without generalization, when the training size is too small and one can’t keep the homogeneity of the cover."
"We also showed that there are clearly and directly two phases of the gradients distribution. First, high SNR gradients follow by a sharp flip to low SNR gradients, which correspond to the slow saturation of the training error. This clear gradients phase transition, which we see with all types of non-linearities and architectures, beautifully corresponds to the “knee” between memorization and compression in the information plane. This can easily be explained as done by Poggio in his theory 3 paper, or by more complicated calculations by Riccardo Zecchina and his coworkers using statistical mechanics."
"For representation Z, maximizing mutual information with the output while minimizing mutual information with the input."
"The general result is that networks go through two phases of learning. In retrospect, this is kind of obvious to anyone that's trained neural networks in practice. There is typically a short phase where it makes rapid progress, followed by a much longer phase of "fine tuning". The real contribution of this paper is showing that these stages correspond to a phase change in how the mutual information of the encoder/decoder distributions of each layer change. The first stage is when each layer is learning to do its fair share of information preservation. During this stage, mutual information between each layer's representation and the input/output increases to the point that the network's representation in the information plane is more or less linear. All this means is that information loss/gain from layer to layer is approximately constant, so in a sense no layer is doing more work than others. The second phase consists of continuing to maximizing the mutual information between each layer and the output, but now at the expense of the mutual information between each layer and the input. This is in contrast to the first stage where both quantities were being maximized in. In other words, each layer is now learning to prioritize information that is important for the task at hand."
"Authors describe SGD as having two distinct phases, a drift phase and a diffusion phase. SGD begins in the first phase, basically exploring the multidimensional space of solutions. When it begins converging, it arrives at the diffusion phase where it is extremely chaotic and the convergence rate slows to a crawl. An intuition of what’s happening in this phase is that the network is learning to compress. That is, the behavior makes a phase transition from high mean with low variance to one with a low mean but high variance. This provides further explanation to Smith et. al’s observations, that in the region near convergence, it is highly chaotic. This of course does not fully explain why a high learning rate will knock the system into a place of high loss."
"Consider the gradient of the loss with respect to the weights.
Phase 1 (drift): Mean gradient size is much larger than the standard deviation.
Phase 2 (diffusion): Mean gradient is smaller and noise takes over - Langevin/Boltzmann effect kicks in.
Authors claim that SGD training compresses (reduces I(X;T)) in the diffusion phase."
- https://en.wikipedia.org/wiki/Information_bottleneck_method
videohttps://youtube.com/watch?v=XL07WEc2TRI (Tishby)videohttps://youtube.com/watch?v=EQTtBRM0sIs (Tishby)videohttps://youtube.com/watch?v=bLqJHjXihK8 (Tishby)videohttps://youtube.com/watch?v=ekUWO_pI2M8 (Tishby)videohttps://youtu.be/RKvS958AqGY?t=12m7s (Tishby)videohttps://youtu.be/cHjI37DsQCQ?t=41m40s (Selvaraj)posthttps://lilianweng.github.io/lil-log/2017/09/28/anatomize-deep-learning-with-information-theory.htmlposthttps://weberna.github.io/jekyll/update/2017/11/08/Information-Bottleneck-Part1.htmlposthttp://inference.vc/representation-learning-and-compression-with-the-information-bottleneck/posthttps://medium.com/intuitionmachine/the-peculiar-behavior-of-deep-learning-loss-surfaces-330cb741ec17noteshttps://blog.acolyer.org/2017/11/15/opening-the-black-box-of-deep-neural-networks-via-information-part-i/noteshttps://blog.acolyer.org/2017/11/16/opening-the-black-box-of-deep-neural-networks-via-information-part-ii/noteshttps://theneuralperspective.com/2017/03/24/opening-the-black-box-of-deep-neural-networks-via-information/noteshttps://reddit.com/r/MachineLearning/comments/60fhyb/r_opening_the_black_box_of_deep_neural_networks/df8jsbm/presshttps://quantamagazine.org/new-theory-cracks-open-the-black-box-of-deep-learning-20170921paper"Deep Learning and the Information Bottleneck Principle" by Tishby and Zaslavskysummary
"Deep Variational Information Bottleneck" Alemi, Fischer, Dillon, Murphy
generalization information bottleneck
"The Information Bottleneck principle is appealing, since it defines what we mean by a good representation, in terms of the fundamental tradeoff between having a concise representation and one with good predictive power. The main drawback of the IB principle is that computing mutual information is, in general, computationally challenging. We propose to use variational inference to construct a lower bound on the IB objective. By using the reparameterization trick, we can use Monte Carlo sampling to get an unbiased estimate of the gradient, and hence we can optimize the objective using stochastic gradient descent. This allows us to use deep neural networks to parameterize our distributions, and thus to handle high-dimensional, continuous data, such as images, avoiding the previous restrictions to the discrete or Gaussian cases." "Stochastic neural networks, fit using our VIB method, are robust to overfitting, since VIB finds a representation Z which ignores as many details of the input X as possible. In addition, they are more robust to adversarial inputs than deterministic models which are fit using (penalized) maximum likelihood estimation. Intuitively this is because each input image gets mapped to a distribution rather than a unique Z, so it is more difficult to pass small, idiosyncratic perturbations through the latent bottleneck."
- https://en.wikipedia.org/wiki/Information_bottleneck_method
codehttps://github.com/alexalemi/vib_democodehttps://github.com/1Konny/VIB-pytorch
generalization information bottleneck
"We have presented bounds, some of which tight, that connect the amount of information in the weights, the amount of information in the activations, the invariance property of the network, and the geometry of the residual loss."
"This leads to the somewhat surprising result that reducing information stored in the weights about the past (dataset) results in desirable properties of the representation of future data (test datum)."
"We conducted experiments to validate the assumptions underlying these bounds, and found that the results match the qualitative behavior observed on real data and architectures. In particular, the theory predicts a verifiable phase transition between an underfitting and overfitting regime for random labels, and the amount of information in nats needed to cross the transition."
"We show that in a deep neural network invariance to nuisance factors is equivalent to information minimality of the learned representation, and that stacking layers and injecting noise during training naturally bias the network towards learning invariant representations. We then show that, in order to avoid memorization, we need to limit the quantity of information stored in the weights, which leads to a novel usage of the Information Bottleneck Lagrangian on the weights as a learning criterion."
"Information Bottleneck principle: minimize mutual information of the representation with the training data."
- https://en.wikipedia.org/wiki/Information_bottleneck_method
videohttps://youtube.com/watch?v=Wgvcxd98tvU (Achille)videohttps://youtube.com/watch?v=BCSoRTMYQcw (Achille)videohttps://youtube.com/watch?v=zbg49SMP5kY (Soatto)
"Intriguing Properties of Neural Networks" Szegedy, Zaremba, Sutskever, Bruna, Erhan, Goodfellow, Fergus
generalization
"Deep neural networks are highly expressive models that have recently achieved state of the art performance on speech and visual recognition tasks. While their expressiveness is the reason they succeed, it also causes them to learn uninterpretable solutions that could have counter-intuitive properties. In this paper we report two such properties. First, we find that there is no distinction between individual high level units and random linear combinations of high level units, according to various methods of unit analysis. It suggests that it is the space, rather than the individual units, that contains the semantic information in the high layers of neural networks. Second, we find that deep neural networks learn input-output mappings that are fairly discontinuous to a significant extent. We can cause the network to misclassify an image by applying a certain hardly perceptible perturbation, which is found by maximizing the network’s prediction error. In addition, the specific nature of these perturbations is not a random artifact of learning: the same perturbation can cause a different network, that was trained on a different subset of the dataset, to misclassify the same input."
- http://deeplearning.twbbs.org (demo)
videohttp://youtube.com/watch?v=pdODJ7JQfjo (Zaremba)posthttp://i-programmer.info/news/105-artificial-intelligence/7352-the-flaw-lurking-in-every-deep-neural-net.htmlcodehttps://github.com/tensorflow/cleverhanscodehttps://github.com/bethgelab/foolbox
"Explaining and Harnessing Adversarial Examples" Goodfellow, Shlens, Szegedy
generalization
"Several machine learning models, including neural networks, consistently misclassify adversarial examples - inputs formed by applying small but intentionally worst-case perturbations to examples from the dataset, such that the perturbed input results in the model outputting an incorrect answer with high confidence. Early attempts at explaining this phenomenon focused on nonlinearity and overfitting. We argue instead that the primary cause of neural networks’ vulnerability to adversarial perturbation is their linear nature. This explanation is supported by new quantitative results while giving the first explanation of the most intriguing fact about them: their generalization across architectures and training sets. Moreover, this view yields a simple and fast method of generating adversarial examples. Using this approach to provide examples for adversarial training, we reduce the test set error of a maxout network on the MNIST dataset."
"The criticism of deep networks as vulnerable to adversarial examples is misguided, because unlike shallow linear models, deep networks are at least able to represent functions that resist adversarial perturbation.
"Adversarial examples can be explained as a property of high-dimensional dot products. They are a result of models being too linear, rather than too nonlinear.
The generalization of adversarial examples across different models can be explained as a result of adversarial perturbations being highly aligned with the weight vectors of a model, and different models learning similar functions when trained to perform the same task.
The direction of perturbation, rather than the specific point in space, matters most. Space is not full of pockets of adversarial examples that finely tile the reals like the rational numbers.
Because it is the direction that matters most, adversarial perturbations generalize across different clean examples.
Adversarial training can result in regularization; even further regularization than dropout.
Models that are easy to optimize are easy to perturb.
Fooling examples are ubiquitous and easily generated.
RBF networks are resistant to adversarial examples.
Linear models lack the capacity to resist adversarial perturbation; only structures with a hidden layer (where the universal approximator theorem applies) should be trained to resist adversarial perturbation.
Models trained to model the input distribution are not resistant to adversarial examples.
Ensembles are not resistant to adversarial examples.
Shallow linear models are not resistant to fooling examples."
"Competence of CNNs is relatively limited to a small region around the data manifold that contains natural-looking images and distributions, and that once we artificially push images away from this manifold by computing noise patterns with backpropagation, we stumble into parts of image space where all bets are off, and where the linear functions in the network induce large subspaces of fooling inputs. With wishful thinking, one might hope that ConvNets would produce all-diffuse probabilities in regions outside the training data, but there is no part in an ordinary objective (e.g. mean cross-entropy loss) that explicitly enforces this constraint. Indeed, it seems that the class scores in these regions of space are all over the place, and worse, a straight-forward attempt to patch this up by introducing a background class and iteratively adding fooling images as a new background class during training are not effective in mitigating the problem. It seems that to fix this problem we need to change our objectives, our forward functional forms, or even the way we optimize our models."
"Neural nets turn out to be much more linear as a function of their input than we expected (more precisely, neural nets are piecewise linear, and the linear pieces with non-negligible slope are much bigger than we expected). On a continuum from "linear function" to "incomprehensibly complicated nonlinear function", neural nets as they are used in practice are usually much further toward the left end of the continuum than most people think."
"ReLUs have 2 states: on and off. They're linear when they're on and they're constant 0 when they're off. Now consider an input x. There is some neighbourhood around x where you don't change the states of any ReLU unit in the network. In that neighbourhood, the network behaves exactly as a linear (affine, when you consider biases) function. That's what is meant by linear: as you move around in x space, you hit different on/off configurations of the units, each which is a locally affine function."
Yoshua Bengio:
"My conjecture is that good unsupervised learning should generally be much more robust to adversarial distortions because it tries to discriminate the data manifold from its surroundings, in ALL non-manifold directions (at every point on the manifold). This is in contrast with supervised learning, which only needs to worry about the directions that discriminate between the observed classes. Because the number of classes is much less than the dimensionality of the space, for image data, supervised learning is therefore highly underconstrained, leaving many directions of changed "unchecked" (i.e. to which the model is either insensitive when it should not or too sensitive in the wrong way)."
videohttp://youtube.com/watch?v=Pq4A2mPCB0Y (Goodfellow)videohttp://youtube.com/watch?v=hDlHpBBGaKs (Goodfellow)videohttp://videolectures.net/deeplearning2015_goodfellow_adversarial_examples/ (Goodfellow)noteshttp://www.shortscience.org/paper?bibtexKey=journals/corr/1412.6572posthttps://karpathy.github.io/2015/03/30/breaking-convnets/posthttp://kdnuggets.com/2015/07/deep-learning-adversarial-examples-misconceptions.htmlcodehttps://github.com/tensorflow/cleverhanscodehttps://github.com/bethgelab/foolbox
"Distilling the Knowledge in a Neural Network" Hinton, Vinyals, Dean
generalization
"A very simple way to improve the performance of almost any machine learning algorithm is to train many different models on the same data and then to average their predictions. Unfortunately, making predictions using a whole ensemble of models is cumbersome and may be too computationally expensive to allow deployment to a large number of users, especially if the individual models are large neural nets. Caruana and his collaborators have shown that it is possible to compress the knowledge in an ensemble into a single model which is much easier to deploy and we develop this approach further using a different compression technique. We achieve some surprising results on MNIST and we show that we can significantly improve the acoustic model of a heavily used commercial system by distilling the knowledge in an ensemble of models into a single model. We also introduce a new type of ensemble composed of one or more full models and many specialist models which learn to distinguish fine-grained classes that the full models confuse. Unlike a mixture of experts, these specialist models can be trained rapidly and in parallel."
"How can we produce neural nets that learn good representations without as much training data or parameters?"
"A simple way to improve classification performance is to average the predictions of a large ensemble of different classifiers. This is great for winning competitions but requires too much computation at test time for practical applications such as speech recognition. In a widely ignored paper in 2006, Caruana and his collaborators showed that the knowledge in the ensemble could be transferred to a single, efficient model by training the single model to mimic the log probabilities of the ensemble average. This technique works because most of the knowledge in the learned ensemble is in the relative probabilities of extremely improbable wrong answers. For example, the ensemble may give a BMW a probability of one in a billion of being a garbage truck but this is still far greater (in the log domain) than its probability of being a carrot. This "dark knowledge", which is practically invisible in the class probabilities, defines a similarity metric over the classes that makes it much easier to learn a good classifier. I will describe a new variation of this technique called "distillation" and will show some surprising examples in which good classifiers over all of the classes can be learned from data in which some of the classes are entirely absent, provided the targets come from an ensemble that has been trained on all of the classes. I will also show how this technique can be used to improve a state-of-the-art acoustic model and will discuss its application to learning large sets of specialist models without overfitting."
"Train a large network on the original training labels, then learn a much smaller “distilled” model on a weighted combination of the original labels and the (softened) softmax output of the larger model. The authors show that the distilled model has better generalization ability than a model trained on just the labels."
videohttps://youtube.com/watch?v=EK61htlw8hY (Hinton)videohttp://videolectures.net/deeplearning2017_larochelle_neural_networks/ (part 2, 1:28:45) (Larochelle)paper"Distilling a Neural Network Into a Soft Decision Tree" by Frosst, Hinton
generalization
"Deep CNNs are known to exhibit the following peculiarity: on the one hand they generalize extremely well to a test set, while on the other hand they are extremely sensitive to so-called adversarial perturbations. The extreme sensitivity of high performance CNNs to adversarial examples casts serious doubt that these networks are learning high level abstractions in the dataset. We are concerned with the following question: How can a deep CNN that does not learn any high level semantics of the dataset manage to generalize so well?"
"The goal of this article is to measure the tendency of CNNs to learn surface statistical regularities of the dataset. To this end, we use Fourier filtering to construct datasets which share the exact same high level abstractions but exhibit qualitatively different surface statistical regularities. For the SVHN and CIFAR-10 datasets, we present two Fourier filtered variants: a low frequency variant and a randomly filtered variant. Each of the Fourier filtering schemes is tuned to preserve the recognizability of the objects. Our main finding is that CNNs exhibit a tendency to latch onto the Fourier image statistics of the training dataset, sometimes exhibiting up to a 28% generalization gap across the various test sets. Moreover, we observe that significantly increasing the depth of a network has a very marginal impact on closing the aforementioned generalization gap. Thus we provide quantitative evidence supporting the hypothesis that deep CNNs tend to learn surface statistical regularities in the dataset rather than higher-level abstract concepts."
"Deep Image Prior" Ulyanov, Vedaldi, Lempitsky
generalization
"Deep convolutional networks have become a popular tool for image generation and restoration. Generally, their excellent performance is imputed to their ability to learn realistic image priors from a large number of example images. In this paper, we show that, on the contrary, the structure of a generator network is sufficient to capture a great deal of low-level image statistics prior to any learning. In order to do so, we show that a randomly-initialized neural network can be used as a handcrafted prior with excellent results in standard inverse problems such as denoising, superresolution, and inpainting. Furthermore, the same prior can be used to invert deep neural representations to diagnose them, and to restore images based on flash-no flash input pairs."
- https://dmitryulyanov.github.io/deep_image_prior
videohttps://youtube.com/watch?v=fj0yLTa_bmA (Ulyanov)codehttps://github.com/DmitryUlyanov/deep-image-prior
"Train Faster, Generalize Better: Stability of Stochastic Gradient Descent" Hardt, Recht, Singer
generalization optimization
"We show that parametric models trained by a stochastic gradient method with few iterations have vanishing generalization error. We prove our results by arguing that SGM is algorithmically stable in the sense of Bousquet and Elisseeff. Our analysis only employs elementary tools from convex and continuous optimization. We derive stability bounds for both convex and non-convex optimization under standard Lipschitz and smoothness assumptions. Applying our results to the convex case, we provide new insights for why multiple epochs of stochastic gradient methods generalize well in practice. In the non-convex case, we give a new interpretation of common practices in neural networks, and formally show that popular techniques for training large deep models are indeed stability-promoting. Our findings conceptually underscore the importance of reducing training time beyond its obvious benefit."
videohttp://techtalks.tv/talks/train-faster-generalize-better-stability-of-stochastic-gradient-descent/62637/ (Recht)posthttp://argmin.net/2016/04/18/bottoming-out/ (Recht)posthttp://www.offconvex.org/2016/03/14/stability/ (Hardt)posthttp://www.offconvex.org/2016/03/22/saddlepoints/ (Ge)posthttp://www.offconvex.org/2016/03/24/saddles-again/ (Recht)
"Identifying and Attacking the Saddle Point Problem in High-dimensional Non-convex Optimization" Dauphin, Pascanu, Gulcehre, Cho, Ganguli, Bengio
optimization
"A central challenge to many fields of science and engineering involves minimizing non-convex error functions over continuous, high dimensional spaces. Gradient descent or quasi-Newton methods are almost ubiquitously used to perform such minimizations, and it is often thought that a main source of difficulty for these local methods to find the global minimum is the proliferation of local minima with much higher error than the global minimum. Here we argue, based on results from statistical physics, random matrix theory, neural network theory, and empirical evidence, that a deeper and more profound difficulty originates from the proliferation of saddle points, not local minima, especially in high dimensional problems of practical interest. Such saddle points are surrounded by high error plateaus that can dramatically slow down learning, and give the illusory impression of the existence of a local minimum. Motivated by these arguments, we propose a new approach to second-order optimization, the saddle-free Newton method, that can rapidly escape high dimensional saddle points, unlike gradient descent and quasi-Newton methods. We apply this algorithm to deep or recurrent neural network training, and provide numerical evidence for its superior optimization performance."
"In summary, we have drawn from disparate literatures spanning statistical physics and random matrix theory to neural network theory, to argue that (a) non-convex error surfaces in high dimensional spaces generically suffer from a proliferation of saddle points, and (b) in contrast to conventional wisdom derived from low dimensional intuition, local minima with high error are exponentially rare in high dimensions. Moreover, we have provided the first experimental tests of these theories by performing new measurements of the statistical properties of critical points in neural network error surfaces. These tests were enabled by a novel application of Newton’s method to search for critical points of any index (fraction of negative eigenvalues), and they confirmed the main qualitative prediction of theory that the index of a critical point tightly and positively correlates with its error level."
"It is often the case that our geometric intuition, derived from experience within a low dimensional physical world, is inadequate for thinking about the geometry of typical error surfaces in high-dimensional spaces. To illustrate this, consider minimizing a randomly chosen error function of a single scalar variable, given by a single draw of a Gaussian process. (Rasmussen and Williams, 2005) have shown that such a random error function would have many local minima and maxima, with high probability over the choice of the function, but saddles would occur with negligible probability. On the other-hand, as we review below, typical, random Gaussian error functions over N scalar variables, or dimensions, are increasingly likely to have saddle points rather than local minima as N increases. Indeed the ratio of the number of saddle points to local minima increases exponentially with the dimensionality N."
"A typical problem for both local minima and saddle-points is that they are often surrounded by plateaus of small curvature in the error. While gradient descent dynamics are repelled away from a saddle point to lower error by following directions of negative curvature, this repulsion can occur slowly due to the plateau. Second order methods, like the Newton method, are designed to rapidly descend plateaus surrounding local minima by rescaling gradient steps by the inverse eigenvalues of the Hessian matrix. However, the Newton method does not treat saddle points appropriately; as argued below, saddle-points instead become attractive under the Newton dynamics. Thus, given the proliferation of saddle points, not local minima, in high dimensional problems, the entire theoretical justification for quasi-Newton methods, i.e. the ability to rapidly descend to the bottom of a convex local minimum, becomes less relevant in high dimensional non-convex optimization."
videohttp://videocrm.ca/Machine18/Machine18-20180423-5-YoshuaBengio.mp4 (32:31) (Bengio)videohttp://videolectures.net/deeplearning2017_larochelle_neural_networks/ (part 2, 1:16:54) (Larochelle)
"Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift" Ioffe, Szegedy
optimization
"Training Deep Neural Networks is complicated by the fact that the distribution of each layer’s inputs changes during training, as the parameters of the previous layers change. This slows down the training by requiring lower learning rates and careful parameter initialization, and makes it notoriously hard to train models with saturating nonlinearities. We refer to this phenomenon as internal covariate shift, and address the problem by normalizing layer inputs. Our method draws its strength from making normalization a part of the model architecture and performing the normalization for each training mini-batch. Batch Normalization allows us to use much higher learning rates and be less careful about initialization, and in some cases eliminates the need for Dropout. Applied to a stateof-the-art image classification model, Batch Normalization achieves the same accuracy with 14 times fewer training steps, and beats the original model by a significant margin. Using an ensemble of batch-normalized networks, we improve upon the best published result on ImageNet classification: reaching 4.82% top-5 test error, exceeding the accuracy of human raters."
"We have presented a novel mechanism for dramatically accelerating the training of deep networks. It is based on the premise that covariate shift, which is known to complicate the training of machine learning systems, also applies to sub-networks and layers, and removing it from internal activations of the network may aid in training. Our proposed method draws its power from normalizing activations, and from incorporating this normalization in the network architecture itself. This ensures that the normalization is appropriately handled by any optimization method that is being used to train the network. To enable stochastic optimization methods commonly used in deep network training, we perform the normalization for each mini-batch, and backpropagate the gradients through the normalization parameters. Batch Normalization adds only two extra parameters per activation, and in doing so preserves the representation ability of the network. We presented an algorithm for constructing, training, and performing inference with batch-normalized networks. The resulting networks can be trained with saturating nonlinearities, are more tolerant to increased training rates, and often do not require Dropout for regularization. Merely adding Batch Normalization to a state-of-the-art image classification model yields a substantial speedup in training. By further increasing the learning rates, removing Dropout, and applying other modifications afforded by Batch Normalization, we reach the previous state of the art with only a small fraction of training steps - and then beat the state of the art in single-network image classification. Furthermore, by combining multiple models trained with Batch Normalization, we perform better than the best known system on ImageNet, by a significant margin."
"In this work, we have not explored the full range of possibilities that Batch Normalization potentially enables. Our future work includes applications of our method to Recurrent Neural Networks, where the internal covariate shift and the vanishing or exploding gradients may be especially severe, and which would allow us to more thoroughly test the hypothesis that normalization improves gradient propagation. More study is needed of the regularization properties of Batch Normalization, which we believe to be responsible for the improvements we have observed when Dropout is removed from BN-Inception. We plan to investigate whether Batch Normalization can help with domain adaptation, in its traditional sense - i.e. whether the normalization performed by the network would allow it to more easily generalize to new data distributions, perhaps with just a recomputation of the population means and variances. Finally, we believe that further theoretical analysis of the algorithm would allow still more improvements and applications."
"We have found that removing Dropout from BN-Inception allows the network to achieve higher validation accuracy. We conjecture that Batch Normalization provides similar regularization benefits as Dropout, since the activations observed for a training example are affected by the random selection of examples in the same mini-batch."
"Batch norm is similar to dropout in the sense that it multiplies each hidden unit by a random value at each step of training. In this case, the random value is the standard deviation of all the hidden units in the minibatch. Because different examples are randomly chosen for inclusion in the minibatch at each step, the standard deviation randomly fluctuates. Batch norm also subtracts a random value (the mean of the minibatch) from each hidden unit at each step. Both of these sources of noise mean that every layer has to learn to be robust to a lot of variation in its input, just like with dropout."
videohttp://research.microsoft.com/apps/video/default.aspx?id=260019 (Ioffe)videohttp://videolectures.net/icml2015_ioffe_batch_normalization/ (Ioffe)videohttps://youtu.be/Xogn6veSyxA?t=3m46s (Goodfellow)videohttps://youtube.com/watch?v=-1yfr_YBzX4 (Lykov)in russianposthttps://kratzert.github.io/2016/02/12/understanding-the-gradient-flow-through-the-batch-normalization-layer.htmlposthttps://kevinzakka.github.io/2016/09/14/batch_normalization/noteshttp://www.shortscience.org/paper?bibtexKey=conf/icml/IoffeS15paper"How Does Batch Normalization Help Optimization (No, It Is Not About Internal Covariate Shift)" by Santurkar et al.
"Self-Normalizing Neural Networks" Klambauer, Unterthiner, Mayr, Hochreiter
optimization
"Deep Learning has revolutionized vision via convolutional neural networks (CNNs) and natural language processing via recurrent neural networks (RNNs). However, success stories of Deep Learning with standard feed-forward neural networks (FNNs) are rare. FNNs that perform well are typically shallow and, therefore cannot exploit many levels of abstract representations. We introduce self-normalizing neural networks (SNNs) to enable high-level abstract representations. While batch normalization requires explicit normalization, neuron activations of SNNs automatically converge towards zero mean and unit variance. The activation function of SNNs are "scaled exponential linear units" (SELUs), which induce self-normalizing properties. Using the Banach fixed-point theorem, we prove that activations close to zero mean and unit variance that are propagated through many network layers will converge towards zero mean and unit variance -- even under the presence of noise and perturbations. This convergence property of SNNs allows to (1) train deep networks with many layers, (2) employ strong regularization, and (3) to make learning highly robust. Furthermore, for activations not close to unit variance, we prove an upper and lower bound on the variance, thus, vanishing and exploding gradients are impossible. We compared SNNs on (a) 121 tasks from the UCI machine learning repository, on (b) drug discovery benchmarks, and on (c) astronomy tasks with standard FNNs and other machine learning methods such as random forests and support vector machines. SNNs significantly outperformed all competing FNN methods at 121 UCI tasks, outperformed all competing methods at the Tox21 dataset, and set a new record at an astronomy data set. The winning SNN architectures are often very deep."
"Weights are initialized in such a way that for any unit in a layer with input weights wi Σ wi = 0 and Σ wi^2 = 1." "selu(x) = λx for x>0 and selu(x) = λ(αe^x − α) for x≤0, where α≈1.6733 and λ≈1.0507"
videohttps://facebook.com/nipsfoundation/videos/1555553784535855?t=2824 (Klambauer)videohttps://youtube.com/watch?v=h6eQrkkU9SA (Hochreiter)videohttps://youtu.be/NZEAqdepq0w?t=34m3s (Hochreiter)videohttps://youtube.com/watch?v=gH-KWepKSNs (Klambauer)noteshttp://www.shortscience.org/paper?bibtexKey=journals/corr/1706.02515noteshttps://bayesgroup.github.io/sufficient-statistics/posts/self-normalizing-neural-networks/in russiancodehttp://github.com/bioinf-jku/SNNs
"Measuring the Intrinsic Dimension of Objective Landscapes" Li, Farkhoor, Liu, Yosinski
interpretability
"Many recently trained neural networks employ large numbers of parameters to achieve good performance. One may intuitively use the number of parameters required as a rough gauge of the difficulty of a problem. But how accurate are such notions? How many parameters are really needed? In this paper we attempt to answer this question by training networks not in their native parameter space, but instead in a smaller, randomly oriented subspace. We slowly increase the dimension of this subspace, note at which dimension solutions first appear, and define this to be the intrinsic dimension of the objective landscape. The approach is simple to implement, computationally tractable, and produces several suggestive conclusions. Many problems have smaller intrinsic dimensions than one might suspect, and the intrinsic dimension for a given dataset varies little across a family of models with vastly different sizes. This latter result has the profound implication that once a parameter space is large enough to solve a problem, extra parameters serve directly to increase the dimensionality of the solution manifold. Intrinsic dimension allows some quantitative comparison of problem difficulty across supervised, reinforcement, and other types of learning where we conclude, for example, that solving the inverted pendulum problem is 100 times easier than classifying digits from MNIST, and playing Atari Pong from pixels is about as hard as classifying CIFAR-10."
- https://eng.uber.com/intrinsic-dimension
videohttps://youtube.com/watch?v=uSZWeRADTFIcodehttps://github.com/uber-research/intrinsic-dimension
"On Calibration of Modern Neural Networks" Guo, Pleiss, Sun, Weinberger
interpretability
"Confidence calibration - the problem of predicting probability estimates representative of the true correctness likelihood - is important for classification models in many applications. We discover that modern neural networks, unlike those from a decade ago, are poorly calibrated. Through extensive experiments, we observe that depth, width, weight decay, and Batch Normalization are important factors influencing calibration. We evaluate the performance of various post-processing calibration methods on state-of-the-art architectures with image and document classification datasets. Our analysis and experiments not only offer insights into neural network learning, but also provide a simple and straightforward recipe for practical settings: on most datasets, temperature scaling - a single-parameter variant of Platt Scaling - is surprisingly effective at calibrating predictions."
"A network should provide a calibrated confidence measure in addition to its prediction. In other words, the probability associated with the predicted class label should reflect its ground truth correctness likelihood. Calibrated confidence estimates are also important for model interpretability. Good confidence estimates provide a valuable extra bit of information to establish trustworthiness with the user - especially for neural networks, whose classification decisions are often difficult to interpret. Further, good probability estimates can be used to incorporate neural networks into other probabilistic models."
videohttps://vimeo.com/238242536 (Pleiss)
interpretability
"How can we explain the predictions of a black-box model? In this paper, we use influence functions -- a classic technique from robust statistics -- to trace a model's prediction through the learning algorithm and back to its training data, thereby identifying training points most responsible for a given prediction. To scale up influence functions to modern machine learning settings, we develop a simple, efficient implementation that requires only oracle access to gradients and Hessian-vector products. We show that even on non-convex and non-differentiable models where the theory breaks down, approximations to influence functions can still provide valuable information. On linear models and convolutional neural networks, we demonstrate that influence functions are useful for multiple purposes: understanding model behavior, debugging models, detecting dataset errors, and even creating visually-indistinguishable training-set attacks."
"We use influence functions, a classic technique from robust statistics, to trace a model's prediction through the learning algorithm and back to its training data, thereby identifying training points most responsible for a given prediction."
"We show that even on non-convex and non-differentiable models where the theory breaks down, approximations to influence functions can still provide valuable information."
"On linear models and convolutional neural networks, we demonstrate that influence functions are useful for multiple purposes: understanding model behavior, debugging models, detecting dataset errors, and even creating visually-indistinguishable training-set attacks."
videohttps://youtube.com/watch?v=0w9fLX_T6tY (Koh)videohttps://vimeo.com/237274831 (Koh)videohttps://facebook.com/academics/videos/1633085090076225?t=5008 (Liang)videohttps://youtube.com/watch?v=dk6UsEzfKdU (Matushkin)in russiancodehttps://github.com/kohpangwei/influence-releasecodehttps://github.com/darkonhub/darkon
"Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation" Bengio, Leonard, Courville
gradient estimation straight-through estimator
"Stochastic neurons and hard non-linearities can be useful for a number of reasons in deep learning models, but in many cases they pose a challenging problem: how to estimate the gradient of a loss function with respect to the input of such stochastic or non-smooth neurons? I.e., can we “back-propagate” through these stochastic neurons? We examine this question, existing approaches, and compare four families of solutions, applicable in different settings. One of them is the minimum variance unbiased gradient estimator for stochatic binary neurons (a special case of the REINFORCE algorithm). A second approach, introduced here, decomposes the operation of a binary stochastic neuron into a stochastic binary part and a smooth differentiable part, which approximates the expected effect of the pure stochatic binary neuron to first order. A third approach involves the injection of additive or multiplicative noise in a computational graph that is otherwise differentiable. A fourth approach heuristically copies the gradient with respect to the stochastic output directly as an estimator of the gradient with respect to the sigmoid argument (we call this the straight-through estimator). To explore a context where these estimators are useful, we consider a small-scale version of conditional computation, where sparse stochastic units form a distributed representation of gaters that can turn off in combinatorially many ways large chunks of the computation performed in the rest of the neural network. In this case, it is important that the gating units produce an actual 0 most of the time. The resulting sparsity can be potentially be exploited to greatly reduce the computational cost of large deep networks for which conditional computation would be useful."
videohttp://videocrm.ca/Machine18/Machine18-20180423-5-YoshuaBengio.mp4 (14:35) (Bengio)videohttps://youtu.be/_JTu50iDhkA?t=1h21m53s (Sobolev)
"Gradient Estimation Using Stochastic Computation Graphs" Schulman, Heess, Weber, Abbeel
gradient estimation
"In a variety of problems originating in supervised, unsupervised, and reinforcement learning, the loss function is defined by an expectation over a collection of random variables, which might be part of a probabilistic model or the external world. Estimating the gradient of this loss function, using samples, lies at the core of gradient-based learning algorithms for these problems. We introduce the formalism of stochastic computation graphs---directed acyclic graphs that include both deterministic functions and conditional probability distributions---and describe how to easily and automatically derive an unbiased estimator of the loss function's gradient. The resulting algorithm for computing the gradient estimator is a simple modification of the standard backpropagation algorithm. The generic scheme we propose unifies estimators derived in variety of prior work, along with variance-reduction techniques therein. It could assist researchers in developing intricate models involving a combination of stochastic and deterministic operations, enabling, for example, attention, memory, and control actions."
"We have developed a framework for describing a computation with stochastic and deterministic operations, called a stochastic computation graph. Given a stochastic computation graph, we can automatically obtain a gradient estimator, given that the graph satisfies the appropriate conditions on differentiability of the functions at its nodes. The gradient can be computed efficiently in a backwards traversal through the graph: one approach is to apply the standard backpropagation algorithm to one of the surrogate loss functions; another approach (which is roughly equivalent) is to apply a modified backpropagation procedure. The results we have presented are sufficiently general to automatically reproduce a variety of gradient estimators that have been derived in prior work in reinforcement learning and probabilistic modeling. We hope that this work will facilitate further development of interesting and expressive models."
"Can mix and match likelihood ratio and path derivative. If black-box node: might need to place stochastic node in front of it and use likelihood ratio. This includes recurrent neural net policies."
videohttps://youtube.com/watch?v=jmMsNQ2eug4 (Schulman)videohttp://videolectures.net/deeplearning2016_abbeel_deep_reinforcement/#t=3724 (Abbeel)videohttps://facebook.com/icml.imls/videos/429607650887089?t=281 (Foerster)noteshttps://yobibyte.github.io/files/paper_notes/scg.pdfpaper"Optimizing Expectations: From Deep Reinforcement Learning to Stochastic Computation Graphs" by Schulman
"MuProp: Unbiased Backpropagation for Stochastic Neural Networks" Gu, Levine, Sutskever, Mnih
gradient estimation MuProp
"Deep neural networks are powerful parametric models that can be trained efficiently using the backpropagation algorithm. Stochastic neural networks combine the power of large parametric functions with that of graphical models, which makes it possible to learn very complex distributions. However, as backpropagation is not directly applicable to stochastic networks that include discrete sampling operations within their computational graph, training such networks remains difficult. We present MuProp, an unbiased gradient estimator for stochastic networks, designed to make this task easier. MuProp improves on the likelihood-ratio estimator by reducing its variance using a control variate based on the first-order Taylor expansion of a mean-field network. Crucially, unlike prior attempts at using backpropagation for training stochastic networks, the resulting estimator is unbiased and well behaved. Our experiments on structured output prediction and discrete latent variable modeling demonstrate that MuProp yields consistently good performance across a range of difficult tasks."
"In this paper, we presented MuProp, which is an unbiased estimator of derivatives in stochastic computational graphs that combines the statistical efficiency of backpropagation with the correctness of a likelihood ratio method. MuProp has a number of natural extensions. First, we might consider using other functions for the baseline rather than just the Taylor expansion, which could be learned in a manner that resembles Q-learning and target propagation. In reinforcement learning, fitted Q-functions obtained by estimating the expected return of a given policy πθ summarize all future costs, and a good Q-function can greatly simplify the temporal credit assignment problem. Combining MuProp with such fitted Q-functions could greatly reduce the variance of the estimator and make it better suited for very deep computational graphs, such as long recurrent neural networks and applications in reinforcement learning. The second extension is to make x¯ depend on samples of its parent nodes. This could substantially improve performance on deeper networks, where the value from a singletrunk mean-field pass may diverge significantly from any samples drawn with a fully stochastic pass. By drawing x¯ using mean-field passes originating at sampled values from preceding layers would prevent such divergence, though at additional computational cost, since the number of mean-field passes would depend on the depth n of the network, for a total of O(n^2) partial passes through the network. Intuitively, the single mean-field “chain” would turn into a “tree,” with a sampled trunk and a different mean-field branch at each layer."
"The versatility of stochastic neural networks motivates research into more effective algorithms for training them. Models with continuous latent variables and simple approximate posteriors can already be trained efficiently using the variational lower bound along with the reparameterization trick, which makes it possible to train both the model and the inference network using backpropagation. Training models with discrete latent variable distributions, such as Bernoulli or multinomial, is considerably more difficult. Unbiased estimators based on the likelihood-ratio method tend to be significantly less effective than biased estimators, such as the straight-through method and the estimator proposed by Gregor et al. (2014). We hypothesize that this is due to the fact that, unlike the biased estimators, the unbiased ones do not take advantage of the gradient information provided by the backpropagation algorithm. However, the biased estimators are heuristic and not well understood, which means that it is difficult to enumerate the situations in which these estimators will work well. We posit that an effective method for training stochastic neural networks should take advantage of the highly efficient backpropagation algorithm, while still providing the convergence guarantees of an unbiased estimator."
"To that end, we derive MuProp, an unbiased gradient estimator for deep stochastic neural networks that is based on backpropagation. To the best of our knowledge, it is the first unbiased estimator that can handle both continuous and discrete stochastic variables while taking advantage of analytic gradient information. MuProp’s simple and general formulation allows a straightforward derivation of unbiased gradient estimators for arbitrary stochastic computational graphs – directed acyclic graph with a mix of stochastic and deterministic computational nodes. While the algorithm is applicable to both continuous and discrete distributions, we used only discrete models in our experiments, since the reparameterization trick already provides an effective method for handling continuous variables. We present experimental results for training neural networks with discrete Bernoulli and multinomial variables for both supervised and unsupervised learning tasks. With these models, which are notoriously difficult to train, biased methods often significantly outperform the unbiased ones, except in certain cases. Our results indicate that MuProp’s performance is more consistent and often superior to that of the competing estimators. It is the first time that a well-grounded, unbiased estimator consistently performs as well or better than the biased gradient estimators across a range of difficult tasks."
videohttps://youtu.be/hkRBoiaplEE?t=27m53s (Sobolev)videohttps://youtu.be/_XRBlhzb31U?t=25m19s (Figurnov)in russiannoteshttp://dustintran.com/blog/muprop-unbiased-backpropagation-for-stochastic-neural-networks/noteshttp://www.shortscience.org/paper?bibtexKey=journals/corr/GuLSM15codehttps://github.com/tensorflow/models/tree/master/research/rebar
variables with mixture distributions
"The ability to backpropagate stochastic gradients through continuous latent distributions has been crucial to the emergence of variational autoencoders and stochastic gradient variational Bayes. The key ingredient is an unbiased and low-variance way of estimating gradients with respect to distribution parameters from gradients evaluated at distribution samples. The "reparameterization trick" provides a class of transforms yielding such estimators for many continuous distributions, including the Gaussian and other members of the location-scale family. However the trick does not readily extend to mixture density models, due to the difficulty of reparameterizing the discrete distribution over mixture weights. This report describes an alternative transform, applicable to any continuous multivariate distribution with a differentiable density function from which samples can be drawn, and uses it to derive an unbiased estimator for mixture density weight derivatives. Combined with the reparameterization trick applied to the individual mixture components, this estimator makes it straightforward to train variational autoencoders with mixture-distributed latent variables, or to perform stochastic variational inference with a mixture density variational posterior."
videohttps://youtu.be/_JTu50iDhkA?t=21m54s (Sobolev)noteshttp://www.shortscience.org/paper?bibtexKey=journals/corr/1607.05690
"Reparameterization Gradients through Acceptance-Rejection Sampling Algorithms" Naesseth, Ruiz, Linderman, Blei
variables with complex distributions RSVI
"For many distributions of interest (such as the gamma or Dirichlet), simulation of random variables relies on acceptance-rejection sampling. The discontinuity introduced by the accept-reject step means that standard reparameterization tricks are not applicable. We propose a new method that lets us leverage reparameterization gradients even when variables are outputs of a acceptance-rejection sampling algorithm. Our approach enables reparameterization on a larger class of variational distributions."
videohttps://youtu.be/quIuMYSLaYM?t=17m21s (Ruiz)posthttps://casmls.github.io/general/2017/04/25/rsvi.htmlposthttp://artem.sobolev.name/posts/2017-09-10-stochastic-computation-graphs-continuous-case.html
"The Generalized Reparameterization Gradient" Ruiz, Titsias, Blei
variables with complex distributions
"The reparameterization gradient does not easily apply to commonly used distributions such as beta or gamma without further approximations, and most practical applications of the reparameterization gradient fit Gaussian distributions. We introduce the generalized reparameterization gradient, a method that extends the reparameterization gradient to a wider class of variational distributions. Generalized reparameterizations use invertible transformations of the latent variables which lead to transformed distributions that weakly depend on the variational parameters. This results in new Monte Carlo gradients that combine reparameterization gradients and score function gradients."
"Reparametrization removes dependence on parameters completely. What if we remove it just partially?"
videohttps://youtu.be/_JTu50iDhkA?t=29m20s (Sobolev)videohttps://youtu.be/mrj_hyH974o?t=1h23m40s (Vetrov)in russianposthttp://artem.sobolev.name/posts/2017-09-10-stochastic-computation-graphs-continuous-case.html
"The Concrete Distribution: A Continuous Relaxation of Discrete Random Variables" Maddison, Mnih, Teh
"Categorical Reparametrization with Gumbel-Softmax" Jang, Gu, Poole
variables with discrete distributions
"Continuous reparemetrisation based on the so-called Concrete or Gumbel-softmax distribution, which is a continuous distribution and has a temperature constant that can be annealed during training to converge to a discrete distribution in the limit. In the beginning of training the variance of the gradients is low but biased, and towards the end of training the variance becomes high but unbiased."
"Doesn't close the performance gap of VAEs with continuous latent variables where one can use the Gaussian reparameterisation trick which benefits from much lower variance in the gradients."
videohttp://youtube.com/watch?v=JFgXEbgcT7g (Jang)videohttps://facebook.com/nipsfoundation/videos/1555493854541848?t=1513 (Teh)videohttps://youtu.be/_JTu50iDhkA?t=55m53s (Sobolev)videohttp://videocrm.ca/Machine18/Machine18-20180423-5-YoshuaBengio.mp4 (23:39) (Bengio)videohttps://youtu.be/_XRBlhzb31U?t=28m33s (Figurnov)in russianposthttps://laurent-dinh.github.io/2016/11/21/gumbel-max.htmlposthttps://casmls.github.io/general/2017/02/01/GumbelSoftmax.htmlposthttp://timvieira.github.io/blog/post/2014/07/31/gumbel-max-trick/posthttps://cmaddis.github.io/gumbel-machineryposthttps://hips.seas.harvard.edu/blog/2013/04/06/the-gumbel-max-trick-for-discrete-distributions/posthttps://blog.evjang.com/2016/11/tutorial-categorical-variational.htmlposthttp://artem.sobolev.name/posts/2017-10-28-stochastic-computation-graphs-discrete-relaxations.htmlcodehttps://github.com/ericjang/gumbel-softmax/blob/master/gumbel_softmax_vae_v2.ipynbcodehttps://gist.github.com/gngdb/ef1999ce3a8e0c5cc2ed35f488e19748codehttps://github.com/EderSantana/gumbel
"REBAR: Low-variance, Unbiased Gradient Estimates for Discrete Latent Variable Models" Tucker, Mnih, Maddison, Lawson, Sohl-Dickstein
variables with discrete distributions REBAR
"Learning in models with discrete latent variables is challenging due to high variance gradient estimators. Generally, approaches have relied on control variates to reduce the variance of the REINFORCE estimator. Recent work (Jang et al. 2016; Maddison et al. 2016) has taken a different approach, introducing a continuous relaxation of discrete variables to produce low-variance, but biased, gradient estimates. In this work, we combine the two approaches through a novel control variate that produces low-variance, unbiased gradient estimates. Then, we introduce a novel continuous relaxation and show that the tightness of the relaxation can be adapted online, removing it as a hyperparameter."
"Using continuous relaxation to construct a control variate for functions of discrete random variables. Low-variance estimates of the expectation of the control variate can be computed using the reparameterization trick to produce an unbiased estimator with lower variance than previous methods. Showing how to tune the free parameters of these relaxations to minimize the estimator’s variance during training."
"REBAR gives unbiased gradients with lower variance than REINFORCE - self-tuning and general."
"Estimators for gradient ∇φ E pθ(h)[f(h)] of expectation over discrete distribution pθ(h): unbiased (REINFORCE, NVIL, MuProp) and biased (Straight Through, 1/2 estimator, Concrete/Gumbel-Softmax)."
videohttps://youtube.com/watch?v=QODYgBhv_novideohttps://facebook.com/nipsfoundation/videos/1554402064651027?t=993 (Tucker)videohttps://youtu.be/hkRBoiaplEE?t=34m27s (Sobolev)codehttps://github.com/tensorflow/models/tree/master/research/rebarcodehttps://github.com/Bonnevie/rebar
"Backpropagation through the Void: Optimizing Control Variates for Black-box Gradient Estimation" Grathwohl, Choi, Wu, Roeder, Duvenaud
variables with discrete distributions non-differentiable loss RELAX
"Gradient-based optimization is the foundation of deep learning and reinforcement learning. Even when the mechanism being optimized is unknown or not differentiable, optimization using high-variance or biased gradient estimates is still often the best strategy. We introduce a general framework for learning low-variance, unbiased gradient estimators for black-box functions of random variables. Our method uses gradients of a neural network trained jointly with model parameters or policies, and is applicable in both discrete and continuous settings. We demonstrate this framework for training discrete latent-variable models. We also give an unbiased, action-conditional extension of the advantage actor-critic reinforcement learning algorithm."
"We generalize REBAR to learn a free-form control variate parameterized by a neural network, giving a lower-variance, unbiased gradient estimator which can be applied to a wider variety of problems with greater flexibility. Most notably, our method is applicable even when no continuous relaxation is available, as in reinforcement learning or black box function optimization. Furthermore, we derive improved variants of popular reinforcement learning methods with unbiased, action-dependent gradient estimates and lower variance."
"We would like a general gradient estimator that is:
- unbiased
- low variance
- usable when f(b) is unknown
- usable when p(b|theta) is discrete"
"RELAX doesn't solve the problem of discrete random variables but it solves the problem of how to estimate gradient of function which value is known but how to compute or differentiate it is unknown (reinforcement learning and other applications)."
videohttps://vimeo.com/252185804 (Grathwohl)videohttp://videocrm.ca/Machine18/Machine18-20180423-5-YoshuaBengio.mp4 (25:20) (Bengio)videohttps://youtu.be/hkRBoiaplEE?t=1h8m1s (Sobolev)codehttps://github.com/duvenaud/relaxcodehttps://github.com/Bonnevie/rebarpaper"Action-depedent Control Variates for Policy Optimization via Stein's Identity" by Liu et al. (talkvideo)
"DiCE: The Infinitely Differentiable Monte Carlo Estimator" Foerster, Farquhar, Al-Shedivat, Rocktaschel, Xing, Whiteson
"The score function estimator is widely used for estimating gradients of stochastic objectives in Stochastic Computation Graphs, e.g., in reinforcement learning and meta-learning. While deriving the first order gradient estimators by differentiating a surrogate loss (SL) objective is computationally and conceptually simple, using the same approach for higher order gradients is more challenging. Firstly, analytically deriving and implementing such estimators is laborious and not compliant with automatic differentiation. Secondly, repeatedly applying SL to construct new objectives for each order gradient involves increasingly cumbersome graph manipulations. Lastly, to match the first order gradient under differentiation, SL treats part of the cost as a fixed sample, which we show leads to missing and wrong terms for higher order gradient estimators. To address all these shortcomings in a unified way, we introduce DICE, which provides a single objective that can be differentiated repeatedly, generating correct gradient estimators of any order in SCGs. Unlike SL, DICE relies on automatic differentiation for performing the requisite graph manipulations. We verify the correctness of DICE both through a proof and through numerical evaluation of the DICE gradient estimates. We also use DICE to propose and evaluate a novel approach for multi-agent learning."
videohttps://facebook.com/icml.imls/videos/429607650887089?t=197 (Foerster)codehttps://github.com/tensorflow/probability/blob/master/tensorflow_probability/python/monte_carlo.pycodehttps://drive.google.com/drive/folders/1qjuLTdRbM5CoyNGEyaCJdFKJ9UEwhU28
interesting papers - variational autoencoder
interesting recent papers
interesting recent papers - variational autoencoders
interesting recent papers - unsupervised learning
interesting recent papers - model-based reinforcement learning
interesting recent papers - exploration and intrinsic motivation
"Composing Graphical Models with Neural Networks for Structured Representations and Fast Inference" Johnson, Duvenaud, Wiltschko, Datta, Adams
"We propose a general modeling and inference framework that combines the complementary strengths of probabilistic graphical models and deep learning methods. Our model family composes latent graphical models with neural network observation likelihoods. For inference, we use recognition networks to produce local evidence potentials, then combine them with the model distribution using efficient message-passing algorithms. All components are trained simultaneously with a single stochastic variational inference objective. We illustrate this framework by automatically segmenting and categorizing mouse behavior from raw depth video, and demonstrate several other example models."
"Each frame of the video is a depth image of a mouse in a particular pose, and so even though each image is encoded as 30 × 30 = 900 pixels, the data lie near a low-dimensional nonlinear manifold. A good generative model must not only learn this manifold but also represent many other salient aspects of the data. For example, from one frame to the next the corresponding manifold points should be close to one another, and in fact the trajectory along the manifold may follow very structured dynamics. To inform the structure of these dynamics, a natural class of hypotheses used in ethology and neurobiology is that the mouse’s behavior is composed of brief, reused actions, such as darts, rears, and grooming bouts. Therefore a natural representation would include discrete states with each state representing the simple dynamics of a particular primitive action, a representation that would be difficult to encode in an unsupervised recurrent neural network model. These two tasks, of learning the image manifold and learning a structured dynamics model, are complementary: we want to learn the image manifold not just as a set but in terms of manifold coordinates in which the structured dynamics model fits the data well. A similar modeling challenge arises in speech, where high-dimensional data lie near a low-dimensional manifold because they are generated by a physical system with relatively few degrees of freedom but also include the discrete latent dynamical structure of phonemes, words, and grammar."
"Our approach uses graphical models for representing structured probability distributions, and uses ideas from variational autoencoders for learning not only the nonlinear feature manifold but also bottom-up recognition networks to improve inference. Thus our method enables the combination of flexible deep learning feature models with structured Bayesian and even Bayesian nonparametric priors. Our approach yields a single variational inference objective in which all components of the model are learned simultaneously. Furthermore, we develop a scalable fitting algorithm that combines several advances in efficient inference, including stochastic variational inference, graphical model message passing, and backpropagation with the reparameterization trick."
videohttps://youtube.com/watch?v=btr1poCYIzwvideohttp://videolectures.net/deeplearning2017_johnson_graphical_models/ (Johnson)videohttps://youtube.com/watch?v=KcbfuUJ_a0A (Johnson)videohttps://youtube.com/watch?v=vnO3w8OgTE8 (Duvenaud)audiohttps://youtube.com/watch?v=P7zucOImw04 (Duvenaud)slideshttp://www.cs.toronto.edu/~duvenaud/courses/csc2541/slides/svae-slides.pdfnoteshttps://casmls.github.io/general/2016/12/11/SVAEandfLDS.htmlcodehttp://github.com/mattjj/svae
"One-Shot Generalization in Deep Generative Models" Rezende, Mohamed, Danihelka, Gregor, Wierstra
"Humans have an impressive ability to reason about new concepts and experiences from just a single example. In particular, humans have an ability for one-shot generalization: an ability to encounter a new concept, understand its structure, and then be able to generate compelling alternative variations of the concept. We develop machine learning systems with this important capacity by developing new deep generative models, models that combine the representational power of deep learning with the inferential power of Bayesian reasoning. We develop a class of sequential generative models that are built on the principles of feedback and attention. These two characteristics lead to generative models that are among the state-of-the art in density estimation and image generation. We demonstrate the one-shot generalization ability of our models using three tasks: unconditional sampling, generating new exemplars of a given concept, and generating new exemplars of a family of concepts. In all cases our models are able to generate compelling and diverse samples---having seen new examples just once---providing an important class of general-purpose models for one-shot machine learning."
videohttp://youtube.com/watch?v=TpmoQ_j3Jv4 (demo)videohttp://techtalks.tv/talks/one-shot-generalization-in-deep-generative-models/62365/videohttps://youtu.be/XpIDCzwNe78?t=43m (Bartunov)noteshttps://casmls.github.io/general/2017/02/08/oneshot.html
"Towards a Neural Statistician" Edwards, Storkey
"An efficient learner is one who reuses what they already know to tackle a new problem. For a machine learner, this means understanding the similarities amongst datasets. In order to do this, one must take seriously the idea of working with datasets, rather than datapoints, as the key objects to model. Towards this goal, we demonstrate an extension of a variational autoencoder that can learn a method for computing representations, or statistics, of datasets in an unsupervised fashion. The network is trained to produce statistics that encapsulate a generative model for each dataset. Hence the network enables efficient learning from new datasets for both unsupervised and supervised tasks. We show that we are able to learn statistics that can be used for: clustering datasets, transferring generative models to new datasets, selecting representative samples of datasets and classifying previously unseen classes."
"Our goal was to demonstrate that it is both possible and profitable to work at a level of abstraction of datasets rather than just datapoints. We have shown how it is possible to learn to represent datasets using a statistic network, and that these statistics enable highly flexible and efficient models that can do transfer learning, small shot classification, cluster distributions, summarize datasets and more. Avenues for future research are engineering, methodological and application based. In terms of engineering we believe that there are gains to be had by more thorough exploration of different (larger) architectures. In terms of methodology we want to look at: improved methods of representing uncertainty resulting from sample size; models explicitly designed trained for small-shot classification; supervised and semi-supervised approaches to classifiying either datasets or datapoints within the dataset. One advantage we have yet to explore is that by specifying classes implicitly in terms of sets, we can combine multiple data sources with potentially different labels, or multiple labels. We can also easily train on any unlabelled data because this corresponds to sets of size one. We also want to consider questions such as: What are desirable properties for statistics to have as representations? How can we enforce these? Can we use ideas from classical work on estimators? In terms of applications we are interested in applying this framework to learning embeddings of speakers for speech problems or customer embeddings in commercial problems."
"Potentially a more powerful alternative to Variational Autoencoder."
videohttp://techtalks.tv/talks/neural-statistician/63048/ (Edwards)videohttps://youtube.com/watch?v=29t1qc7IWro (Edwards)videohttps://youtu.be/XpIDCzwNe78?t=51m53s (Bartunov)noteshttp://www.shortscience.org/paper?bibtexKey=journals/corr/1606.02185
"Fast Epsilon-free Inference of Simulation Models with Bayesian Conditional Density Estimation" Papamakarios, Murray
"Many statistical models can be simulated forwards but have intractable likelihoods. Approximate Bayesian Computation (ABC) methods are used to infer properties of these models from data. Traditionally these methods approximate the posterior over parameters by conditioning on data being inside an Epsilon-ball around the observed data, which is only correct in the limit Epsilon→ 0. Monte Carlo methods can then draw samples from the approximate posterior to approximate predictions or error bars on parameters. These algorithms critically slow down as Epsilon→ 0, and in practice draw samples from a broader distribution than the posterior. We propose a new approach to likelihood-free inference based on Bayesian conditional density estimation. Preliminary inferences based on limited simulation data are used to guide later simulations. In some cases, learning an accurate parametric representation of the entire true posterior distribution requires fewer model simulations than Monte Carlo ABC methods need to produce a single sample from an approximate posterior."
"Conventional ABC algorithms such as the above suffer from three drawbacks. First, they only represent the parameter posterior as a set of (possibly weighted or correlated) samples. A sample-based representation easily gives estimates and error bars of individual parameters, and model predictions. However these computations are noisy, and it is not obvious how to perform some other computations using samples, such as combining posteriors from two separate analyses. Second, the parameter samples do not come from the correct Bayesian posterior, but from an approximation based on assuming a pseudo-observation that the data is within an Epsilon-ball centred on the data actually observed. Third, as the Epsilon-tolerance is reduced, it can become impractical to simulate the model enough times to match the observed data even once. When simulations are expensive to perform, good quality inference becomes impractical. In this paper, we propose an alternative approach to likelihood-free inference, which unlike conventional ABC does not suffer from the above three issues. Instead of returning a set of parameter samples from an approximate posterior, our approach learns a parametric approximation to the exact posterior, which can be made as accurate as required. Furthermore, we present a strategy for learning our parametric approximation by making efficient use of simulations from the model. We show experimentally that our approach is capable of closely approximating the exact posterior, while making efficient use of simulations compared to conventional ABC. Our approach is based on conditional density estimation using Bayesian neural networks, and draws upon advances in density estimation, stochastic variational inference, and recognition networks. To the best of our knowledge, this is the first work that applies such techniques to the field of likelihood-free inference."
videohttps://youtube.com/watch?v=926yqLgoedU (Murray)posthttp://dennisprangle.github.io/research/2016/06/07/bayesian-inference-by-neural-networks + http://dennisprangle.github.io/research/2016/06/07/bayesian-inference-by-neural-networks2codehttps://github.com/gpapamak/epsilon_free_inference
"Black-Box α-Divergence Minimization" Hernandez-Lobato, Li, Rowland, Hernandez-Lobato, Bui, Turner
"Black-box alpha is a new approximate inference method based on the minimization of α-divergences. BB-α scales to large datasets because it can be implemented using stochastic gradient descent. BB-α can be applied to complex probabilistic models with little effort since it only requires as input the likelihood function and its gradients. These gradients can be easily obtained using automatic differentiation. By changing the divergence parameter α, the method is able to interpolate between variational Bayes (VB) (α→ 0) and an algorithm similar to expectation propagation (EP) (α= 1). Experiments on probit regression and neural network regression and classification problems show that BB-α with non-standard settings of α, such as α= 0.5, usually produces better predictions than with α→ 0 (VB) or α= 1 (EP)." "We have proposed BB-α as a black-box inference algorithm to approximate power EP. This is done by considering the energy function used by power EP and constraining the form of the site approximations in this method. The proposed method locally minimizes the α-divergence that is a rich family of divergence measures between distributions including the Kullback-Leibler divergence. Such a method is guaranteed to converge under certain conditions, and can be implemented by optimizing an energy function without having to use inefficient double-loop algorithms. Scalability to large datasets can be achieved by using stochastic gradient descent with minibatches. Furthermore, a combination of a Monte Carlo approximation and automatic differentiation methods allows our technique to be applied in a straightforward manner to a wide range ofprobabilistic models with complex likelihood factors. Experiments with neural networks applied to small and large datasets demonstrate both the accuracy and the scalability of the proposed approach. The evaluations also indicate the optimal setting for α may vary for different tasks."
videohttp://techtalks.tv/talks/black-box-alpha-divergence-minimization/62506/ (Hernandez-Lobato)videohttps://youtube.com/watch?v=Ev-6s8b3QrI (Hernandez-Lobato)
"Variational Inference: A Review for Statisticians" Blei, Kucukelbir, McAuliffe
"One of the core problems of modern statistics is to approximate difficult-to-compute probability distributions. This problem is especially important in Bayesian statistics, which frames all inference about unknown quantities as a calculation about the posterior. In this paper, we review variational inference (VI), a method from machine learning that approximates probability distributions through optimization. VI has been used in myriad applications and tends to be faster than classical methods, such as Markov chain Monte Carlo sampling. The idea behind VI is to first posit a family of distributions and then to find the member of that family which is close to the target. Closeness is measured by Kullback-Leibler divergence. We review the ideas behind mean-field variational inference, discuss the special case of VI applied to exponential family models, present a full example with a Bayesian mixture of Gaussians, and derive a variant that uses stochastic optimization to scale up to massive data. We discuss modern research in VI and highlight important open problems. VI is powerful, but it is not yet well understood. Our hope in writing this paper is to catalyze statistical research on this widely-used class of algorithms."
"Variational Inference with Normalizing Flows" Rezende, Mohamed
"The choice of approximate posterior distribution is one of the core problems in variational inference. Most applications of variational inference employ simple families of posterior approximations in order to allow for efficient inference, focusing on mean-field or other simple structured approximations. This restriction has a significant impact on the quality of inferences made using variational methods. We introduce a new approach for specifying flexible, arbitrarily complex and scalable approximate posterior distributions. Our approximations are distributions constructed through a normalizing flow, whereby a simple initial density is transformed into a more complex one by applying a sequence of invertible transformations until a desired level of complexity is attained. We use this view of normalizing flows to develop categories of finite and infinitesimal flows and provide a unified view of approaches for constructing rich posterior approximations. We demonstrate that the theoretical advantages of having posteriors that better match the true posterior, combined with the scalability of amortized variational approaches, provides a clear improvement in performance and applicability of variational inference."
"We propose the specification of approximate posterior distributions using normalizing flows, a tool for constructing complex distributions by transforming a probability density through a series of invertible mappings. Inference with normalizing flows provides a tighter, modified variational lower bound with additional terms that only add terms with linear time complexity. We show that normalizing flows admit infinitesimal flows that allow us to specify a class of posterior approximations that in the asymptotic regime is able to recover the true posterior distribution, overcoming one oft-quoted limitation of variational inference. We present a unified view of related approaches for improved posterior approximation as the application of special types of normalizing flows. We show experimentally that the use of general normalizing flows systematically outperforms other competing approaches for posterior approximation."
"In this work we developed a simple approach for learning highly non-Gaussian posterior densities by learning transformations of simple densities to more complex ones through a normalizing flow. When combined with an amortized approach for variational inference using inference networks and efficient Monte Carlo gradient estimation, we are able to show clear improvements over simple approximations on different problems. Using this view of normalizing flows, we are able to provide a unified perspective of other closely related methods for flexible posterior estimation that points to a wide spectrum of approaches for designing more powerful posterior approximations with different statistical and computational tradeoffs. An important conclusion from the discussion in section 3 is that there exist classes of normalizing flows that allow us to create extremely rich posterior approximations for variational inference. With normalizing flows, we are able to show that in the asymptotic regime, the space of solutions is rich enough to contain the true posterior distribution. If we combine this with the local convergence and consistency results for maximum likelihood parameter estimation in certain classes of latent variables models, we see that we are now able overcome the objections to using variational inference as a competitive and default approach for statistical inference. Making such statements rigorous is an important line of future research. Normalizing flows allow us to control the complexity of the posterior at run-time by simply increasing the flow length of the sequence. The approach we presented considered normalizing flows based on simple transformations of the form (10) and (14). These are just two of the many maps that can be used, and alternative transforms can be designed for posterior approximations that may require other constraints, e.g., a restricted support. An important avenue of future research lies in describing the classes of transformations that allow for different characteristics of the posterior and that still allow for efficient, linear-time computation."
videohttps://channel9.msdn.com/Events/Neural-Information-Processing-Systems-Conference/Neural-Information-Processing-Systems-Conference-NIPS-2016/Variational-Inference-Foundations-and-Modern-Methods (1:05:06) (Mohamed)videohttps://youtu.be/JrO5fSskISY?t=1h2m19s (Mohamed)videohttps://cds.cern.ch/record/2302480 (38:20) (Rezende)videohttps://youtu.be/tqGEX_Ucu04?t=33m58s (Molchanov)in russianposthttps://casmls.github.io/general/2016/09/25/normalizing-flows.htmlposthttp://docs.pymc.io/notebooks/normalizing_flows_overview.htmlposthttp://blog.evjang.com/2018/01/nf1.htmlposthttp://akosiorek.github.io/ml/2018/04/03/norm_flows.htmlposthttps://ferrine.github.io/blog/2017/07/11/normalizing-flows-overviewnoteshttp://www.shortscience.org/paper?bibtexKey=journals/corr/1505.05770codehttps://github.com/pymc-devs/pymc3/blob/master/pymc3/variational/flows.py
"Probabilistic Backpropagation for Scalable Learning of Bayesian Neural Networks" Hernandez-Lobato, Adams
Expectation Propagation
"Large multilayer neural networks trained with backpropagation have recently achieved state-of-the-art results in a wide range of problems. However, using backprop for neural net learning still has some disadvantages, e.g., having to tune a large number of hyperparameters to the data, lack of calibrated probabilistic predictions, and a tendency to overfit the training data. In principle, the Bayesian approach to learning neural networks does not have these problems. However, existing Bayesian techniques lack scalability to large dataset and network sizes. In this work we present a novel scalable method for learning Bayesian neural networks, called probabilistic backpropagation. Similar to classical backpropagation, PBP works by computing a forward propagation of probabilities through the network and then doing a backward computation of gradients. A series of experiments on ten real-world datasets show that PBP is significantly faster than other techniques, while offering competitive predictive abilities. Our experiments also show that PBP provides accurate estimates of the posterior variance on the network weights."
videohttp://videolectures.net/icml2015_hernandez_lobato_bayesian_neural/ (Hernandez-Lobato)codehttps://github.com/HIPS/Probabilistic-Backpropagation
"Weight Uncertainty in Neural Networks" Blundell, Cornebise, Kavukcuoglu, Wierstra
Bayes by Backprop
"We introduce a new, efficient, principled and backpropagation-compatible algorithm for learning a probability distribution on the weights of a neural network, called Bayes by Backprop. It regularises the weights by minimising a compression cost, known as the variational free energy or the expected lower bound on the marginal likelihood. We show that this principled kind of regularisation yields comparable performance to dropout on MNIST classification. We then demonstrate how the learnt uncertainty in the weights can be used to improve generalisation in non-linear regression problems, and how this weight uncertainty can be used to drive the exploration-exploitation trade-off in reinforcement learning."
"Plain feedforward neural networks are prone to overfitting. When applied to supervised or reinforcement learning problems these networks are also often incapable of correctly assessing the uncertainty in the training data and so make overly confident decisions about the correct class, prediction or action. We shall address both of these concerns by using variational Bayesian learning to introduce uncertainty in the weights of the network. We call our algorithm Bayes by Backprop. We suggest at least three motivations for introducing uncertainty on the weights: 1) regularisation via a compression cost on the weights, 2) richer representations and predictions from cheap model averaging, and 3) exploration in simple reinforcement learning problems such as contextual bandits."
"Various regularisation schemes have been developed to prevent overfitting in neural networks such as early stopping, weight decay, and dropout. In this work, we introduce an efficient, principled algorithm for regularisation built upon Bayesian inference on the weights of the network. This leads to a simple approximate learning algorithm similar to backpropagation. We shall demonstrate how this uncertainty can improve predictive performance in regression problems by expressing uncertainty in regions with little or no data, how this uncertainty can lead to more systematic exploration than epsilon-greedy in contextual bandit tasks."
"All weights in our neural networks are represented by probability distributions over possible values, rather than having a single fixed value. Learnt representations and computations must therefore be robust under perturbation of the weights, but the amount of perturbation each weight exhibits is also learnt in a way that coherently explains variability in the training data. Thus instead of training a single network, the proposed method trains an ensemble of networks, where each network has its weights drawn from a shared, learnt probability distribution. Unlike other ensemble methods, our method typically only doubles the number of parameters yet trains an infinite ensemble using unbiased Monte Carlo estimates of the gradients."
"In general, exact Bayesian inference on the weights of a neural network is intractable as the number of parameters is very large and the functional form of a neural network does not lend itself to exact integration. Instead we take a variational approximation to exact Bayesian updates.""
"Uncertainty in the hidden units allows the expression of uncertainty about a particular observation, uncertainty in the weights is complementary in that it captures uncertainty about which neural network is appropriate, leading to regularisation of the weights and model averaging. This uncertainty can be used to drive exploration in contextual bandit problems using Thompson sampling Weights with greater uncertainty introduce more variability into the decisions made by the network, leading naturally to exploration. As more data are observed, the uncertainty can decrease, allowing the decisions made by the network to become more deterministic as the environment is better understood."
"We introduced a new algorithm for learning neural networks with uncertainty on the weights called Bayes by Backprop. It optimises a well-defined objective function to learn a distribution on the weights of a neural network. The algorithm achieves good results in several domains. When classifying MNIST digits, performance from Bayes by Backprop is comparable to that of dropout. We demonstrated on a simple non-linear regression problem that the uncertainty introduced allows the network to make more reasonable predictions about unseen data. Finally, for contextual bandits, we showed how Bayes by Backprop can automatically learn how to trade-off exploration and exploitation. Since Bayes by Backprop simply uses gradient updates, it can readily be scaled using multi-machine optimisation schemes such as asynchronous SGD."
videohttp://videolectures.net/icml2015_blundell_neural_network/ (Blundell)codehttps://github.com/tabacof/bayesian-nn-uncertaintycodehttps://github.com/blei-lab/edward/blob/master/examples/bayesian_nn.pycodehttps://github.com/ferrine/gelatocodehttps://gist.github.com/rocknrollnerd/c5af642cf217971d93f499e8f70fcb72
"Bayesian Dark Knowledge" Korattikara, Rathod, Murphy, Welling
"We consider the problem of Bayesian parameter estimation for deep neural networks, which is important in problem settings where we may have little data, and/or where we need accurate posterior predictive densities, e.g., for applications involving bandits or active learning. One simple approach to this is to use online Monte Carlo methods, such as SGLD (stochastic gradient Langevin dynamics). Unfortunately, such a method needs to store many copies of the parameters (which wastes memory), and needs to make predictions using many versions of the model (which wastes time). We describe a method for "distilling" a Monte Carlo approximation to the posterior predictive density into a more compact form, namely a single deep neural network. We compare to two very recent approaches to Bayesian neural networks, namely an approach based on expectation propagation [Hernandez-Lobato and Adams, 2015] and an approach based on variational Bayes [Blundell et al., 2015]. Our method performs better than both of these, is much simpler to implement, and uses less computation at test time."
videohttps://youtu.be/tqGEX_Ucu04?t=1h1m23s (Molchanov)in russian
"Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning" Gal, Ghahramani
"Deep learning has gained tremendous attention in applied machine learning. However such tools for regression and classification do not capture model uncertainty. Bayesian models offer a mathematically grounded framework to reason about model uncertainty, but usually come with a prohibitive computational cost. We show that dropout in neural networks can be cast as a Bayesian approximation. As a direct result we obtain tools to model uncertainty with dropout NNs - extracting information from existing models that has been thrown away so far. This mitigates the problem of representing uncertainty in deep learning without sacrificing computational complexity or test accuracy. We perform an extensive study of the dropout uncertainty properties. Various network architectures and non-linearities are assessed on tasks of regression and classification, using MNIST as an example. We show a considerable improvement in predictive log-likelihood and RMSE compared to existing state-of-the-art methods. We finish by using dropout uncertainty in a Bayesian pipeline, with deep reinforcement learning as a practical task."
"We have built a probabilistic interpretation of dropout which allowed us to obtain model uncertainty out of existing deep learning models. We have studied the properties of this uncertainty in detail, and demonstrated possible applications, interleaving Bayesian models and deep learning models together. This extends on initial research studying dropout from the Bayesian perspective. Bernoulli dropout is only one example of a regularisation technique corresponding to an approximate variational distribution which results in uncertainty estimates. Other variants of dropout follow our interpretation as well and correspond to alternative approximating distributions. These would result in different uncertainty estimates, trading-off uncertainty quality with computational complexity. We explore these in follow-up work. Furthermore, each GP covariance function has a one-to-one correspondence with the combination of both NN non-linearities and weight regularisation. This suggests techniques to select appropriate NN structure and regularisation based on our a-priori assumptions about the data. For example, if one expects the function to be smooth and the uncertainty to increase far from the data, cosine nonlinearities and L2 regularisation might be appropriate. The study of non-linearity–regularisation combinations and the corresponding predictive mean and variance are subject of current research."
"Deep learning has attracted tremendous attention from researchers in fields such as physics, biology, and manufacturing, to name a few. Tools such as the neural network, dropout, convolutional neural networks, and others are used extensively. However, these are fields in which representing model uncertainty is of crucial importance. With the recent shift in many of these fields towards the use of Bayesian uncertainty new needs arise from deep learning tools. Standard deep learning tools for regression and classification do not capture model uncertainty. In classification, predictive probabilities obtained at the end of the pipeline (the softmax output) are often erroneously interpreted as model confidence. A model can be uncertain in its predictions even with a high softmax output. Passing a point estimate of a function through a softmax results in extrapolations with unjustified high confidence for points far from the training data. However, passing the distribution through a softmax better reflects classification uncertainty far from the training data. Model uncertainty is indispensable for the deep learning practitioner as well. With model confidence at hand we can treat uncertain inputs and special cases explicitly. For example, in the case of classification, a model might return a result with high uncertainty. In this case we might decide to pass the input to a human for classification. This can happen in a post office, sorting letters according to their zip code, or in a nuclear power plant with a system responsible for critical infrastructure. Uncertainty is important in reinforcement learning as well. With uncertainty information an agent can decide when to exploit and when to explore its environment. Recent advances in RL have made use of NNs for Q-value function approximation. These are functions that estimate the quality of different actions an agent can make. Epsilon greedy search is often used where the agent selects its best action with some probability and explores otherwise. With uncertainty estimates over the agent’s Q-value function, techniques such as Thompson sampling can be used to learn much faster."
"Bayesian probability theory offers us mathematically grounded tools to reason about model uncertainty, but these usually come with a prohibitive computational cost. It is perhaps surprising then that it is possible to cast recent deep learning tools as Bayesian models – without changing either the models or the optimisation. We show that the use of dropout (and its variants) in NNs can be interpreted as a Bayesian approximation of a well known probabilistic model: the Gaussian process. Dropout is used in many models in deep learning as a way to avoid over-fitting, and our interpretation suggests that dropout approximately integrates over the models’ weights. We develop tools for representing model uncertainty of existing dropout NNs – extracting information that has been thrown away so far. This mitigates the problem of representing model uncertainty in deep learning without sacrificing either computational complexity or test accuracy. In this paper we give a complete theoretical treatment of the link between Gaussian processes and dropout, and develop the tools necessary to represent uncertainty in deep learning. We perform an extensive exploratory assessment of the properties of the uncertainty obtained from dropout NNs and convnets on the tasks of regression and classification. We compare the uncertainty obtained from different model architectures and non-linearities in regression, and show that model uncertainty is indispensable for classification tasks, using MNIST as a concrete example. We then show a considerable improvement in predictive log-likelihood and RMSE compared to existing state-ofthe-art methods. Lastly we give a quantitative assessment of model uncertainty in the setting of reinforcement learning, on a practical task similar to that used in deep reinforcement learning."
"It has long been known that infinitely wide (single hidden layer) NNs with distributions placed over their weights converge to Gaussian processes. This known relation is through a limit argument that does not allow us to translate properties from the Gaussian process to finite NNs easily. Finite NNs with distributions placed over the weights have been studied extensively as Bayesian neural networks. These offer robustness to over-fitting as well, but with challenging inference and additional computational costs. Variational inference has been applied to these models, but with limited success. Recent advances in variational inference introduced new techniques into the field such as sampling-based variational inference and stochastic variational inference. These have been used to obtain new approximations for Bayesian neural networks that perform as well as dropout. However these models come with a prohibitive computational cost. To represent uncertainty, the number of parameters in these models is doubled for the same network size. Further, they require more time to converge and do not improve on existing techniques. Given that good uncertainty estimates can be cheaply obtained from common dropout models, this results in unnecessary additional computation. An alternative approach to variational inference makes use of expectation propagation and has improved considerably in RMSE and uncertainty estimation on VI approaches. In the results section we compare dropout to these approaches and show a significant improvement in both RMSE and uncertainty estimation."
"The main result of this paper is that neural network with arbitrary depth and non-linearities, with dropout applied before every weight layer, is mathematically equivalent to variational approximation of Gaussian process with a particular choice of covariance function. This interpretation might offer an explanation to some of dropout's key properties, such as its robustness to over-fitting. Our interpretation allows us to reason about uncertainty in deep learning, and allows the introduction of the Bayesian machinery into existing deep learning frameworks in a principled way."
"Dropout can be interpreted as a variational Bayesian approximation, where the approximating distribution is a mixture of two Gaussians with small variances and the mean of one of the Gaussians fixed at zero. The uncertainty in the weights induces prediction uncertainty by marginalising over the approximate posterior using Monte Carlo integration. This amounts to the regular dropout procedure only with dropout also applied at test time, giving output uncertainty from our dynamics model."
paper"Dropout as a Bayesian Approximation: Appendix" by Gal and Ghahramanivideohttp://research.microsoft.com/apps/video/default.aspx?id=259218 (Gal)videohttp://techtalks.tv/talks/dropout-as-a-bayesian-approximation-representing-model-uncertainty-in-deep-learning/62508/ (Gal)videohttps://youtu.be/tqGEX_Ucu04?t=12m43s (Molchanov)in russianposthttp://mlg.eng.cam.ac.uk/yarin/blog_3d801aa532c1ce.html (Gal)posthttp://mlg.eng.cam.ac.uk/yarin/blog_2248.html (Gal)post"Demos demonstrating the difference between homoscedastic and heteroscedastic regression with dropout uncertainty" (Gal)posthttp://www.computervisionblog.com/2016/06/making-deep-networks-probabilistic-via.htmlnoteshttps://casmls.github.io/general/2016/11/11/dropout.htmlnoteshttp://www.shortscience.org/paper?bibtexKey=journals/corr/GalG15noteshttps://plus.google.com/u/0/+AnkurHanda/posts/DnXB81efTwacodehttps://github.com/yaringal/DropoutUncertaintyExpscodehttps://github.com/tabacof/bayesian-nn-uncertaintycodehttp://nbviewer.jupyter.org/github/napsternxg/pytorch-practice/blob/master/Pytorch%20Uncertainity-animated.ipynbpaper"Uncertainty in Deep Learning" thesis by Yarin Gal
"A long strand of empirical research has claimed that dropout cannot be applied between the recurrent connections of a recurrent neural network. The reasoning has been that the noise hinders the network’s ability to model sequences, and instead should be applied to the RNN’s inputs and outputs alone. But dropout is a vital tool for regularisation, and without dropout in recurrent layers our models overfit quickly. In this paper we show that a recently developed theoretical framework, casting dropout as approximate Bayesian inference, can give us mathematically grounded tools to apply dropout within the recurrent layers. We apply our new dropout technique in long short-term memory networks and show that the new approach significantly outperforms existing techniques."
"We’ve seen how theoretical developments can lead to new tools within deep learning, solving a major difficulty with existing sequence models. Compared to existing pragmatic approaches in the field, where empirical experimentation with various tools might lead to new findings, we developed a theory trying to understand why existing tools work so well. In an attempt to validate the theory we made predictions (in the scientific sense) which we attempted to validate or disprove."
"Following recent theoretical results we propose a new approach that can be applied to the recurrent connections successfully. This allows us to train RNNs on much smaller data, data which is often believed to lie in the Bayesian realm."
"Many stochastic training techniques in deep learning, developed as means of regularisation, have recently been shown to follow the same mathematical foundations as approximate inference in Bayesian neural networks. Dropout, for example, is equivalent to approximate variational inference with Bernoulli variational distributions."
"We introduce the Bayesian RNN - an RNN with weights treated as random variables. Approximating the posterior distribution over the weights with a Bernoulli approximating variational distributions reveals how dropout should be applied in RNNs. More specifically, the random weights when conditioned on some observations have a posterior. This posterior is approximated with a Bernoulli approximating distribution. Implementing this approximate inference procedure is identical to repeating the same dropout mask throughout the sequence. When used with discrete inputs (i.e. words) we place a distribution over the word embeddings as well - resulting in a fully Bayesian model. This corresponds to randomly dropping words in the sentence, and might be interpreted as forcing the model not to rely on single words for its task."
videohttps://youtu.be/tqGEX_Ucu04?t=19m1s (Molchanov)in russiancodehttps://github.com/yaringal/BayesianRNN
"In this paper we investigate several popular approaches for uncertainty estimation in neural networks. We find that several popular approximations to the uncertainty of a unknown neural net model are in fact approximations to the risk given a fixed model. We review that conflating risk with uncertainty can lead to arbitrarily poor performance in a sequential decision problem. We present a simple and practical solution to this problem based upon smoothed bootstrap sampling."
"In sequential decision problems there is an important distinction between risk and uncertainty. We identify risk as inherent stochasticity in a model and uncertainty as the confusion over which model parameters apply. For example, a coin may have a fixed p = 0.5 of heads and so the outcome of any single flip holds some risk; a learning agent may also be uncertain of p. The demarcation between risk and uncertainty is tied to the specific model class, in this case a Bernoulli random variable; with a more detailed model of flip dynamics even the outcome of a coin may not be risky at all. Our distinction is that unlike risk, uncertainty captures the variability of an agent’s posterior belief which can be resolved through statistical analysis of the appropriate data. For a learning agent looking to maximize cumulative utility through time, this distinction represents a crucial dichotomy. Consider the reinforcement learning problem of an agent interacting with its environment while trying to maximize cumulative utility through time. At each timestep, the agent faces a fundamental tradeoff: by exploring uncertain states and actions the agent can learn to improve its future performance, but it may attain better short-run performance by exploiting its existing knowledge. At a high level this effect means uncertain states are more attractive since they can provide important information to the agent going forward. On the other hand, states and actions with high risk are actually less attractive for an agent in both exploration and exploitation. For exploitation, any concave utility will naturally penalize risk. For exploration, risk also makes any single observation less informative. Although colloquially similar, risk and uncertainty can require radically different treatment."
"One of the most popular recent suggestions has been to use dropout sampling (where individual neurons are independently set to zero with probability p) to “get uncertainty information from these deep learning models for free – without changing a thing”. Unfortunately, as we now show, dropout sampling can be better thought of as an approximation to the risk in y, rather than the uncertainty of the learned model. Further, using a fixed dropout rate p, rather than optimizing this variational parameter can lead an arbitrarily bad approximation to the risk."
"The resulting “dropout posterior” can have arbitrarily small or large variance depending on the interaction between the dropout rate p and the model size K".
"We extend the analysis to linear functions and argue that this behavior also carries over to deep learning; extensive computational results support this claim. We investigate the importance of risk and uncertainty in sequential decision problems and why this setting is crucially distinct from standard supervised learning tasks. We highlight the dangers of a naive applications of dropout (or any other approximate risk measure) as a proxy for uncertainty."
"We present analytical regret bounds for algorithms based upon smoothed bootstrapped uncertainty estimates that complement their strong performance in complex nonlinear domains."
Yarin Gal:
"One technique to estimate model uncertainty uses an ensemble of deterministic models, meaning that each model in the ensemble produces a point estimate rather than a distribution. It works by independently training many randomly initialised instances of a model on the same dataset (or different random subsets in the case of bootstrapping), and given an input test point, evaluating the sample variance of the outputs from all deterministic models. Even though this approach is more computationally efficient than many Bayesian approaches to model uncertainty (apart from the need to represent the parameters of multiple models), its produced uncertainty estimates lack in many ways as explained in the next illustrative example. To see this, let’s see what would happen if each deterministic model were to be given by an RBF network (whose predictions coincide with the predictive mean of a Gaussian process with a squared-exponential covariance function). An RBF network predicts zero for test points far from the training data. This means that in an ensemble of RBF networks, each and every network will predict zero for a given test point far from the training data. As a result, the sample variance of this technique will be zero at the given test point. The ensemble of models will have very high confidence in its prediction of zero even though the test point lies far from the data! This limitation can be alleviated by using an ensemble of probabilistic models instead of deterministic models. Even though the RBF network’s predictions coincide with the predictive mean of the SE Gaussian process, by using a Gaussian process we could also make use of its predictive variance. The Gaussian process predictions far from the training data will have large model uncertainty. In the ensemble, we would thus wish to take into account each model’s confidence as well as its mean (by sampling an output from each model’s predictive distribution before calculating our sample variance)."
Ian Osband:
"- There is a difference between the posterior distribution for an outcome, and your posterior distribution for what you think is the mean of an outcome.
- Both of these can be very useful, but since these distributions can be very different you need to pick which type you are approximating. If you want to do Thompson sampling for exploration you should sample over the right thing.
- Something feels a strange about a Bayesian posterior that doesn't concentrate with more data."
"Variational Dropout and the Local Reparameterization Trick" Kingma, Salimans, Welling
"We investigate a local reparameterizaton technique for greatly reducing the variance of stochastic gradients for variational Bayesian inference (SGVB) of a posterior over model parameters, while retaining parallelizability. This local reparameterization translates uncertainty about global parameters into local noise that is independent across datapoints in the minibatch. Such parameterizations can be trivially parallelized and have variance that is inversely proportional to the minibatch size, generally leading to much faster convergence. Additionally, we explore a connection with dropout: Gaussian dropout objectives correspond to SGVB with local reparameterization, a scale-invariant prior and proportionally fixed posterior variance. Our method allows inference of more flexibly parameterized posteriors; specifically, we propose variational dropout, a generalization of Gaussian dropout where the dropout rates are learned, often leading to better models. The method is demonstrated through several experiments."
noteshttp://www.shortscience.org/paper?bibtexKey=conf/nips/BlumHP15codehttps://github.com/kefirski/variational_dropoutpaper"Variational Gaussian Dropout is not Bayesian" by Hron, Matthews, Ghahramani
"Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles" Lakshminarayanan, Pritzel, Blundell
"Deep neural networks are powerful black box predictors that have recently achieved impressive performance on a wide spectrum of tasks. Quantifying predictive uncertainty in neural networks is a challenging and yet unsolved problem. Bayesian neural networks, which learn a distribution over weights, are currently the state-of-the-art for estimating predictive uncertainty; however these require significant modifications to the training procedure and are computationally expensive compared to standard (non-Bayesian) neural neural networks. We propose an alternative to Bayesian neural networks, that is simple to implement, readily parallelisable and yields high quality predictive uncertainty estimates. Through a series of experiments on classification and regression benchmarks, we demonstrate that our method produces well-calibrated uncertainty estimates which are as good or better than approximate Bayesian neural networks. To assess robustness to dataset shift, we evaluate the predictive uncertainty on test examples from known and unknown distributions, and show that our method is able to express higher uncertainty on unseen data. We demonstrate the scalability of our method by evaluating predictive uncertainty estimates on ImageNet."
"We have proposed a simple and scalable solution that provides a very strong baseline on evaluation metrics for uncertainty quantification. Our method uses scoring rules as training objectives to encourage the neural network to produce better calibrated predictions and uses a combination of ensembles and adversarial training for robustness to model misspecification and dataset shift. Our method is well suited for large scale distributed computation and can be readily implemented for a wide variety of architectures such as MLPs, CNNs, etc including those which do not use dropout (e.g. residual networks). It is perhaps surprising to the Bayesian deep learning community that a non-Bayesian (yet probabilistic) approach can perform as well as Bayesian neural networks. We hope that this work will encourage community to think about hybrid approaches (e.g. using non-Bayesian approaches such as ensembles) and other interesting metrics for evaluating predictive uncertainty."
"Adversarial Training to improve the uncertainty measure of the entropy score of the neural network."
"Good uncertainty estimate: calibration + higher uncertainty on out-of-distribution examples."
"Existing bayesian solutions (MCMC, VI, MC-Dropout) are hard to scale and requires significant modifications for training."
"Single network and MC-Dropout can produce overconfident wrong predictions, whereas deep ensembles are more robust."
videohttps://facebook.com/nipsfoundation/videos/1554654864625747?t=3623 (Lakshminarayanan)noteshttps://bayesgroup.github.io/sufficient-statistics/posts/simple-and-scalable-predictive-uncertainty-estimation-using-deep-ensembles/in russiancodehttps://github.com/axelbrando/Mixture-Density-Networks-for-distribution-and-uncertainty-estimation
"We reinterpret multiplicative noise in neural networks as auxiliary random variables that augment the approximate posterior in a variational setting for Bayesian neural networks. We show that through this interpretation it is both efficient and straightforward to improve the approximation by employing normalizing flows (Rezende & Mohamed, 2015) while still allowing for local reparametrizations (Kingma et al., 2015) and a tractable lower bound (Ranganath et al., 2015; Maaløe et al., 2016). In experiments we show that with this new approximation we can significantly improve upon classical mean field for Bayesian neural networks on both predictive accuracy as well as predictive uncertainty."
"We compared our uncer-tainty on notMNIST and CIFAR with Dropout (Srivastavaet al., 2014; Gal & Ghahramani, 2015b) and Deep Ensembles (Lakshminarayanan et al., 2016) using convolutional architectures and found that MNFs achieve more realistic uncertainties while providing predictive capabilities on par with Dropout. We suspect that the predictive capabilities of MNFs can be further improved through more appropriate optimizers that avoid the bad local minima in the variational objective. Finally, we also highlighted limitations of Dropout approximations and empirically showed that MNFs can overcome them."
"Another promising direction is that of designing better priors for Bayesian neural networks. For example (Neal, 1995) has identified limitations of Gaussian priors and proposes alternative priors such as the Cauchy. Furthermore, the prior over the parameters also affects the type of uncertainty we get in our predictions; for instance we observed in our experiments a significant difference in uncertainty between Gaussian and log-uniform priors. Since different problems require different types of uncertainty it makes sense to choose the prior accordingly, e.g. use an informative prior so as to alleviate adversarial examples."
videohttps://youtu.be/tqGEX_Ucu04?t=39m23s (Molchanov)in russian
interesting recent papers
interesting recent papers - generative models
https://github.com/zhangqianhui/AdversarialNetsPapers
https://github.com/nightrome/really-awesome-gan/
"Generative Adversarial Networks" Goodfellow, Pouget-Abadie, Mirza, Xu, Warde-Farley, Ozair, Courville, Bengio
"We propose a new framework for estimating generative models via an adversarial process, in which we simultaneously train two models: a generative model G that captures the data distribution, and a discriminative model D that estimates the probability that a sample came from the training data rather than G. The training procedure for G is to maximize the probability of D making a mistake. This framework corresponds to a minimax two-player game. In the space of arbitrary functions G and D, a unique solution exists, with G recovering the training data distribution and D equal to 1/2 everywhere. In the case where G and D are defined by multilayer perceptrons, the entire system can be trained with backpropagation. There is no need for any Markov chains or unrolled approximate inference networks during either training or generation of samples."
- http://cs.stanford.edu/people/karpathy/gan/ (demo)
videohttps://channel9.msdn.com/Events/Neural-Information-Processing-Systems-Conference/Neural-Information-Processing-Systems-Conference-NIPS-2016/Generative-Adversarial-Networks (Goodfellow)video"Tips & tricks" (Chintala)post"Tips & tricks" (Chintala)slides"How to Train a GAN" (Denton, Arjovsky, Mathieu, Goodfellow, Chintala)posthttp://www.offconvex.org/2017/03/15/GANs/ (Arora)posthttp://inference.vc/how-to-train-your-generative-models-why-generative-adversarial-networks-work-so-well-2/posthttp://inference.vc/an-alternative-update-rule-for-generative-adversarial-networks/posthttp://blog.evjang.com/2016/06/generative-adversarial-nets-in.htmlposthttps://oshearesearch.com/index.php/2016/07/01/mnist-generative-adversarial-model-in-keras/codehttps://github.com/wiseodd/generative-models/tree/master/GAN
"Learning in Implicit Generative Models" Mohamed, Lakshminarayanan
"Generative adversarial networks (GANs) provide an algorithmic framework for constructing generative models with several appealing properties: they do not require a likelihood function to be specified, only a generating procedure; they provide samples that are sharp and compelling; and they allow us to harness our knowledge of building highly accurate neural network classifiers. Here, we develop our understanding of GANs with the aim of forming a rich view of this growing area of machine learning---to build connections to the diverse set of statistical thinking on this topic, of which much can be gained by a mutual exchange of ideas. We frame GANs within the wider landscape of algorithms for learning in implicit generative models--models that only specify a stochastic procedure with which to generate data--and relate these ideas to modelling problems in related fields, such as econometrics and approximate Bayesian computation. We develop likelihood-free inference methods and highlight hypothesis testing as a principle for learning in implicit generative models, using which we are able to derive the objective function used by GANs, and many other related objectives. The testing viewpoint directs our focus to the general problem of density ratio estimation. There are four approaches for density ratio estimation, one of which is a solution using classifiers to distinguish real from generated data. Other approaches such as divergence minimisation and moment matching have also been explored in the GAN literature, and we synthesise these views to form an understanding in terms of the relationships between them and the wider literature, highlighting avenues for future exploration and cross-pollination."
videohttps://youtu.be/RZOKRFBtSh4?t=5m37s (Mohamed)videohttps://youtu.be/jAI3rBI6poU?t=37m56s (Ulyanov)in russianposthttps://casmls.github.io/general/2017/05/24/ligm.html
"Adversarial Autoencoders" Makhzani, Shlens, Jaitly, Goodfellow
"In this paper we propose a new method for regularizing autoencoders by imposing an arbitrary prior on the latent representation of the autoencoder. Our method, named “adversarial autoencoder”, uses the recently proposed generative adversarial networks in order to match the aggregated posterior of the hidden code vector of the autoencoder with an arbitrary prior. Matching the aggregated posterior to the prior ensures that there are no “holes” in the prior, and generating from any part of prior space results in meaningful samples. As a result, the decoder of the adversarial autoencoder learns a deep generative model that maps the imposed prior to the data distribution. We show how adversarial autoencoders can be used to disentangle style and content of images and achieve competitive generative performance on MNIST, Street View House Numbers and Toronto Face datasets."
"In this paper we proposed a general framework to turn any autoencoder into a generative model by imposing an arbitrary distribution on the latent representation of the autoencoder. In our model, an autoencoder is trained with dual objectives - a traditional reconstruction error criterion, and an adversarial training criterion (Goodfellow et al., 2014) that matches the aggregated posterior distribution of the latent representation of the autoencoder to an arbitrary prior distribution. We show that this training criterion has a strong connection to VAE training. The result of the training is that the encoder learns to convert the data distribution to the prior distribution, while the decoder learns a deep generative model that maps the imposed prior to the data distribution. We discussed how this method can be extended to semi-supervised settings by incorporating the label information to better shape the hidden code distribution. Importantly, we demonstrated how it can be used to disentangle the style and label information of a dataset (Kingma et al., 2014; Cheung et al., 2014). Finally we showed that adversarial autoencoders can achieve state-of-the-art likelihoods on real-valued MNIST and Toronto Face datasets."
"An important difference between VAEs and adversarial autoencoders is that in VAEs, in order to back-propagate through the KL divergence by Monte-Carlo sampling, we need to have access to the exact functional form of the prior distribution. However, in adversarial autoencoders, we only need to be able to sample from the prior distribution in order to induce q(z) to match p(z). In Section 3, we demonstrate that the adversarial autoencoder can impose complicated distributions without having access to the explicit functional form of the distribution."
"Minimising DKL[Q(Z|X) || P(Z)] of VAE penalises the model Q(Z) if it contains samples that are outside the support of the true distribution P(Z), which might mean that Q(Z) captures only a part of P(Z). This means that when sampling P(Z), we may sample a region that is not captured by Q(Z). The reverse KL divergence, DKL[P(Z) || Q(Z|X)], penalises the model Q(Z) if P(Z) produces samples that are outside of the support of Q(Z). By minimising this KL divergence, most samples in P(Z) will likely be in Q(Z) as well. AAEs are regularised using the JS entropy, given by 1/2 * DKL[P(Z) || 1/2 * (P(Z) + Q(Z|X))] + 1/2 * DKL[Q(Z|X) || 1/2 * (P(Z) + Q(Z|X))]. Minimising this cost function attempts to find a compromise between the aforementioned extremes."
posthttp://dustintran.com/blog/adversarial-autoencoders/posthttp://inference.vc/adversarial-autoencoders/posthttps://blog.paperspace.com/adversarial-autoencoders-with-pytorch/noteshttp://www.shortscience.org/paper?bibtexKey=journals/corr/MakhzaniSJG15codehttps://github.com/wiseodd/generative-models/tree/master/VAE/adversarial_autoencoderpaper"From Optimal Transport to Generative Modeling: the VEGAN Cookbook" by Bousquet et al.
"InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets" Chen, Duan, Houthooft, Schulman, Sutskever, Abbeel
"This paper describes InfoGAN, an information-theoretic extension to the Generative Adversarial Network that is able to learn disentangled representations in a completely unsupervised manner. InfoGAN is a generative adversarial network that also maximizes the mutual information between a small subset of the latent variables and the observation. We derive a lower bound of the mutual information objective that can be optimized efficiently. Specifically, InfoGAN successfully disentangles writing styles from digit shapes on the MNIST dataset, pose from lighting of 3D rendered images, and background digits from the central digit on the SVHN dataset. It also discovers visual concepts that include hair styles, presence/absence of eyeglasses, and emotions on the CelebA face dataset. Experiments show that InfoGAN learns interpretable representations that are competitive with representations learned by existing supervised methods."
"In contrast to previous approaches, which require supervision, InfoGAN is completely unsupervised and learns interpretable and disentangled representations on challenging datasets. In addition, InfoGAN adds only negligible computation cost on top of GAN and is easy to train. The core idea of using mutual information to induce representation can be applied to other methods like VAE, which is a promising area of future work. Other possible extensions to this work include: learning hierarchical latent representations, improving semi-supervised learning with better codes, and using InfoGAN as a high-dimensional data discovery tool."
"An extension of GAN that learns disentangled and interpretable representations for images. A regular GAN achieves the objective of reproducing the data distribution in the model, but the layout and organization of the code space is underspecified - there are many possible solutions to mapping the unit Gaussian to images and the one we end up with might be intricate and highly entangled. The InfoGAN imposes additional structure on this space by adding new objectives that involve maximizing the mutual information between small subsets of the representation variables and the observation. This approach provides quite remarkable results. For example, in the images of 3D faces we vary one continuous dimension of the code, keeping all others fixed. It's clear from the five provided examples that the resulting dimensions in the code capture interpretable dimensions, and that the model has perhaps understood that there are camera angles, facial variations, etc., without having been told that these features exist and are important."
- https://goo.gl/58Ishd + https://goo.gl/q7Hp99 + https://goo.gl/Ceqlr4 + https://goo.gl/9ibbsV (demo)
videohttps://channel9.msdn.com/Events/Neural-Information-Processing-Systems-Conference/Neural-Information-Processing-Systems-Conference-NIPS-2016/Deep-Learning-Symposium-Session-1 (53:28) (Chen)posthttp://depthfirstlearning.com/2018/InfoGANposthttp://inference.vc/infogan-variational-bound-on-mutual-information-twice/posthttp://wiseodd.github.io/techblog/2017/01/29/infogan/codehttps://github.com/openai/InfoGANcodehttps://github.com/wiseodd/generative-models/tree/master/GAN/infogan
"BEGAN: Boundary Equilibrium Generative Adversarial Networks" Berthelot, Schumm, Metz
"We propose a new equilibrium enforcing method paired with a loss derived from the Wasserstein distance for training auto-encoder based Generative Adversarial Networks. This method balances the generator and discriminator during training. Additionally, it provides a new approximate convergence measure, fast and stable training and high visual quality. We also derive a way of controlling the trade-off between image diversity and visual quality. We focus on the image generation task, setting a new milestone in visual quality, even at higher resolutions. This is achieved while using a relatively simple model architecture and a standard training procedure."
"- A GAN with a simple yet robust architecture, standard training procedure with fast and stable convergence.
- An equilibrium concept that balances the power of the discriminator against the generator.
- A new way to control the trade-off between image diversity and visual quality.
- An approximate measure of convergence. To our knowledge the only other published measure is from Wasserstein GAN."
"We introduced BEGAN, a GAN that uses an auto-encoder as the discriminator. Using the proposed equilibrium method, this network converges to diverse and visually pleasing images. This remains true at higher resolutions with trivial modifications. Training is stable, fast and robust to parameter changes. It does not require a complex alternating training procedure. Our approach provides at least partial solutions to some outstanding GAN problems such as measuring convergence, controlling distributional diversity and maintaining the equilibrium between the discriminator and the generator."
"There are still many unexplored avenues. Does the discriminator have to be an auto-encoder? Having pixel-level feedback seems to greatly help convergence, however using an auto-encoder has its drawbacks: what internal embedding size is best for a dataset? When should noise be added to the input and how much? What impact would using other varieties of auto-encoders such Variational Auto-Encoders have?"
- https://pbs.twimg.com/media/C8lYiYbW0AI4_yk.jpg:large + https://pbs.twimg.com/media/C8c6T2kXsAAI-BN.jpg (demo)
posthttps://blog.heuritech.com/2017/04/11/began-state-of-the-art-generation-of-faces-with-generative-adversarial-networks/noteshttps://reddit.com/r/MachineLearning/comments/633jal/r170310717_began_boundary_equilibrium_generative/dfrktje/codehttps://github.com/carpedm20/BEGAN-tensorflowcodehttps://github.com/carpedm20/BEGAN-pytorch
{kind=link}
{kind=link}
"Improved Techniques for Training GANs" Salimans, Goodfellow, Zaremba, Cheung, Radford, Chen
"We present a variety of new architectural features and training procedures that we apply to the generative adversarial networks (GANs) framework. We focus on two applications of GANs: semi-supervised learning, and the generation of images that humans find visually realistic. Unlike most work on generative models, our primary goal is not to train a model that assigns high likelihood to test data, nor do we require the model to be able to learn well without using any labels. Using our new techniques, we achieve state-of-the-art results in semi-supervised classification on MNIST, CIFAR-10 and SVHN. The generated images are of high quality as confirmed by a visual Turing test: our model generates MNIST samples that humans cannot distinguish from real data, and CIFAR-10 samples that yield a human error rate of 21.3%. We also present ImageNet samples with unprecedented resolution and show that our methods enable the model to learn recognizable features of ImageNet classes."
"Our CIFAR-10 samples also look very sharp - Amazon Mechanical Turk workers can distinguish our samples from real data with an error rate of 21.3% (50% would be random guessing)."
"In addition to generating pretty pictures, we introduce an approach for semi-supervised learning with GANs that involves the discriminator producing an additional output indicating the label of the input. This approach allows us to obtain state of the art results on MNIST, SVHN, and CIFAR-10 in settings with very few labeled examples. On MNIST, for example, we achieve 99.14% accuracy with only 10 labeled examples per class with a fully connected neural network — a result that’s very close to the best known results with fully supervised approaches using all 60,000 labeled examples."
videohttps://youtu.be/RZOKRFBtSh4?t=26m18s (Metz)noteshttps://github.com/aleju/papers/blob/master/neural-nets/Improved_Techniques_for_Training_GANs.mdnoteshttp://www.shortscience.org/paper?bibtexKey=journals%2Fcorr%2FSalimansGZCRC16posthttp://inference.vc/understanding-minibatch-discrimination-in-gans/codehttps://github.com/openai/improved-gan
"Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks" Radford, Metz, Chintala
"In recent years, supervised learning with convolutional networks has seen huge adoption in computer vision applications. Comparatively, unsupervised learning with CNNs has received less attention. In this work we hope to help bridge the gap between the success of CNNs for supervised learning and unsupervised learning. We introduce a class of CNNs called deep convolutional generative adversarial networks (DCGANs), that have certain architectural constraints, and demonstrate that they are a strong candidate for unsupervised learning. Training on various image datasets, we show convincing evidence that our deep convolutional adversarial pair learns a hierarchy of representations from object parts to scenes in both the generator and discriminator. Additionally, we use the learned features for novel tasks - demonstrating their applicability as general image representations."
- https://plus.google.com/+SoumithChintala/posts/MCtDVqsef6f (demo)
- https://mattya.github.io/chainer-DCGAN/ (demo)
videohttps://youtube.com/watch?v=4_5KTdS-b-U (Chintala)codehttps://github.com/jacobgil/keras-dcgancodehttps://github.com/carpedm20/DCGAN-tensorflow
interesting papers - bayesian deep learning
interesting recent papers
interesting recent papers - generative models
interesting recent papers - bayesian deep learning
"Auto-Encoding Variational Bayes" Kingma, Welling
"How can we perform efficient inference and learning in directed probabilistic models, in the presence of continuous latent variables with intractable posterior distributions, and large datasets? We introduce a stochastic variational inference and learning algorithm that scales to large datasets and, under some mild differentiability conditions, even works in the intractable case. Our contributions is two-fold. First, we show that a reparameterization of the variational lower bound yields a lower bound estimator that can be straightforwardly optimized using standard stochastic gradient methods. Second, we show that for i.i.d. datasets with continuous latent variables per datapoint, posterior inference can be made especially efficient by fitting an approximate inference model (also called a recognition model) to the intractable posterior using the proposed lower bound estimator. Theoretical advantages are reflected in experimental results."
"Latent variable probabilistic models are ubiquitous, but often inference in such models is intractable. Variational inference methods based on approximation of the true posterior currently are most popular deterministic inference techniques. Recently one particularly interesting method for parametric variational approximation was proposed called Auto-encoding variational bayes. In this method, approximate posterior explicitly depends on data and may be almost arbitrary complex, e.g. a deep neural network. Thus, the problem of variational inference may be considered as a learning of auto-encoder where the code is represented by latent variables, encoder is the likelihood model and decoder is our variational approximation. Since neural networks can serve as universal function approximators, such inference method may allow to obtain better results than for "shallow" parametric approximations or free-form mean-field ones."
videohttp://youtube.com/watch?v=rjZL7aguLAs (Kingma)videohttp://videolectures.net/deeplearning2015_courville_autoencoder_extension/ (Courville)videohttps://youtu.be/_qrHcSdQ2J4?t=1h37m21s (Vetrov)in russianpaperhttp://arxiv.org/abs/1606.05908 + https://github.com/cdoersch/vae_tutorial (tutorial)paperhttp://arxiv.org/abs/1610.09296 (explanation)posthttp://kvfrans.com/variational-autoencoders-explained/posthttps://towardsdatascience.com/intuitively-understanding-variational-autoencoders-1bfe67eb5dafposthttp://hsaghir.github.io/denoising-vs-variational-autoencoder/posthttp://jaan.io/what-is-variational-autoencoder-vae-tutorial/posthttp://blog.keras.io/building-autoencoders-in-keras.htmlposthttps://jmetzen.github.io/2015-11-27/vae.htmlposthttp://blog.fastforwardlabs.com/post/148842796218/introducing-variational-autoencoders-in-prose-andposthttp://blog.fastforwardlabs.com/post/149329060653/under-the-hood-of-the-variational-autoencoder-incodehttps://github.com/wiseodd/generative-models/tree/master/VAEcodehttps://github.com/fchollet/keras/blob/master/examples/variational_autoencoder.py
"Stochastic Backpropagation and Approximate Inference in Deep Generative Models" Rezende, Mohamed, Wiestra
"We marry ideas from deep neural networks and approximate Bayesian inference to derive a generalised class of deep, directed generative models, endowed with a new algorithm for scalable inference and learning. Our algorithm introduces a recognition model to represent an approximate posterior distribution and uses this for optimisation of a variational lower bound. We develop stochastic back-propagation rules for gradient backpropagation through stochastic variables and derive an algorithm that allows for joint optimisation of the parameters of both the generative and recognition models. We demonstrate on several real-world data sets that by using stochastic backpropagation and variational inference, we obtain models that are able to generate realistic samples of data, allow for accurate imputations of missing data, and provide a useful tool for high-dimensional data visualisation."
videohttp://techtalks.tv/talks/stochastic-backpropagation-and-approximate-inference-in-deep-generative-models/60885/videohttp://vk.com/video-44016343_456239093 (Stepochkin)in russian
"Semi-supervised Learning with Deep Generative Models" Kingma, Rezende, Mohamed, Welling
"The ever-increasing size of modern data sets combined with the difficulty of obtaining label information has made semi-supervised learning one of the problems of significant practical importance in modern data analysis. We revisit the approach to semi-supervised learning with generative models and develop new models that allow for effective generalisation from small labelled data sets to large unlabelled ones. Generative approaches have thus far been either inflexible, inefficient or non-scalable. We show that deep generative models and approximate Bayesian inference exploiting recent advances in variational methods can be used to provide significant improvements, making generative approaches highly competitive for semi-supervised learning."
"The approximate inference methods introduced here can be easily extended to the model’s parameters, harnessing the full power of variational learning. Such an extension also provides a principled ground for performing model selection. Efficient model selection is particularly important when the amount of available data is not large, such as in semi-supervised learning. For image classification tasks, one area of interest is to combine such methods with convolutional neural networks that form the gold-standard for current supervised classification methods. Since all the components of our model are parametrised by neural networks we can readily exploit convolutional or more general locally-connected architectures – and forms a promising avenue for future exploration."
"A limitation of the models we have presented is that they scale linearly in the number of classes in the data sets. Having to re-evaluate the generative likelihood for each class during training is an expensive operation. Potential reduction of the number of evaluations could be achieved by using a truncation of the posterior mass. For instance we could combine our method with the truncation algorithm suggested by Pal et al. (2005), or by using mechanisms such as error-correcting output codes. The extension of our model to multi-label classification problems that is essential for image-tagging is also possible, but requires similar approximations to reduce the number of likelihood-evaluations per class."
"We have developed new models for semi-supervised learning that allow us to improve the quality of prediction by exploiting information in the data density using generative models. We have developed an efficient variational optimisation algorithm for approximate Bayesian inference in these models and demonstrated that they are amongst the most competitive models currently available for semisupervised learning."
"
- We describe a new framework for semi-supervised learning with generative models, employing rich parametric density estimators formed by the fusion of probabilistic modelling and deep neural networks.
- We show for the first time how variational inference can be brought to bear upon the problem of semi-supervised classification. In particular, we develop a stochastic variational inference algorithm that allows for joint optimisation of both model and variational parameters, and that is scalable to large datasets.
- We demonstrate the performance of our approach on a number of data sets providing state-of-the-art results on benchmark problems.
- We show qualitatively generative semi-supervised models learn to separate the data classes (content types) from the intra-class variabilities (styles), allowing in a very straightforward fashion to simulate analogies of images on a variety of datasets."
videohttps://youtube.com/watch?v=bJhV2C5KKZ4 (Kingma)videohttp://videolectures.net/deeplearning2015_courville_autoencoder_extension/#t=3192 (Courville)videohttps://youtu.be/0veUbpdBqyk?t=1h7m46s (Chervinsky)in russianposthttp://bjlkeng.github.io/posts/semi-supervised-learning-with-variational-autoencoders/
"Unsupervised Learning of 3D Structure from Images" Rezende, Eslami, Mohamed, Battaglia, Jaderberg, Heess
"A key goal of computer vision is to recover the underlying 3D structure from 2D observations of the world. In this paper we learn strong deep generative models of 3D structures, and recover these structures from 3D and 2D images via probabilistic inference. We demonstrate high-quality samples and report log-likelihoods on several datasets, including ShapeNet, and establish the first benchmarks in the literature. We also show how these models and their inference networks can be trained end-to-end from 2D images. This demonstrates for the first time the feasibility of learning to infer 3D representations of the world in a purely unsupervised manner."
"A key goal of computer vision is that of recovering the underlying 3D structure that gives rise to these 2D observations. The 2D projection of a scene is a complex function of the attributes and positions of the camera, lights and objects that make up the scene. If endowed with 3D understanding, agents can abstract away from this complexity to form stable, disentangled representations, e.g., recognizing that a chair is a chair whether seen from above or from the side, under different lighting conditions, or under partial occlusion. Moreover, such representations would allow agents to determine downstream properties of these elements more easily and with less training, e.g., enabling intuitive physical reasoning about the stability of the chair, planning a path to approach it, or figuring out how best to pick it up or sit on it. Models of 3D representations also have applications in scene completion, denoising, compression and generative virtual reality."
"There have been many attempts at performing this kind of reasoning, dating back to the earliest years of the field. Despite this, progress has been slow for several reasons: First, the task is inherently ill-posed. Objects always appear under self-occlusion, and there are an infinite number of 3D structures that could give rise to a particular 2D observation. The natural way to address this problem is by learning statistical models that recognize which 3D structures are likely and which are not. Second, even when endowed with such a statistical model, inference is intractable. This includes the sub-tasks of mapping image pixels to 3D representations, detecting and establishing correspondences between different images of the same structures, and that of handling the multi-modality of the representations in this 3D space. Third, it is unclear how 3D structures are best represented, e.g., via dense volumes of voxels, via a collection of vertices, edges and faces that define a polyhedral mesh, or some other kind of representation. Finally, ground-truth 3D data is difficult and expensive to collect and therefore datasets have so far been relatively limited in size and scope."
" We design a strong generative model of 3D structures, defined over the space of volumes and meshes, using ideas from state-of-the-art generative models of images.
We show that our models produce high-quality samples, can effectively capture uncertainty and are amenable to probabilistic inference, allowing for applications in 3D generation and simulation. We report log-likelihoods on a dataset of shape primitives, a 3D version of MNIST, and on ShapeNet, which to the best of our knowledge, constitutes the first quantitative benchmark for 3D density modeling.
We show how complex inference tasks, e.g., that of inferring plausible 3D structures given a 2D image, can be achieved using conditional training of the models. We demonstrate that such models recover 3D representations in one forward pass of a neural network and they accurately capture the multi-modality of the posterior.
We explore both volumetric and mesh-based representations of 3D structure. The latter is achieved by flexible inclusion of off-the-shelf renders such as OpenGL. This allows us to build in further knowledge of the rendering process, e.g., how light bounces of surfaces and interacts with its material’s attributes.
We show how the aforementioned models and inference networks can be trained end-to-end directly from 2D images without any use of ground-truth 3D labels. This demonstrates for the first time the feasibility of learning to infer 3D representations of the world in a purely unsupervised manner."
"In this paper we introduced a powerful family of 3D generative models inspired by recent advances in image modeling. We showed that when trained on ground-truth volumes, they can produce high-quality samples that capture the multi-modality of the data. We further showed how common inference tasks, such as that of inferring a posterior over 3D structures given a 2D image, can be performed efficiently via conditional training. We also demonstrated end-to-end training of such models directly from 2D images through the use of differentiable renderers. We experimented with two kinds of 3D representations: volumes and meshes. Volumes are flexible and can capture a diverse range of structures, however they introduce modeling and computational challenges due to their high dimensionality. Conversely, meshes can be much lower dimensional and therefore easier to work with, and they are the data-type of choice for common rendering engines, however standard paramaterizations can be restrictive in the range of shapes they can capture."
videohttps://youtube.com/watch?v=stvDAGQwL5c + https://goo.gl/9hCkxs (demo)videohttps://docs.google.com/presentation/d/12uZQ_Vbvt3tzQYhWR3BexqOzbZ-8AeT_jZjuuYjPJiY/pub?start=true&loop=true&delayms=30000#slide=id.g1329951dde_0_0 (demo)videohttps://youtu.be/AggqBRdz6CQ?t=13m29s (Mohamed)noteshttps://blog.acolyer.org/2017/01/05/unsupervised-learning-of-3d-structure-from-images/
"Variational Lossy Autoencoder" Chen, Kingma, Salimans, Duan, Dhariwal, Schulman, Sutskever, Abbeel
"Representation learning seeks to expose certain aspects of observed data in a learned representation that’s amenable to downstream tasks like classification. For instance, a good representation for 2D images might be one that describes only global structure and discards information about detailed texture. In this paper, we present a simple but principled method to learn such global representations by combining Variational Autoencoder (VAE) with neural autoregressive models such as RNN, MADE and PixelRNN/CNN. Our proposed VAE model allows us to have control over what the global latent code can learn and by designing the architecture accordingly, we can force the global latent code to discard irrelevant information such as texture in 2D images, and hence the code only “autoencodes” data in a lossy fashion. In addition, by leveraging autoregressive models as both prior distribution p(z) and decoding distribution p(x|z), we can greatly improve generative modeling performance of VAEs, achieving new state-of-the-art results on MNIST, OMNIGLOT and Caltech-101 Silhouettes density estimation tasks."
"In this paper, we analyze the condition under which the latent code in VAE should be used, i.e. when does VAE autoencode, and use this observation to design a VAE model that’s a lossy compressor of observed data. At modeling level, we propose two complementary improvements to VAE that are shown to have good empirical performance. VLAE has the appealing properties of controllable representation learning and improved density estimation performance but these properties come at a cost: compared with VAE models that have simple prior and decoder, VLAE is slower at generation due to the sequential nature of autoregressive model. In addition, we also tried our method on CIFAR-10 dataset, but so far we only got 3.09 bits per dim, which is not as good as PixelRNN’s 3.00 bits per dim. We believe that by improving the VAE training procedure, the gap could be closed. Moving forward, we believe it’s exciting to extend this principle of learning lossy codes to other forms of data, in particular those that have a temporal aspect like audio and video. Another promising direction is to design representations that contain only information for downstream tasks and utilize those representations to improve semi-supervised learning."
"Information that can be modeled locally by decoding distribution p(x|z) without access to z will be encoded locally and only the remainder will be encoded in z.
There are two ways to utilize this information:
- Use explicit information placement to restrict the reception of the autoregressive model, thereby forcing the model to use the latent code z which is globally provided.
- Parametrize the prior distribution with a autoregressive model showing that a type of autoregressive latent code can reduce inefficiency in Bits-Back coding."
"Adversarially Learned Inference" Dumoulin, Belghazi, Poole, Lamb, Arjovsky, Mastropietro, Courville
"We introduce the adversarially learned inference (ALI) model, which jointly learns a generation network and an inference network using an adversarial process. The generation network maps samples from stochastic latent variables to the data space while the inference network maps training examples in data space to the space of latent variables. An adversarial game is cast between these two networks and a discriminative network that is trained to distinguish between joint latent/data-space samples from the generative network and joint samples from the inference network. We illustrate the ability of the model to learn mutually coherent inference and generation networks through the inspections of model samples and reconstructions and confirm the usefulness of the learned representations by obtaining a performance competitive with other recent approaches on the semi-supervised SVHN task."
"Despite the impressive progress of VAE-based approaches for learning deep directed generative models, they still suffer from a well-recognized issue of the maximum likelihood training paradigm. Models trained to maximize likelihood of the training data tend to be conservative, distributing probability mass diffusely over the data space. In the case of learning generative models of images, this results in almost all probability mass lying outside the relatively restrictive subset of pixel space occupied by natural images. The direct consequence of this is that image samples from VAE-trained models tend to be blurry. On the other hand, GAN-based techniques are trained via an adversarial process that does not appear to suffer from the same probability mass diffusion problem as does maximum likelihood. While GANs learn a generative model that produces higher-quality samples, only the VAE-based models learn an efficient mechanism for inference. For applications such as semi-supervised learning, GANs are insufficient as they do not provide an efficient inference mechanism."
"Our approach casts the learning of both an inference machine (or encoder) and a deep directed generative model (or decoder) in an GAN-like adversarial framework. A discriminator is trained to discriminate joint samples of the data and the corresponding latent variable from the encoder (or approximate posterior) from joint samples from the decoder. In opposition to the discriminator, we have two generative models, the encoder and the decoder, trained together to fool the discriminator. GAN is an example of how one can leverage highly effective discriminative training techniques in service of learning deep generative networks. Here, we are effectively doubling down on the gambit that we can exploit discriminative training. Not only are we asking the discriminator to distinguish synthetic samples from real data, but we are requiring it to distinguish between two joint distributions over the data space and the latent variables."
"Reconstructions in ALI are quite different from reconstructions in VAE-like models. Instead of focusing on achieving a pixel-perfect reconstruction, ALI produces reconstructions that often faithfully represent more abstract features of the input images, while making mistakes in capturing exact object placement, color, style and (in extreme cases) object identity. These reconstructions suggest that the ALI latent variable representations are potentially more invariant to these less interesting factors of variation in the input and do not devote model capacity to capturing these factors. The fact that ALI’s latent representation tends to focus on semantic information at the expense of low-level details leads us to believe that ALI may be well suited to semi-supervised tasks. We empirically verify this by achieving a competitive performance on the semi-supervised SVHN classification task."
"Figure shows a comparison of the ability of GAN and ALI to fit a simple 2-dimensional synthetic gaussian mixture dataset. The decoder and discriminator networks are matched between ALI and GAN, and the hyperparameters are the same. In this experiment, ALI converges faster than GAN and to a better solution. Despite the relative simplicity of the data distribution, GAN partially failed to converge to the distribution, ignoring the central mode. The toy task also exhibits nice properties of the features learned by ALI: when mapped to the latent space, data samples cover the whole prior, and they get clustered by mixture components, with a clear separation between each mode."
"Modified GAN setup to have a "visible generator" compete against a "latent generator" so that the network can perform inference, generation, and semantic reconstruction."
posthttps://ishmaelbelghazi.github.io/ALI/videohttps://youtube.com/watch?v=yyl0-y-k4Nc (Courville)videohttps://youtube.com/watch?v=K3r2k93zJrw (Courville)noteshttp://www.shortscience.org/paper?bibtexKey=journals/corr/1606.00704posthttp://inference.vc/variational-inference-using-implicit-models-part-iii-joint-contrastive-inference-ali-and-bigan/codehttps://github.com/IshmaelBelghazi/ALI
"Adversarial Feature Learning" Donahue, Krahenbuhl, Darrell
"The ability of the Generative Adversarial Networks framework to learn generative models mapping from simple latent distributions to arbitrarily complex data distributions has been demonstrated empirically, with compelling results showing generators learn to “linearize semantics” in the latent space of such models. Intuitively, such latent spaces may serve as useful feature representations for auxiliary problems where semantics are relevant. However, in their existing form, GANs have no means of learning the inverse mapping – projecting data back into the latent space. We propose Bidirectional Generative Adversarial Networks (BiGANs) as a means of learning this inverse mapping, and demonstrate that the resulting learned feature representation is useful for auxiliary supervised discrimination tasks, competitive with contemporary approaches to unsupervised and self-supervised feature learning."
videohttps://youtube.com/watch?v=yyl0-y-k4Nc (Courville)posthttp://inference.vc/variational-inference-using-implicit-models-part-iii-joint-contrastive-inference-ali-and-bigan/
"Adversarial Variational Bayes: Unifying Variational Autoencoders and Generative Adversarial Networks" Mescheder, Nowozin, Geiger
"Variational Autoencoders are expressive latent variable models that can be used to learn complex probability distributions from training data. However, the quality of the resulting model crucially relies on the expressiveness of the inference model used during training. We introduce Adversarial Variational Bayes, a technique for training Variational Autoencoders with arbitrarily expressive inference models. We achieve this by introducing an auxiliary discriminative network that allows to rephrase the maximum-likelihood-problem as a two-player game, hence establishing a principled connection between VAEs and Generative Adversarial Networks. We show that in the nonparametric limit our method yields an exact maximumlikelihood assignment for the parameters of the generative model, as well as the exact posterior distribution over the latent variables given an observation. Contrary to competing approaches which combine VAEs with GANs, our approach has a clear theoretical justification, retains most advantages of standard Variational Autoencoders and is easy to implement."
"We presented a new training procedure for Variational Autoencoders based on adversarial training. This allows us to make the inference model much more flexible, effectively allowing it to represent almost any family of conditional distributions over the latent variables."
"Adversarial Variational Bayes strives to optimize the same objective as a standard Variational Autoencoder, but approximates the Kullback-Leibler divergence using an adversary instead of relying on a closed-form formula."
"However, no other approach we are aware of allows to use black-box inference models parameterized by a general neural network that takes as input a data point and a noise vector and produces a sample from the approximate posterior."
"Interestingly, the approach of Adversarial Autoencoders can be regarded as an approximation to our approach, where T(x,z) is restricted to the class of functions that do not depend on x."
"BiGANs are a recent extension of generative adversarial networks with the goal to add an inference network to the generative model. Similarly to our approach, the authors introduce an adversary that acts on pairs (x,z) of data points and latent codes. However, whereas in BiGANs the adversary is used to optimize the generative and inference networks separately, our approach optimizes the generative and inference model jointly. As a result, our approach obtains good reconstructions of the input data, whereas for BiGANs we obtain these reconstruction only indirectly."
"We often want to work with some Bayesian model but find its posterior distribution intractable. Variational inference is a way of coping with this problem. We learn an approximate posterior distribution, call it q(z|x), (along with the original model) by optimizing the following lowerbound:
log p(x|θ) ≥ ∫ q(z) log [p(x,z|θ) / q(z)] dz = E[log p(x|z,θ)] - E[log q(z|x)/p(z)]
where the expectations are taken with respect to the approximate posterior q. Usually we pick some known, common distribution q and optimize our hearts out. However, picking an appropriate q can be a challenge since we don't know what the true posterior really looks like and if we did, there'd be no need for variational inference. The clever trick with AVB is that the authors noticed that if the log [q(z|x)/p(z)] term can be replaced by something that doesn't require q(z|x) to be evaluated (i.e. to compute the actual probability), then the variational inference objective only requires that q(z|x) be sampled from, which can be done by a GAN-like generator network z = f(y) where y ~ N(0,1) and f is the neural network. They get around evaluating q by using a discriminator network to model the ratio directly."
"Real NVP can be used as an encoder in order to measure the gap between the unbiased KL estimate log q(z|x) - log p(z) and its approximation from GAN. We show that Adversarial Variational Bayes underestimates the KL divergence."
videohttps://youtu.be/y7pUN2t5LrA?t=14m19s (Nowozin)videohttps://youtu.be/xFCuXE1Nb8w?t=26m55s (Nowozin)videohttps://youtu.be/m80Vp-jz-Io?t=1h28m34s (Tolstikhin)posthttp://inference.vc/variational-inference-with-implicit-models-part-ii-amortised-inference-2/posthttps://chrisorm.github.io/AVB-pyt.htmlnoteshttps://casmls.github.io/general/2017/02/23/modified-gans.htmlcodehttps://github.com/wiseodd/generative-models/tree/master/VAE/adversarial_vbcodehttps://gist.github.com/poolio/b71eb943d6537d01f46e7b20e9225149
interesting recent papers
interesting recent papers - generative models
"This paper shows how Long Short-term Memory recurrent neural networks can be used to generate complex sequences with long-range structure, simply by predicting one data point at a time. The approach is demonstrated for text (where the data are discrete) and online handwriting (where the data are real-valued). It is then extended to handwriting synthesis by allowing the network to condition its predictions on a text sequence. The resulting system is able to generate highly realistic cursive handwriting in a wide variety of styles."
"Recurrent neural networks are a rich class of dynamic models that have been used to generate sequences in domains as diverse as music, text and motion capture data. RNNs can be trained for sequence generation by processing real data sequences one step at a time and predicting what comes next. Assuming the predictions are probabilistic, novel sequences can be generated from a trained network by iteratively sampling from the network's output distribution, then feeding in the sample as input at the next step. In other words, by making the network treat its inventions as if they were real, much like a person dreaming. Although the network itself is deterministic, the stochasticity injected by picking samples induces a distribution over sequences. This distribution is conditional, since the internal state of the network, and hence its predictive distribution, depends on the previous inputs. RNNs are ‘fuzzy’ in the sense that they do not use exact templates from the training data to make predictions, but rather - like other neural networks - use their internal representation to perform a high-dimensional interpolation between training examples. This distinguishes them from n-gram models and compression algorithms such as Prediction by Partial Matching, whose predictive distributions are determined by counting exact matches between the recent history and the training set. The result - which is immediately apparent from the samples in this paper - is that RNNs (unlike template-based algorithms) synthesise and reconstitute the training data in a complex way, and rarely generate the same thing twice. Furthermore, fuzzy predictions do not suffer from the curse of dimensionality, and are therefore much better at modelling real-valued or multivariate data than exact matches."
"In principle a large enough RNN should be sufficient to generate sequences of arbitrary complexity. In practice however, standard RNNs are unable to store information about past inputs for very long. As well as diminishing their ability to model long-range structure, this ‘amnesia’ makes them prone to instability when generating sequences. The problem (common to all conditional generative models) is that if the network’s predictions are only based on the last few inputs, and these inputs were themselves predicted by the network, it has little opportunity to recover from past mistakes. Having a longer memory has a stabilising effect, because even if the network cannot make sense of its recent history, it can look further back in the past to formulate its predictions. The problem of instability is especially acute with real-valued data, where it is easy for the predictions to stray from the manifold on which the training data lies. One remedy that has been proposed for conditional models is to inject noise into the predictions before feeding them back into the model, thereby increasing the model’s robustness to surprising inputs. However we believe that a better memory is a more profound and effective solution."
- http://distill.pub/2016/handwriting/ (demo)
- http://www.cs.toronto.edu/~graves/handwriting.html (demo)
videohttp://youtube.com/watch?v=-yX1SYeDHbg (Graves)noteshttps://github.com/tensorflow/magenta/blob/master/magenta/reviews/summary_generation_sequences.mdposthttp://blog.otoro.net/2015/12/12/handwriting-generation-demo-in-tensorflow/codehttps://github.com/hardmaru/write-rnn-tensorflow
"Deep AutoRegressive Networks" Gregor, Danihelka, Mnih, Blundell, Wierstra
"We introduce a deep, generative autoencoder capable of learning hierarchies of distributed representations from data. Successive deep stochastic hidden layers are equipped with autoregressive connections, which enable the model to be sampled from quickly and exactly via ancestral sampling. We derive an efficient approximate parameter estimation method based on the minimum description length (MDL) principle, which can be seen as maximising a variational lower bound on the log-likelihood, with a feedforward neural network implementing approximate inference. We demonstrate state-of-the-art generative performance on a number of classic data sets: several UCI data sets, MNIST and Atari 2600 games."
"In this paper we introduced deep autoregressive networks, a new deep generative architecture with autoregressive stochastic hidden units capable of capturing high-level structure in data to generate high-quality samples. The method, like the ubiquitous autoencoder framework, is comprised of not just a decoder (the generative element) but a stochastic encoder as well to allow for efficient and tractable inference. Training proceeds by backpropagating an MDL cost through the joint model, which approximately equates to minimising the Helmholtz variational free energy. This procedure necessitates backpropagation through stochastic units, as such yielding an approximate Monte Carlo method. The model samples efficiently, trains efficiently and is scalable to locally connected and/or convolutional architectures."
"Directed generative models provide a fully probabilistic account of observed random variables and their latent representations. Typically either the mapping from observation to representation or representation to observation is intractable and hard to approximate efficiently. In contrast, autoencoders provide an efficient two-way mapping where an encoder maps observations to representations and a decoder maps representations back to observations. Recently several authors have developed probabilistic versions of regularised autoencoders, along with means of generating samples from such models. These sampling procedures are often iterative, producing correlated approximate samples from previous approximate samples, and as such explore the full distribution slowly, if at all. In this paper, we introduce deep generative autoencoders that in contrast to the aforementioned models efficiently generate independent, exact samples via ancestral sampling. To produce a sample, we simply perform a top-down pass through the decoding part of our model, starting at the deepest hidden layer and sampling one unit at a time, layer-wise. Training a DARN proceeds by minimising the total information stored for reconstruction of the original input, and as such follows the minimum description length principle. This amounts to backpropagating an MDL cost through the entire joint encoder/decoder. Learning to encode and decode observations according to a compression metric yields representations that can be both concise and irredundant from an information theoretic point of view. Due to the equivalence of compression and prediction, compressed representations are good for making predictions and hence also good for generating samples. Unlike many other variational learning algorithms, our algorithm is not an expectation maximisation algorithm, but rather a stochastic gradient descent method, jointly optimising all parameters of the autoencoder simultaneously. DARN and its learning algorithm easily stack, allowing ever deeper representations to be learnt, whilst at the same time compressing the training data - DARN allows for alternating layers of stochastic hidden units and deterministic non-linearities. Recently, several authors have exploited autoregression for distribution modelling. Unlike these models, DARN can have stochastic hidden units, and places autoregressive connections among these hidden units. Depending upon the architecture of the network, this can yield gains in both statistical and computational efficiency."
"When compared to sigmoid belief networks that make use of mean-field approximations, deep auto-regressive networks use a posterior approximation with an autoregressive dependency structure that provides a clear improvement in performance."
videohttps://youtu.be/-yX1SYeDHbg?t=49m25s + https://youtu.be/P78QYjWh5sM?t=20m50s (demo)videohttp://techtalks.tv/talks/deep-autoregressive-networks/60884/ (Gregor)videohttp://youtube.com/watch?v=P78QYjWh5sM (Gregor)videohttp://techtalks.tv/beta/talks/neural-variational-inference-and-learning-in-belief-networks/60886/ (Mnih)
"MADE: Masked Autoencoder for Distribution Estimation" Germain, Gregor, Murray, Larochelle
"There has been a lot of recent interest in designing neural network models to estimate a distribution from a set of examples. We introduce a simple modification for autoencoder neural networks that yields powerful generative models. Our method masks the autoencoder’s parameters to respect autoregressive constraints: each input is reconstructed only from previous inputs in a given ordering. Constrained this way, the autoencoder outputs can be interpreted as a set of conditional probabilities, and their product, the full joint probability. We can also train a single network that can decompose the joint probability in multiple different orderings. Our simple framework can be applied to multiple architectures, including deep ones. Vectorized implementations, such as on GPUs, are simple and fast. Experiments demonstrate that this approach is competitive with state-of-the-art tractable distribution estimators. At test time, the method is significantly faster and scales better than other autoregressive estimators."
"We proposed MADE, a simple modification of autoencoders allowing them to be used as distribution estimators. MADE demonstrates that it is possible to get direct, cheap estimates of a high-dimensional joint probabilities, from a single pass through an autoencoder. Like standard autoencoders, our extension is easy to vectorize and implement on GPUs. MADE can evaluate high-dimensional probably distributions with better scaling than before, while maintaining state-of-the-art statistical performance."
videohttp://videolectures.net/icml2015_germain_distribution_estimation/ (Germain)videohttp://www.fields.utoronto.ca/video-archive/2017/01/2267-16372 (Larochelle)videohttp://videolectures.net/deeplearning2015_larochelle_deep_learning/ (Larochelle)posthttps://lilianweng.github.io/lil-log/2018/10/13/flow-based-deep-generative-models.html#madeposthttp://bjlkeng.github.io/posts/autoregressive-autoencoders/posthttp://inference.vc/masked-autoencoders-icml-paper-highlight/noteshttps://casmls.github.io/general/2016/11/19/MADENADE.htmlcodehttps://github.com/ikostrikov/pytorch-flowscodehttps://github.com/karpathy/pytorch-made
"Neural Autoregressive Distribution Estimation" Uria, Cote, Gregor, Murray, Larochelle
"We present Neural Autoregressive Distribution Estimation (NADE) models, which are neural network architectures applied to the problem of unsupervised distribution and density estimation. They leverage the probability product rule and a weight sharing scheme inspired from restricted Boltzmann machines, to yield an estimator that is both tractable and has good generalization performance. We discuss how they achieve competitive performance in modeling both binary and real-valued observations. We also present how deep NADE models can be trained to be agnostic to the ordering of input dimensions used by the autoregressive product rule decomposition. Finally, we also show how to exploit the topological structure of pixels in images using a deep convolutional architecture for NADE."
videohttp://www.fields.utoronto.ca/video-archive/2017/01/2267-16372 (Larochelle)noteshttps://casmls.github.io/general/2016/11/19/MADENADE.html
"DRAW: A Recurrent Neural Network For Image Generation" Gregor, Danihelka, Graves, Wierstra
"This paper introduces the Deep Recurrent Attentive Writer neural network architecture for image generation. DRAW networks combine a novel spatial attention mechanism that mimics the foveation of the human eye, with a sequential variational auto-encoding framework that allows for the iterative construction of complex images. The system substantially improves on the state of the art for generative models on MNIST, and, when trained on the Street View House Numbers dataset, it generates images that cannot be distinguished from real data with the naked eye."
"The core of the DRAW architecture is a pair of recurrent neural networks: an encoder network that compresses the real images presented during training, and a decoder that reconstitutes images after receiving codes. The combined system is trained end-to-end with stochastic gradient descent, where the loss function is a variational upper bound on the log-likelihood of the data. It therefore belongs to the family of variational auto-encoders, a recently emerged hybrid of deep learning and variational inference that has led to significant advances in generative modelling. Where DRAW differs from its siblings is that, rather than generating images in a single pass, it iteratively constructs scenes through an accumulation of modifications emitted by the decoder, each of which is observed by the encoder."
"An obvious correlate of generating images step by step is the ability to selectively attend to parts of the scene while ignoring others. A wealth of results in the past few years suggest that visual structure can be better captured by a sequence of partial glimpses, or foveations, than by a single sweep through the entire image. The main challenge faced by sequential attention models is learning where to look, which can be addressed with reinforcement learning techniques such as policy gradients. The attention model in DRAW, however, is fully differentiable, making it possible to train with standard backpropagation. In this sense it resembles the selective read and write operations developed for the Neural Turing Machine."
"We also established that the two-dimensional differentiable attention mechanism embedded in DRAW is beneficial not only to image generation, but also to cluttered image classification."
videohttp://youtube.com/watch?v=Zt-7MI9eKEo (demo)videohttp://youtube.com/watch?v=P78QYjWh5sM&t=22m14s (Gregor)videohttp://videolectures.net/deeplearning2015_courville_autoencoder_extension/#t=4380 (Courville)posthttp://kvfrans.com/what-is-draw-deep-recurrent-attentive-writer/posthttp://blog.evjang.com/2016/06/understanding-and-implementing.htmlnoteshttp://github.com/tensorflow/magenta/blob/master/magenta/reviews/draw.mdnoteshttps://casmls.github.io/general/2016/10/16/attention_model.htmlnoteshttp://www.shortscience.org/paper?bibtexKey=conf/icml/GregorDGRW15codehttps://github.com/ikostrikov/TensorFlow-VAE-GAN-DRAW/blob/master/main-draw.pycodehttps://github.com/ericjang/draw
interesting recent papers on compute and memory architectures
interesting recent papers on meta-learning
"Dynamic Routing Between Capsules" Sabour, Frosst, Hinton
CapsNet
"A capsule is a group of neurons whose activity vector represents the instantiation parameters of a specific type of entity such as an object or object part. We use the length of the activity vector to represent the probability that the entity exists and its orientation to represent the instantiation paramters. Active capsules at one level make predictions, via transformation matrices, for the instantiation parameters of higher-level capsules. When multiple predictions agree, a higher level capsule becomes active. We show that a discrimininatively trained, multi-layer capsule system achieves state-of-the-art performance on MNIST and is considerably better than a convolutional net at recognizing highly overlapping digits. To achieve these results we use an iterative routing-by-agreement mechanism: A lower-level capsule prefers to send its output to higher level capsules whose activity vectors have a big scalar product with the prediction coming from the lower-level capsule."
"Dynamic routing can be viewed as a parallel attention mechanism that allows each capsule at one level to attend to some active capsules at the level below and to ignore others. This should allow the model to recognize multiple objects in the image even if objects overlap. The routing-by-agreement should make it possible to use a prior about shape of objects to help segmentation and it should obviate the need to make higher-level segmentation decisions in the domain of pixels."
"For thirty years, the state-of-the-art in speech recognition used hidden Markov models with Gaussian mixtures as output distributions. These models were easy to learn on small computers, but they had a representational limitation that was ultimately fatal: The one-of-n representations they use are exponentially inefficient compared with, say, a recurrent neural network that uses distributed representations. To double the amount of information that an HMM can remember about the string it has generated so far, we need to square the number of hidden nodes. For a recurrent net we only need to double the number of hidden neurons.
Now that convolutional neural networks have become the dominant approach to object recognition, it makes sense to ask whether there are any exponential inefficiencies that may lead to their demise. A good candidate is the difficulty that convolutional nets have in generalizing to novel viewpoints. The ability to deal with translation is built in, but for the other dimensions of an affine transformation we have to chose between replicating feature detectors on a grid that grows exponentially with the number of dimensions, or increasing the size of the labelled training set in a similarly exponential way. Capsules avoid these exponential inefficiencies by converting pixel intensities into vectors of instantiation parameters of recognized fragments and then applying transformation matrices to the fragments to predict the instantiation parameters of larger fragments. Transformation matrices that learn to encode the intrinsic spatial relationship between a part and a whole constitute viewpoint invariant knowledge that automatically generalizes to novel viewpoints.
Capsules make a very strong representational assumption: At each location in the image, there is at most one instance of the type of entity that a capsule represents. This assumption eliminates the binding problem and allows a capsule to use a distributed representation (its activity vector) to encode the instantiation parameters of the entity of that type at a given location. This distributed representation is exponentially more efficient than encoding the instantiation parameters by activating a point on a high-dimensional grid and with the right distributed representation, capsules can then take full advantage of the fact that spatial relationships can be modelled by matrix multiplies.
Capsules use neural activities that vary as viewpoint varies rather than trying to eliminate viewpoint variation from the activities. This gives them an advantage over "normalization" methods like spatial transformer networks: They can deal with multiple different affine transformations of different objects or object parts at the same time.
Research on capsules is now at a similar stage to research on recurrent neural networks for speech recognition at the beginning of this century. There are fundamental representational reasons for believing that it is a better approach but it probably requires a lot more small insights before it can out-perform a highly developed technology. The fact that a simple capsules system already gives unparalleled performance at segmenting overlapping digits is an early indication that capsules are a direction worth exploring."
"Hinton says pooling in ConvNets (i.e. max. or avg. pooling) is bad because it introduces pose invariance by throwing away a bit of affine transformational information each time instead of separating it. This kind of pooling is also biologically implausible because we can determine the poses of objects very precisely. Hinton provides empirical evidence that our brains impose coordinate frames on objects and object parts to represent their poses. He concludes that, if this kind of coordinate frame representation is out of reach of a simple learning algorithm (such as backprop), then the brain likely has architectural features that help it learn to construct objects by part-whole relations using local coordinate frames in a hierarchical manner (which is pretty much how objects are constructed in computer graphics). Based on that he devises a new ConvNet architecture in which entities for objects and object parts are represented by capsules (which possibly correspond to cortical mini-columns). Each capsule basically learns to broadcast votes for the poses of the parent capsules by matrix multiplying its own pose with the learned affine relations to each parent capsules. A parent capsule then simply collects all votes and looks for agreements of just a handful of votes (a Hough transform). That is sufficient because the pose information is fairly high-dimensional, so just a few agreements would already be significant. Based on that, the capsule then sends again votes for the poses of entities it can be part of and so on."
"The core idea of capsules is that low level features predict the existence and pose of higher level features; collisions are non-coincidental. E.g. paw HERE predicts tiger THERE, nose HERE predicts tiger THERE, stripe HERE predicts tiger THERE - paw and nose and stripe predict tiger in the SAME PLACE! That's unlikely to be a coincidence, there's probably a tiger.
The core idea of pooling is that high level features are correlated with the existence of low-level features across sub-regions. E.g. I see a paw and a nose and a stripe - I guess we've got some tigers up in this. Even if the paw predicts a Tiger Rampant and the nose predicts a Tiger Face-On and the stripe predicts a Tiger Sideways. Hence CNN's disastrous vulnerability to adversarial stimuli."
"A fully connected layer would route the features based on their agreement with a learned weight vector. This defeats the intent of dynamic routing, the whole purpose of which is to route activations to capsules where they agree with other activations. It does the routing based on a fast iterative process in the forward pass, not a slow learning process like gradient descent."
"- requires less training data
- position and pose information are preserved (equivarience)
- promising for image segmentation and object detection
- routing by agreement is great for overlapping objects (explaining away)
- capsule activations nicely map the hierarchy of parts
- offers robustness to affine transformations
- activation vectors are easier to interpret (rotation, thickness, skew)"
videohttps://youtube.com/watch?v=gq-7HgzfDBMvideohttps://facebook.com/nipsfoundation/videos/1553634558061111?t=5824 (Frosst)video"What is wrong with convolutional neural nets?" (Hinton)video"What's wrong with convolutional nets?" (Hinton) (transcription)video"Does the Brain do Inverse Graphics?" (Hinton)videohttps://youtube.com/watch?v=pPN8d0E3900 (Geron)videohttps://youtube.com/watch?v=EATWLTyLfmc (Canziani)videohttps://youtube.com/watch?v=hYt3FcJUf6w (Uziela)videohttps://youtube.com/watch?v=VKoLGnq15RM (Raval)videohttps://youtube.com/watch?v=UZ9BgrofhKk (Kozlov)in russianvideohttps://youtube.com/watch?v=8R3gXmh1F0c (Lykov)in russianposthttps://oreilly.com/ideas/introducing-capsule-networksposthttps://medium.com/@pechyonkin/understanding-hintons-capsule-networks-part-i-intuition-b4b559d1159bposthttps://hackernoon.com/uncovering-the-intuition-behind-capsule-networks-and-inverse-graphics-part-i-7412d121798dposthttps://jhui.github.io/2017/11/03/Dynamic-Routing-Between-Capsules/posthttps://hackernoon.com/what-is-a-capsnet-or-capsule-network-2bfbe48769ccposthttps://medium.com/@mike_ross/a-visual-representation-of-capsule-network-computations-83767d79e737noteshttps://blog.acolyer.org/2017/11/13/dynamic-routing-between-capsules/codehttps://github.com/ageron/handson-ml/blob/master/extra_capsnets.ipynbcodehttps://github.com/Sarasra/models/tree/master/research/capsulescodehttps://github.com/loretoparisi/CapsNetpaper"Transforming Auto-encoders" by Hinton, Krizhevsky, Wangpaper"Optimizing Neural Networks that Generate Images" by Tieleman (code)
"Matrix Capsules with EM Routing" Hinton, Sabour, Frosst
CapsNet
"A capsule is a group of neurons whose outputs represent different properties of the same entity. Each layer in a capsule network contains many capsules [a group of capsules forms a capsule layer and can be used in place of a traditional layer in a neural net]. We describe a version of capsules in which each capsule has a logistic unit to represent the presence of an entity and a 4x4 matrix which could learn to represent the relationship between that entity and the viewer (the pose). A capsule in one layer votes for the pose matrix of many different capsules in the layer above by multiplying its own pose matrix by trainable viewpoint-invariant transformation matrices that could learn to represent part-whole relationships. Each of these votes is weighted by an assignment coefficient. These coefficients are iteratively updated for each image using the Expectation-Maximization algorithm such that the output of each capsule is routed to a capsule in the layer above that receives a cluster of similar votes. The transformation matrices are trained discriminatively by backpropagating through the unrolled iterations of EM between each pair of adjacent capsule layers. On the smallNORB benchmark, capsules reduce the number of test errors by 45% compared to the state-of-the-art. Capsules also show far more resistance to white box adversarial attack than our baseline convolutional neural network."
videohttps://youtu.be/hYt3FcJUf6w?t=50m38s (Uziela)posthttps://jhui.github.io/2017/11/14/Matrix-Capsules-with-EM-routing-Capsule-Network/posthttps://towardsdatascience.com/demystifying-matrix-capsules-with-em-routing-part-1-overview-2126133a8457noteshttps://blog.acolyer.org/2017/11/14/matrix-capsules-with-em-routing/codehttps://github.com/loretoparisi/CapsNet
"Highway Networks" Srivastava, Greff, Schmidhuber
"There is plenty of theoretical and empirical evidence that depth of neural networks is a crucial ingredient for their success. However, network training becomes more difficult with increasing depth and training of very deep networks remains an open problem. In this extended abstract, we introduce a new architecture designed to ease gradient-based training of very deep networks. We refer to networks with this architecture as highway networks, since they allow unimpeded information flow across several layers on information highways. The architecture is characterized by the use of gating units which learn to regulate the flow of information through a network. Highway networks with hundreds of layers can be trained directly using stochastic gradient descent and with a variety of activation functions, opening up the possibility of studying extremely deep and efficient architectures."
"Highway Networks have a gated connection in the depth dimension analogous to the gated connection LSTMs have in the time dimension. There are also Grid LSTMs, which have these gated connections in both dimensions."
posthttp://people.idsia.ch/~rupesh/very_deep_learning/videohttp://research.microsoft.com/apps/video/default.aspx?id=259633 (9:00) (Srivastava)posthttps://medium.com/jim-fleming/highway-networks-with-tensorflow-1e6dfa667daacodehttps://theneuralperspective.com/2016/12/13/highway-networks/codehttps://github.com/LeavesBreathe/tensorflow_with_latest_papers/blob/master/highway_network_modern.py
"Deep Residual Learning for Image Recognition" He, Zhang, Ren, Sun
"Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers---8x deeper than VGG nets but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers. The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions, where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation."
"One solution for vanishing gradients is residual networks, which has been applied most famously to CNNs such that training neural networks hundreds of layers deep remains feasible. The idea is relatively simple. By default, we like the idea of a layer computing an identity function. This makes sense. If you do well with one layer, you don't expect a two or three to do worse. At worst, the second and third layer should just learn to "copy" the output of the first layer - no modifications. Hence, they just need to learn an identity function. Unfortunately, learning the identity function seems non-trivial for most networks. Even worse, later layers confuse training of earlier layers as the supervision signal - the direction it's meant to go - keeps shifting. As such, the first layer may fail to train well at all if there are more layers below it. To solve this, we bias the architecture of each of these layers towards performing the identity function. We can do this by only allowing the later layers to add deltas (updates) to the existing vector. Now, if the next layer is lazy and outputs nothing but zeroes, that's fine, as you'll still have the original vector."
"In a conventional MLP or convnet, only consecutive layers are compatible because of permutation symmetries: even if a layer doesn't do much useful computation, it still randomly permutes all its inputs, so if you take it out the next layer will get inputs shuffled in the wrong order. In a ResNet (or other passthrough network like a Highway Net or a feed-forward LSTM with untied weights), instead, all the hidden layers must use compatible representations."
"Highway Networks have a gated connection in the depth dimension analogous to the gated connection LSTMs have in the time dimension. But people are comparing deep residual networks to highway networks, saying it's like highway networks without the gate, with the path always open."
"There is a minor yet important difference between Highway Networks and ResNets. Highway type gating means it is a smooth but exclusive OR gate. ResNets are like AND gates."
videohttp://techtalks.tv/talks/deep-residual-networks-deep-learning-gets-way-deeper/62358/ (He)videohttp://youtube.com/watch?v=1PGLj-uKT1w (He)posthttp://people.idsia.ch/~juergen/microsoft-wins-imagenet-through-feedforward-LSTM-without-gates.html (Schmidhuber)posthttps://blog.init.ai/residual-neural-networks-are-an-exciting-area-of-deep-learning-research-acf14f4912e9noteshttp://www.shortscience.org/paper?bibtexKey=journals/corr/HeZRS15codehttps://github.com/tensorflow/models/tree/master/research/resnet
"Residual Networks are Exponential Ensembles of Relatively Shallow Networks" Veit, Wilber, Belongie
"In this work, we introduce a novel interpretation of residual networks showing they are exponential ensembles. This observation is supported by a large-scale lesion study that demonstrates they behave just like ensembles at test time. Subsequently, we perform an analysis showing these ensembles mostly consist of networks that are each relatively shallow. For example, contrary to our expectations, most of the gradient in a residual network with 110 layers comes from an ensemble of very short networks, i.e., only 10-34 layers deep. This suggests that in addition to describing neural networks in terms of width and depth, there is a third dimension: multiplicity, the size of the implicit ensemble. Ultimately, residual networks do not resolve the vanishing gradient problem by preserving gradient flow throughout the entire depth of the network – rather, they avoid the problem simply by ensembling many short networks together. This insight reveals that depth is still an open research question and invites the exploration of the related notion of multiplicity."
"Hinton et al. show that dropping out individual neurons during training leads to a network which is equivalent to averaging over an ensemble of exponentially many networks. Similar in spirit, stochastic depth trains an ensemble of networks by dropping out entire layers during training. These two strategies are “ensembles by training” because the ensemble arises only as a result of the special training strategy. However, we show that residual networks are “ensembles by construction” as a natural result of the structure of the architecture."
"Deleting a layer in residual networks at test time (a) is equivalent to zeroing half of the paths. In ordinary feed-forward networks (b) such as VGG or AlexNet, deleting individual layers alters the only viable path from input to output."
"Recently, an alternative training procedure for residual networks has been proposed, referred to as stochastic depth. In that approach a random subset of the residual modules is selected for each mini-batch during training. The forward and backward pass is only performed on those modules. Stochastic depth does not affect the multiplicity of the network because all paths are available at test time. However, it shortens the paths seen during training. Further, by selecting a different subset of short paths in each mini-batch, it encourages the paths to independently produce good results. We repeat the experiment of deleting individual modules for a residual network trained using stochastic depth. Training with stochastic depth improves resilience slightly; only the dependence on the downsampling layers seems to be reduced. By now, this is not surprising: we know that residual networks are “ensembles by construction.” Special training procedures such as stochastic depth are not what induce the ensemble. Rather, they only encourage its members to be more independent."
"It is not depth, but the ensemble that makes residual networks strong. In the most recent iteration of residual networks, He et al. claim “We obtain these results via a simple but essential concept - going deeper. These results demonstrate the potential of pushing the limits of depth.” We now know that this is not quite right. Residual networks push the limits of network multiplicity, not network depth. Our proposed unraveled view and the lesion study show that residual networks are an implicit ensemble of exponentially many networks. Further, the paths through the network that contribute gradient are shorter than expected, because deep paths do not contribute any gradient during training due to vanishing gradients. If most of the paths that contribute gradient are very short compared to the overall depth of the network, increased depth alone can’t be the key characteristic of residual networks. We now believe that multiplicity, the network’s expressability in the terms of the number of paths, plays a key role."
videohttps://youtube.com/watch?v=jFJF5hXuo0svideohttps://youtu.be/Jh3D8Gi4N0I?t=13m13s (Novikov)in russian
"Spatial Transformer Networks" Jaderberg, Simonyan, Zisserman, Kavukcuoglu
"Convolutional Neural Networks define an exceptionally powerful class of models, but are still limited by the lack of ability to be spatially invariant to the input data in a computationally and parameter efficient manner. In this work we introduce a new learnable module, the Spatial Transformer, which explicitly allows the spatial manipulation of data within the network. This differentiable module can be inserted into existing convolutional architectures, giving neural networks the ability to actively spatially transform feature maps, conditional on the feature map itself, without any extra training supervision or modification to the optimisation process. We show that the use of spatial transformers results in models which learn invariance to translation, scale, rotation and more generic warping, resulting in state-of-the-art performance on several benchmarks, and for a number of classes of transformations."
videohttps://youtu.be/T5k0GnBmZVI?t=1m9s (Jaderberg)videohttps://youtu.be/_XRBlhzb31U?t=1h9m29s (Figurnov)in russiancodehttps://github.com/tensorflow/models/tree/master/research/transformer
"Training Recurrent Networks Online without Backtracking" Ollivier, Tallec, Charpiat
"We introduce the "NoBackTrack" algorithm to train the parameters of dynamical systems such as recurrent neural networks. This algorithm works in an online, memoryless setting, thus requiring no backpropagation through time, and is scalable, avoiding the large computational and memory cost of maintaining the full gradient of the current state with respect to the parameters. The algorithm essentially maintains, at each time, a single search direction in parameter space. The evolution of this search direction is partly stochastic and is constructed in such a way to provide, at every time, an unbiased random estimate of the gradient of the loss function with respect to the parameters. Because the gradient estimate is unbiased, on average over time the parameter is updated as it should. The resulting gradient estimate can then be fed to a lightweight Kalman-like filter to yield an improved algorithm. For recurrent neural networks, the resulting algorithms scale linearly with the number of parameters. Small-scale experiments confirm the suitability of the approach, showing that the stochastic approximation of the gradient introduced in the algorithm is not detrimental to learning. In particular, the Kalman-like version of NoBackTrack is superior to backpropagation through time when the time span of dependencies in the data is longer than the truncation span for BPTT."
"For recurrent neural networks, the computational cost of this algorithm is comparable to that of running the network itself. Previously known algorithms were either not fully online or had a significantly higher computational cost. In our experiments, this algorithm appears as a practical alternative to truncated backpropagation through time, especially in its Kalman version, while the Euclidean version requires smaller learning rates. The (unbiased) noise and rank reduction introduced in the gradient approximation do not appear to prevent learning. The interest of NoBackTrack with respect to truncated BPTT depends on the situation at hand, especially on the scale of time dependencies in the data (which results in biased gradient estimates for BPTT), and on whether the storage of past states and past data required by truncated BPTT is acceptable or not."
"Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks" Graves, Fernandez, Gomez, Schmidhuber
"Many real-world sequence learning tasks require the prediction of sequences of labels from noisy, unsegmented input data. In speech recognition, for example, an acoustic signal is transcribed into words or sub-word units. Recurrent neural networks are powerful sequence learners that would seem well suited to such tasks. However, because they require pre-segmented training data, and post-processing to transform their outputs into label sequences, their applicability has so far been limited. This paper presents a novel method for training RNNs to label unsegmented sequences directly, thereby solving both problems. An experiment on the TIMIT speech corpus demonstrates its advantages over both a baseline HMM and a hybrid HMM-RNN."
"CTC is a type of neural network output and associated scoring function, for training recurrent neural networks such as LSTM networks to tackle sequence problems where the timing is variable. It can be used for tasks like recognising phonemes in speech audio. CTC refers to the outputs and scoring, and is independent of the underlying neural network structure. A CTC network has a continuous output (e.g. softmax), which is fitted through training to model the probability of a label. The input is a sequence of observations, and the outputs are a sequence of labels, which can include blank outputs. CTC does not attempt to learn boundaries and timings: Label sequences are considered equivalent if they differ only in alignment, ignoring blanks. Equivalent label sequences can occur in many ways – which makes scoring a non-trivial task. Fortunately there is an efficient forward-backwards algorithm. CTC scores can then be used with the back-propagation algorithm to update the neural network weights."
videohttps://youtube.com/watch?v=e0ia-mN-7Kk (Ding, Brigden)videohttps://youtube.com/watch?v=UMxvZ9qHwJs (Gharbieh)posthttps://distill.pub/2017/ctc/posthttps://machinethoughts.wordpress.com/2017/11/02/ctc-training-latent-discrete-sequential-decisions-without-rl/
"Sequence to Sequence Learning with Neural Networks" Sutskever, Vinyals, Le
"Deep Neural Networks are powerful models that have achieved excellent performance on difficult learning tasks. Although DNNs work well whenever large labeled training sets are available, they cannot be used to map sequences to sequences. In this paper, we present a general end-to-end approach to sequence learning that makes minimal assumptions on the sequence structure. Our method uses a multilayered Long Short-Term Memory to map the input sequence to a vector of a fixed dimensionality, and then another deep LSTM to decode the target sequence from the vector. Our main result is that on an English to French translation task from the WMT-14 dataset, the translations produced by the LSTM achieve a BLEU score of 34.7 on the entire test set, where the LSTM's BLEU score was penalized on out-of-vocabulary words. Additionally, the LSTM did not have difficulty on long sentences. For comparison, a strong phrase-based SMT system achieves a BLEU score of 33.3 on the same dataset. When we used the LSTM to rerank the 1000 hypotheses produced by the aforementioned SMT system, its BLEU score increases to 36.5, which beats the previous state of the art. The LSTM also learned sensible phrase and sentence representations that are sensitive to word order and are relatively invariant to the active and the passive voice. Finally, we found that reversing the order of the words in all source sentences (but not target sentences) improved the LSTM's performance markedly, because doing so introduced many short term dependencies between the source and the target sentence which made the optimization problem easier."
Geoffrey Hinton:
"You feed the sequence of words in an English sentence to the English encoder LSTM. The final hidden state of the encoder is the neural network's representation of the "thought" that the sentence expresses. You then make that thought be the initial state of the decoder LSTM for French. The decoder then outputs a probability distribution over French words that might start the sentence. If you pick from this distribution and make the word you picked be the next input to the decoder, it will then produce a probability distribution for the second word. You keep on picking words and feeding them back in until you pick a full stop. The process I just described defines a probability distribution across all French strings of words that end in a full stop. The log probability of a French string is just the sum of the log probabilities of the individual picks. To raise the log probability of a particular translation you just have to backpropagate the derivatives of the log probabilities of the individual picks through the combination of encoder and decoder. The amazing thing is that when an encoder and decoder net are trained on a fairly big set of translated pairs, the quality of the translations beats the former state-of-the-art for systems trained with the same amount of data. With more data and more research I'm pretty confident that the encoder-decoder pairs will take over in the next few years. There will be one encoder for each language and one decoder for each language and they will be trained so that all pairings work. One nice aspect of this approach is that it should learn to represent thoughts in a language-independent way and it will be able to translate between pairs of foreign languages without having to go via English. Another nice aspect is that it can take advantage of multiple translations. If a Dutch sentence is translated into Turkish and Polish and 23 other languages, we can backpropagate through all 25 decoders to get gradients for the Dutch encoder. This is like 25-way stereo on the thought. If 25 encoders and one decoder would fit on a chip, maybe it could go in your ear."
videohttp://research.microsoft.com/apps/video/?id=239083 (Sutskever)videohttp://youtube.com/watch?v=UdSK7nnJKHU (Sutskever)videohttp://youtube.com/watch?v=9U0drwafE78 (Vinyals)videohttp://youtube.com/watch?v=i2gzr1kXTxM (Vinyals)noteshttp://www.shortscience.org/paper?bibtexKey=conf/nips/SutskeverVL14codehttps://github.com/farizrahman4u/seq2seq
"Reward Augmented Maximum Likelihood for Neural Structured Prediction" Norouzi, Bengio, Chen, Jaitly, Schuster, Wu, Schuurmans
"Pointer Networks" Vinyals, Fortunato, Jaitly
"We introduce a new neural architecture to learn the conditional probability of an output sequence with elements that are discrete tokens corresponding to positions in an input sequence. Such problems cannot be trivially addressed by existent approaches such as sequence-to-sequence and Neural Turing Machines, because the number of target classes in each step of the output depends on the length of the input, which is variable. Problems such as sorting variable sized sequences, and various combinatorial optimization problems belong to this class. Our model solves the problem of variable size output dictionaries using a recently proposed mechanism of neural attention. It differs from the previous attention attempts in that, instead of using attention to blend hidden units of an encoder to a context vector at each decoder step, it uses attention as a pointer to select a member of the input sequence as the output. We call this architecture a Pointer Net. We show Ptr-Nets can be used to learn approximate solutions to three challenging geometric problems - finding planar convex hulls, computing Delaunay triangulations, and the planar Travelling Salesman Problem - using training examples alone. Ptr-Nets not only improve over sequence-to-sequence with input attention, but also allow us to generalize to variable size output dictionaries. We show that the learnt models generalize beyond the maximum lengths they were trained on. We hope our results on these tasks will encourage a broader exploration of neural learning for discrete problems."
"We adapted the attention mechanism of the sequence-to-sequence framework to make it possible for the model to output pointers to inputs -- we call this architecture Pointer-Net. By doing so, we were able to approximately solve problems involving geometry such as small instances of the Traveling Salesman Problem or Delaunay triangulations solely from data. Our net naturally deals with variable sized problem instances, and generalizes well beyond what’s been trained on."
"We propose a new architecture, that we call Pointer Net, which is simple and effective. It deals with the fundamental problem of representing variable length dictionaries by using a softmax probability distribution as a “pointer”. We apply the Pointer Net model to three distinct non-trivial algorithmic problems involving geometry. We show that the learned model generalizes to test problems with more points than the training problems. Our Pointer Net model learns a competitive small scale (n<=50) TSP approximate solver. Our results demonstrate that a purely data driven approach can learn approximate solutions to problems that are computationally intractable."
"Our method works on variable sized inputs (yielding variable sized output dictionaries), something the baseline models (sequence-to-sequence with or without attention) cannot do directly. Even more impressively, they outperform the baselines on fixed input size problems - to which both the models can be applied. Our model draws inspiration from attention models and has strong connections to memory networks that use content based attention. We use these mechanisms to choose outputs from input locations, thus opening up a new class of problems to which neural networks can be applied without artificial assumptions. Future work will try and show its applicability to other problems such as sorting where the outputs are chosen from the inputs. We are also excited about the possibility of using this approach to other combinatorial optimization problems."
"Despite not having a memory, this model was able to solve a number of difficult algorithmic problems such as convex hull and approximate 2D TSP."
"In the pointer networks, the output space of the target sequence is constrained to be the observations in the input sequence (not the input space). And instead of having a fixed dimension softmax output layer, softmax outputs of varying dimension is dynamically computed for each input sequence in such a way to maximize the attention probability of the target input."
videohttp://youtube.com/watch?v=yS7rHi_lUGU (demo)videohttp://youtu.be/9U0drwafE78?t=44m30s (Vinyals)posthttp://fastml.com/introduction-to-pointer-networks/noteshttps://medium.com/@sharaf/a-paper-a-day-11-pointer-networks-59f7af1a611ccodehttps://github.com/ikostrikov/TensorFlow-Pointer-Networkscodehttps://github.com/devsisters/pointer-network-tensorflow
"Attention Is All You Need" Vaswani et al.
Transformer
"The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.0 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data."
"- constant path length between any two input positions
- gating/multiplication enables crisp error propagation
- trivial to parallelize
- can replace sequence-aligned recurrence entirely"
"multi-head attention:
- convolutions use different parameters per relative position
- allows identifying different information from different positions
- multiple attention layers in parallel achieve a similar effect
- projecting to fewer dimensions keeps computation ~ constant"
"trains >3x faster than GNMT and ConvSeq2Seq with better performance on machine translation problem"
"n - sequence length, d - representation dimension, k - convolution kernel size, r - neighborhood size
complexity per layer:
- self-attention: O(n^2*d)
- recurrent: O(n*d^2)
- convolutional: O(knd^2)
- self-attention (restricted): O(rnd)
sequential operations:- self-attention: O(1)
- recurrent: O(n)
- convolutional: O(1)
- self-attention (restricted): O(1)
maximum path integral:- self-attention: O(1)
- recurrent: O(n)
- convolutional: O(logk(n))
- self-attention (restricted): O(n/r)"
posthttps://research.googleblog.com/2017/08/transformer-novel-neural-network.htmlvideohttps://facebook.com/nipsfoundation/videos/1554654864625747?t=1107 (Vaswani, Shazeer)videohttps://youtu.be/I0nX4HDmXKc?t=7m46s (Polosukhin)videohttps://youtube.com/watch?v=rBCqOTEfxvg (Kaiser)videohttps://youtube.com/watch?v=iDulhoQ2pro (Kilcher)videohttps://youtu.be/_XRBlhzb31U?t=48m35s (Figurnov)in russianvideohttps://youtu.be/LhH6wMvntSM?t=54m56s (Suleymanov)in russianaudiohttps://soundcloud.com/nlp-highlights/36-attention-is-all-you-need-with-ashish-vaswani-and-jakob-uszkoreit (Vaswani, Uszkoreit)posthttps://jalammar.github.io/illustrated-transformer/posthttp://nlp.seas.harvard.edu/2018/04/03/attention.htmlposthttps://machinethoughts.wordpress.com/2017/09/01/deep-meaning-beyond-thought-vectors/noteshttps://ricardokleinklein.github.io/2017/11/16/Attention-is-all-you-need.htmlnoteshttps://blog.tomrochette.com/machine-learning/papers/ashish-vaswani-attention-is-all-you-neednoteshttps://medium.com/@sharaf/a-paper-a-day-24-attention-is-all-you-need-26eb2da90a91codehttps://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/transformer.pycodehttps://colab.research.google.com/notebook#fileId=/v2/external/notebooks/t2t/hello_t2t.ipynbcodehttps://github.com/jadore801120/attention-is-all-you-need-pytorch
"Gated Graph Sequence Neural Networks" Li, Zemel, Brockschmidt, Tarlow
"Graph-structured data appears frequently in domains including chemistry, natural language semantics, social networks, and knowledge bases. In this work, we study feature learning techniques for graph-structured inputs. Our starting point is previous work on Graph Neural Networks, which we modify to use gated recurrent units and modern optimization techniques and then extend to output sequences. The result is a flexible and broadly useful class of neural network models that has favorable inductive biases relative to purely sequence-based models (e.g., LSTMs) when the problem is graph-structured. We demonstrate the capabilities on some simple AI (bAbI) and graph algorithm learning tasks. We then show it achieves state-of-the-art performance on a problem from program verification, in which subgraphs need to be matched to abstract data structures."
"Many practical applications build on graph-structured data, and thus we often want to perform machine learning tasks that take graphs as inputs. Standard approaches to this problem include engineering custom features of an input graph, graph kernels, and methods that define graph features in terms of random walks on graphs. Our main contribution is an extension of Graph Neural Networks that outputs sequences. A secondary contribution is highlighting that Graph Neural Networks (and further extensions we develop here) are a broadly useful class of neural network model that is applicable to the problems currently facing the field. Previous work on feature learning for graph-structured inputs has focused on models that produce single outputs such as graph-level classifications, but many problems with graph inputs require outputting sequences. Examples include paths on a graph, enumerations of graph nodes with desirable properties, or sequences of global classifications mixed with, for example, a start and end node. We are not aware of existing graph feature learning work suitable for this problem. Our motivating application comes from program verification and requires outputting logical formulas, which we formulate as a sequential output problem."
"There are two settings for feature learning on graphs: (1) learning a representation of the input graph, and (2) learning representations of the internal state during the process of producing a sequence of outputs. Here, (1) is mostly achieved by previous work on Graph Neural Networks (Scarselli et al., 2009); we make several minor adaptations of this framework, including changing it to use modern practices around Recurrent Neural Networks. (2) is important because we desire outputs from graph-structured problems that are not solely individual classifications. In these cases, the challenge is how to learn features on the graph that encode the partial output sequence that has already been produced (e.g., the path so far if outputting a path) and that still needs to be produced (e.g., the remaining path). We will show how the GNN framework can be adapted to these settings, leading to a novel graph-based neural network model that we call Gated Graph Sequence Neural Networks."
"We discuss an application to the verification of computer programs. When attempting to prove properties such as memory safety (i.e., that there are no null pointer dereferences in a program), a core problem is to find mathematical descriptions of the data structures used in a program. Following Brockschmidt et al. (2015), we have phrased this as a machine learning problem where we will learn to map from a set of input graphs representing the state of memory to a logical description of the data structures that have been instantiated. Whereas Brockschmidt et al. (2015) relied on a large amount of hand-engineering of features, we show that the system can be replaced with a GGS-NN at no cost in accuracy."
"The results in the paper show that GGS-NNs have desirable inductive biases across a range of problems that have some intrinsic graph structure to them, and we believe there to be many more cases where GGS-NNs will be useful. There are, however, some limitations that need to be overcome to make them apply even more broadly. Two limitations that we mentioned previously are that the bAbI task translation does not incorporate temporal order of inputs or ternary and higher order relations. We can imagine several possibilities for lifting these restrictions, such as concatenating a series of GG-NNs, where there is one GG-NNs for each edge, and representing higher order relations as factor graphs. A more significant challenge is how to handle less structured input representations. For example, in the bAbI tasks it would be desirable not to use the symbolic form of the inputs. One possible approach is to incorporate less structured inputs, and latent vectors, in our GGS-NNs."
"The current GGS-NNs formulation specifies a question only after all the facts have been consumed. This implies that the network must try to derive all consequences of the seen facts and store all pertinent information to a node within its node representation. This is likely not ideal; it would be preferable to develop methods that take the question as an initial input, and then dynamically derive the facts needed to answer the question."
"We are particularly interested in continuing to develop end-to-end learnable systems that can learn about semantic properties of programs, that can learn more complicated graph algorithms, and in applying these ideas to problems that require reasoning over knowledge bases and databases. More generally, we consider these graph neural networks as representing a step towards a model that can combine structured representations with the powerful algorithms of deep learning, with the aim of taking advantage of known structure while learning and inferring how to reason with and extend these representations."
videohttps://youtu.be/pJ5EEesntbA?t=48m01s (Tarlow)videohttp://research.microsoft.com/apps/video/default.aspx?id=263975&r=1 (Li)
"End-To-End Memory Networks" Sukhbaatar, Szlam, Weston, Fergus
"We introduce a neural network with a recurrent attention model over a possibly large external memory. The architecture is a form of Memory Network but unlike the model in that work, it is trained end-to-end, and hence requires significantly less supervision during training, making it more generally applicable in realistic settings. It can also be seen as an extension of RNNsearch to the case where multiple computational steps (hops) are performed per output symbol. The flexibility of the model allows us to apply it to tasks as diverse as (synthetic) question answering and to language modeling. For the former our approach is competitive with Memory Networks, but with less supervision. For the latter, on the Penn TreeBank and Text8 datasets our approach demonstrates slightly better performance than RNNs and LSTMs. In both cases we show that the key concept of multiple computational hops yields improved results."
"In this work we showed that a neural network with an explicit memory and a recurrent attention mechanism for reading the memory can be sucessfully trained via backpropagation on diverse tasks from question answering to language modeling. Compared to the Memory Network implementation there is no supervision of supporting facts and so our model can be used in more realistic QA settings. Our model approaches the same performance of that model, and is significantly better than other baselines with the same level of supervision. On language modeling tasks, it slightly outperforms tuned RNNs and LSTMs of comparable complexity. On both tasks we can see that increasing the number of memory hops improves performance. However, there is still much to do. Our model is still unable to exactly match the performance of the memory networks trained with strong supervision, and both fail on several of the QA tasks. Furthermore, smooth lookups may not scale well to the case where a larger memory is required. For these settings, we plan to explore multiscale notions of attention or hashing."
videohttp://research.microsoft.com/apps/video/default.aspx?id=259920 (Sukhbaatar)videohttp://youtube.com/watch?v=8keqd1ewsno (Bordes)videohttp://youtube.com/watch?v=Xumy3Yjq4zk (Weston)videohttp://techtalks.tv/talks/memory-networks-for-language-understanding/62356/ (Weston)videohttp://youtu.be/jRkm6PXRVF8?t=17m51s (Weston)noteshttp://www.shortscience.org/paper?bibtexKey=conf/nips/SukhbaatarSWF15codehttps://github.com/fchollet/keras/blob/master/examples/babi_memnn.pycodehttps://github.com/carpedm20/MemN2N-tensorflowcodehttps://github.com/domluna/memn2n
"Towards Neural Network-based Reasoning" Peng, Lu, Li, Wong
"We propose Neural Reasoner, a framework for neural network-based reasoning over natural language sentences. Given a question, Neural Reasoner can infer over multiple supporting facts and find an answer to the question in specific forms. Neural Reasoner has 1) a specific interaction-pooling mechanism, allowing it to examine multiple facts, and 2) a deep architecture, allowing it to model the complicated logical relations in reasoning tasks. Assuming no particular structure exists in the question and facts, Neural Reasoner is able to accommodate different types of reasoning and different forms of language expressions. Despite the model complexity, Neural Reasoner can still be trained effectively in an end-to-end manner. Our empirical studies show that Neural Reasoner can outperform existing neural reasoning systems with remarkable margins on two difficult artificial tasks (Positional Reasoning and Path Finding) proposed. For example, it improves the accuracy on Path Finding (10K) from 33.4% to over 98%."
"We have proposed Neural Reasoner, a framework for neural network-based reasoning over natural language sentences. Neural Reasoner is flexible, powerful, and language indepedent. Our empirical studies show that Neural Reasoner can dramatically improve upon existing neural reasoning systems on two difficult artificial tasks. For future work, we will explore 1) tasks with higher difficulty and reasoning depth, e.g., tasks which require a large number of supporting facts and facts with complex intrinsic structures, 2) the common structure in different but similar reasoning tasks (e.g., multiple tasks all with general questions), and 3) automatic selection of the reasoning architecture, for example, determining when to stop the reasoning based on the data."
"similar to Memory Networks but with non-linear function to compute interaction between control state and memory slot"
"Learning to Transduce with Unbounded Memory" Grefenstette, Hermann, Suleyman, Blunsom
"Recently, strong results have been demonstrated by Deep Recurrent Neural Networks on natural language transduction problems. In this paper we explore the representational power of these models using synthetic grammars designed to exhibit phenomena similar to those found in real transduction problems such as machine translation. These experiments lead us to propose new memory-based recurrent networks that implement continuously differentiable analogues of traditional data structures such as Stacks, Queues, and DeQues. We show that these architectures exhibit superior generalisation performance to Deep RNNs and are often able to learn the underlying generating algorithms in our transduction experiments."
"The experiments performed in this paper demonstrate that single-layer LSTMs enhanced by an unbounded differentiable memory capable of acting, in the limit, like a classical Stack, Queue, or DeQue, are capable of solving sequence-to-sequence transduction tasks for which Deep LSTMs falter. Even in tasks for which benchmarks obtain high accuracies, the memory-enhanced LSTMs converge earlier, and to higher accuracies, while requiring considerably fewer parameters than all but the simplest of Deep LSTMs. We therefore believe these constitute a crucial addition to our neural network toolbox, and that more complex linguistic transduction tasks such as machine translation or parsing will be rendered more tractable by their inclusion."
"Machine translation is a prototypical example of transduction and recent results indicate that Deep RNNs have the ability to encode long source strings and produce coherent translations. While elegant, the application of RNNs to transduction tasks requires hidden layers large enough to store representations of the longest strings likely to be encountered, implying wastage on shorter strings and a strong dependency between the number of parameters in the model and its memory. In this paper we use a number of linguistically-inspired synthetic transduction tasks to explore the ability of RNNs to learn long-range reorderings and substitutions. Further, inspired by prior work on neural network implementations of stack data structures, we propose and evaluate transduction models based on Neural Stacks, Queues, and DeQues. Stack algorithms are well-suited to processing the hierarchical structures observed in natural language and we hypothesise that their neural analogues will provide an effective and learnable transduction tool. Our models provide a middle ground between simple RNNs and the recently proposed Neural Turing Machine which implements a powerful random access memory with read and write operations. Neural Stacks, Queues, and DeQues also provide a logically unbounded memory while permitting efficient constant time push and pop operations. Our results indicate that the models proposed in this work, and in particular the Neural DeQue, are able to consistently learn a range of challenging transductions. While Deep RNNs based on Long Short-Term Memory cells can learn some transductions when tested on inputs of the same length as seen in training, they fail to consistently generalise to longer strings. In contrast, our sequential memory-based algorithms are able to learn to reproduce the generating transduction algorithms, often generalising perfectly to inputs well beyond those encountered in training."
"String transduction is central to many applications in NLP, from name transliteration and spelling correction, to inflectional morphology and machine translation. The most common approach leverages symbolic finite state transducers, with approaches based on context free representations also being popular. RNNs offer an attractive alternative to symbolic transducers due to their simple algorithms and expressive representations. However, as we show in this work, such models are limited in their ability to generalise beyond their training data and have a memory capacity that scales with the number of their trainable parameters."
"In a parallel effort to ours, researchers are exploring the addition of memory to recurrent networks. The NTM and Memory Networks provide powerful random access memory operations, whereas we focus on a more efficient and restricted class of models which we believe are sufficient for natural language transduction tasks. More closely related to our work [Joulin Mikolov], have sought to develop a continuous stack controlled by an RNN. Note that this model - unlike the work proposed here - renders discrete push and pop operations continuous by “mixing” information across levels of the stack at each time step according to scalar push/pop action values. This means the model ends up compressing information in the stack, thereby limiting it as it effectively loses the unbounded memory nature of traditional symbolic models."
"Here we investigate memory modules that act like Stacks/Queues/Deques: - Memory ”size” grows/shrinks dynamically - Continuous push/pop not affected by number of objects stored - Can capture unboundedly long range dependencies - Propagates gradient flawlessly
"Bounded memory is useful in many ways, not least because it enforces some resource-sensitivity in the controller, which in turn encourages the learning of usefully compressed representations. On the other hand, unbounded memory means you don't need to worry about memory size, which is one less data-dependent hyperparameter to worry about, and is useful for tasks where you cannot estimate the length of computation (dynamic environment, RL, etc)."
posterhttp://egrefen.com/docs/NIPSStackPoster.pdfvideohttp://videolectures.net/deeplearning2015_blunsom_memory_reading/ (Blunsom)posthttps://iamtrask.github.io/2016/02/25/deepminds-neural-stack-machine/codehttps://jasdeep06.github.io/posts/Neural-Stacks/
"Learning to Execute" Zaremba, Sutskever
"Recurrent Neural Networks with Long Short-Term Memory units are widely used because they are expressive and are easy to train. Our interest lies in empirically evaluating the expressiveness and the learnability of LSTMs in the sequence-to-sequence regime by training them to evaluate short computer programs, a domain that has traditionally been seen as too complex for neural networks. We consider a simple class of programs that can be evaluated with a single left-to-right pass using constant memory. Our main result is that LSTMs can learn to map the character-level representations of such programs to their correct outputs. Notably, it was necessary to use curriculum learning, and while conventional curriculum learning proved ineffective, we developed a new variant of curriculum learning that improved our networks' performance in all experimental conditions. The improved curriculum had a dramatic impact on an addition problem, making it possible to train an LSTM to add two 9-digit numbers with 99% accuracy."
"Although current results are promising, they are very limited. We are able to deal with programs that can be evaluated by reading them once from left-to-right, but generic programs are far more complex. Our reasoning system has to be able to evaluate for an arbitrarily long time, if the task requires it. Moreover, it shouldn’t be limited by a fixed memory size. Instead, memory should be available as an interface."
noteshttp://www.shortscience.org/paper?bibtexKey=journals/corr/ZarembaS14codehttps://github.com/wojciechz/learning_to_executecodehttps://github.com/raindeer/seq2seq_experiments
"Neural Turing Machines" Graves, Wayne, Danihelka
"We extend the capabilities of neural networks by coupling them to external memory resources, which they can interact with by attentional processes. The combined system is analogous to a Turing Machine or Von Neumann architecture but is differentiable end-to-end, allowing it to be efficiently trained with gradient descent. Preliminary results demonstrate that Neural Turing Machines can infer simple algorithms such as copying, sorting and associative recall from input and output examples."
"The researchers hoped that the NTM would invent a binary heap sort, but in fact it seemed to have invented a hash table. The vectors were stored in memory locations controlled by the priority and then read out in priority order to give a sorted list."
"NTM can learn basic algorithms from examples only, including copy, loop, sort, associative recall and dynamic N-Gram inference. We are now looking at more complex tasks, including reinforcement learning, graph algorithms and question answering."
- turn neural networks into 'differentialbe computers' by giving them read-write acces to external memory
- separate computation and memory in neural networks to be able to learn algorithmic patterns
architecture:
- controller - neural network (recurrent or feedforward)
- heads - (attention) select portions of the memory to read/write to them
- memory - 'everything is differentiable'
attention:
- addressing by content (associative lookup)
- addressing by location (controller outputs a shift kernel)
RNN with big memory matrix and a "head" and "gaze" which it can position/focus to do a blurry, differentiable analog of a "read from (or write to) memory
difference with LSTM - decoupling memory and computation
NTM can learn basic algorithms from examples only, including copy, loop, sort, associative recall and dynamic N-Gram inference
Geoffrey Hinton:
"Its very impressive that they can get an RNN to invent a sorting algorithm. Its the first time I've believed that deep learning would be able to do real reasoning in the not too distant future. There will be a lot of future work in making the NTM (or its descendants) learn much more complicated algorithms and it will probably have many applications."
videohttp://research.microsoft.com/apps/video/default.aspx?id=260037 (Graves)videohttp://youtube.com/watch?v=otRoAQtc5Dk (Polykovskiy)posthttps://distill.pub/2016/augmented-rnns/noteshttp://rylanschaeffer.github.io/content/research/neural_turing_machine/main.htmlnoteshttp://blog.acolyer.org/2016/03/09/neural-turing-machines/codehttps://github.com/loudinthecloud/pytorch-ntmcodehttps://github.com/flomlo/ntm_keras/codehttps://github.com/carpedm20/NTM-tensorflow
"Artificial neural networks are remarkably adept at sensory processing, sequence learning and reinforcement learning, but are limited in their ability to represent variables and data structures and to store data over long timescales, owing to the lack of an external memory. Here we introduce a machine learning model called a Differentiable Neural Computer (DNC), which consists of a neural network that can read from and write to an external memory matrix, analogous to the random-access memory in a conventional computer. Like a conventional computer, it can use its memory to represent and manipulate complex data structures, but, like a neural network, it can learn to do so from data. When trained with supervised learning, we demonstrate that a DNC can successfully answer synthetic questions designed to emulate reasoning and inference problems in natural language. We show that it can learn tasks such as finding the shortest path between specified points and inferring the missing links in randomly generated graphs, and then generalize these tasks to specific graphs such as transport networks and family trees. When trained with reinforcement learning, a DNC can complete a moving blocks puzzle in which changing goals are specified by sequences of symbols. Taken together, our results demonstrate that DNCs have the capacity to solve complex, structured tasks that are inaccessible to neural networks without external read–write memory."
"Taken together, the bAbI and graph tasks demonstrate that DNCs are able to process and reason about graph-structured data regardless of whether the links are implicit or explicit. Moreover, we have seen that the structure of the data source is directly reflected in the memory access procedures learned by the controller. The Mini-SHRDLU problem shows that a systematic use of memory also emerges when a DNC learns by reinforcement to act in pursuit of a set of symbolic goals. The theme connecting these tasks is the need to learn to represent and reason about the complex, quasi-regular structure embedded in data sequences. In each problem, domain regularities, such as the conventions for representing graphs, are invariant across all sequences shown; on the other hand, for any given sequence, a DNC must detect and capture novel variability as episodic variables in memory. This mixture of large-scale structure and microscopic variability is generic to many problems that confront a cognitive agent. For example, in visual scenes, stories and action plans, broad regularities bind together novel variation in any exemplar. Rooms statistically have chairs in them, but the shape and location of a particular chair in a room are variables. These variable values can be written to the external memory of a DNC, leaving the controller network free to concentrate on learning global regularities. Our experiments focused on relatively small-scale synthetic tasks, which have the advantage of being easy to generate and interpret. For such problems, memory matrices of up to 512 locations were sufficient. To tackle real-world data we will need to scale up to thousands or millions of locations, at which point the memory will be able to store more information than can be contained in the weights of the controller. Such systems should be able to continually acquire knowledge through exposure to large, naturalistic data sources, even without adapting network parameters. We aim to further develop DNCs to serve as representational engines for one-shot learning, scene understanding, language processing and cognitive mapping, capable of intuiting the variable structure and scale of the world within a single, generic model."
"The Neural Turing Machine was the predecessor to the DNC described in this work. It used a similar architecture of neural network controller with read–write access to a memory matrix, but differed in the access mechanism used to interface with the memory. In the NTM, content-based addressing was combined with location-based addressing to allow the network to iterate through memory locations in order of their indices (for example, location n followed by n + 1 and so on). This allowed the network to store and retrieve temporal sequences in contiguous blocks of memory. However, there were several drawbacks. First, the NTM has no mechanism to ensure that blocks of allocated memory do not overlap and interfere — a basic problem of computer memory management. Interference is not an issue for the dynamic memory allocation used by DNCs, which provides single free locations at a time, irrespective of index, and therefore does not require contiguous blocks. Second, the NTM has no way of freeing locations that have already been written to and, hence, no way of reusing memory when processing long sequences. This problem is addressed in DNCs by the free gates used for de-allocation. Third, sequential information is preserved only as long as the NTM continues to iterate through consecutive locations; as soon as the write head jumps to a different part of the memory (using content-based addressing) the order of writes before and after the jump cannot be recovered by the read head. The temporal link matrix used by DNCs does not suffer from this problem because it tracks the order in which writes were made."
"
- temporal link between successive records keeps track of order that writes happened
- controller can choose whether or not to write anything to memory each timestep
- same controller can do transitive reasoning (a new read conditioned on read from previous timestep) during inference time
- three attention types: content, temporal, allocation"
(learns to find shortest path in graph)
posthttps://deepmind.com/blog/differentiable-neural-computers/videohttps://youtube.com/watch?v=steioHoiEms (Graves)videohttps://facebook.com/iclr.cc/videos/1713144705381255?t=549 (Graves)videohttps://youtu.be/9z3_tJAu7MQ?t=3m16s (Wayne)videohttps://youtube.com/watch?v=PQrlOjj8gAc (Wayne)videohttps://youtu.be/otRoAQtc5Dk?t=59m56s (Polykovskiy)videohttps://youtube.com/watch?v=r5XKzjTFCZQ (Raval)noteshttp://www.shortscience.org/paper?bibtexKey=10.1038/nature20101codehttps://github.com/deepmind/dnccodehttps://github.com/ixaxaar/pytorch-dnccodehttps://github.com/Mostafa-Samir/DNC-tensorflow
"One-shot Learning with Memory-Augmented Neural Networks" Santoro, Bartunov, Botvinick, Wierstra, Lillicrap
"Despite recent breakthroughs in the applications of deep neural networks, one setting that presents a persistent challenge is that of "one-shot learning." Traditional gradient-based networks require a lot of data to learn, often through extensive iterative training. When new data is encountered, the models must inefficiently relearn their parameters to adequately incorporate the new information without catastrophic interference. Architectures with augmented memory capacities, such as Neural Turing Machines, offer the ability to quickly encode and retrieve new information, and hence can potentially obviate the downsides of conventional models. Here, we demonstrate the ability of a memory-augmented neural network to rapidly assimilate new data, and leverage this data to make accurate predictions after only a few samples. We also introduce a new method for accessing an external memory that focuses on memory content, unlike previous methods that additionally use memory location-based focusing mechanisms."
"Many important learning problems demand an ability to draw valid inferences from small amounts of data, rapidly and knowledgeably adjusting to new information. Such problems pose a particular challenge for deep learning, which typically relies on slow, incremental parameter changes. We investigated an approach to this problem based on the idea of meta-learning. Here, gradual, incremental learning encodes background knowledge that spans tasks, while a more flexible memory resource binds information particular to newly encountered tasks. Our central contribution is to demonstrate the special utility of a particular class of MANNs for meta-learning. These are deep learning architectures containing a dedicated, addressable memory resource that is structurally independent from the mechanisms that implement process control. The MANN examined here was found to display performance superior to a LSTM in two meta-learning tasks, performing well in classification and regression tasks when only sparse training data was available."
"A critical aspect of the tasks studied is that they cannot be performed based solely on rote memory. New information must be flexibly stored and accessed, with correct performance demanding more than just accurate retrieval. Specifically, it requires that inferences be drawn from new data based on longer-term experience, a faculty sometimes referred as “inductive transfer.” MANNs are well-suited to meet these dual challenges, given their combination of flexible memory storage with the rich capacity of deep architectures for representation learning."
"Meta-learning is recognized as a core ingredient of human intelligence, and an essential test domain for evaluating models of human cognition. Given recent successes in modeling human skills with deep networks, it seems worthwhile to ask whether MANNs embody a promising hypothesis concerning the mechanisms underlying human meta-learning. In informal comparisons against human subjects, the MANN employed in this paper displayed superior performance, even at set-sizes that would not be expected to overtax human working memory capacity. However, when memory is not cleared between tasks, the MANN suffers from proactive interference, as seen in many studies of human memory and inference. These preliminary observations suggest that MANNs may provide a useful heuristic model for further investigation into the computational basis of human meta-learning. The work we presented leaves several clear openings for next-stage development. First, our experiments employed a new procedure for writing to memory that was prima facie well suited to the tasks studied. It would be interesting to consider whether meta-learning can itself discover optimal memory-addressing procedures. Second, although we tested MANNs in settings where task parameters changed across episodes, the tasks studied contained a high degree of shared high-level structure. Training on a wider range of tasks would seem likely to reintroduce standard challenges associated with continual learning, including the risk of catastrophic interference. Finally, it may be of interest to examine MANN performance in meta-learning tasks requiring active learning, where observations must be actively selected."
"
- Neural network weights learn to fit a function through many examples, but can't adapt quickly to new/small amounts of data.
- Memory modules can give networks a short-term memory to do this, and the metalearning setup they investigate is learning how to utilise this memory effectively. The memory structure exists, but the network needs to learn how to store and retrieve data for the task at hand.
- The task is to predict xt when only yt-1 is provided at the same time - it can't learn a single mapping and must use its memory to compare xt to previously seen inputs with provided labels. It never knows the correct class of the first instance presented of each class (but it can make an educated guess by not guessing previously seen classes that look different). So labels are given at test time as well.
- The shuffling means mixing up the labels e.g. giving a picture of 1 the class label 3, and the picture of 2 a class label of 5 etc. This way the network can't encode mappings in its weights, it has to learn how to learn (store examples in memory for comparison later). More explicitly, it has to store a sample and its label in the next time step if it intends to use it for comparison with new data.
"
videohttp://techtalks.tv/talks/meta-learning-with-memory-augmented-neural-networks/62523/ + https://vk.com/wall-44016343_8782 (Santoro)videohttps://youtube.com/watch?v=qos2CcviAuY (Bartunov)in russiannoteshttp://rylanschaeffer.github.io/content/research/one_shot_learning_with_memory_augmented_nn/main.htmlnoteshttp://www.shortscience.org/paper?bibtexKey=journals/corr/1605.06065codehttps://github.com/tristandeleu/ntm-one-shot
"Reinforcement Learning Neural Turing Machines" Zaremba, Sutskever
"The Neural Turing Machine is more expressive than all previously considered models because of its external memory. It can be viewed as a broader effort to use abstract external Interfaces and to learn a parametric model that interacts with them. The capabilities of a model can be extended by providing it with proper Interfaces that interact with the world. These external Interfaces include memory, a database, a search engine, or a piece of software such as a theorem verifier. Some of these Interfaces are provided by the developers of the model. However, many important existing Interfaces, such as databases and search engines, are discrete. We examine feasibility of learning models to interact with discrete Interfaces. We investigate the following discrete Interfaces: a memory Tape, an input Tape, and an output Tape. We use a Reinforcement Learning algorithm to train a neural network that interacts with such Interfaces to solve simple algorithmic tasks. Our Interfaces are expressive enough to make our model Turing complete."
"We have shown that the REINFORCE algorithm is capable of training an NTM-style model to solve very simple algorithmic problems. While the REINFORCE algorithm is very general and is easily applicable to a wide range of problems, it seems that learning memory access patterns with REINFORCE is difficult. We currently believe that a differentiable approach to memory addressing will likely yield better results in the near term. And while the Reinforce algorithm could still be useful for training NTM-style models, it would have to be used in a manner different from the one in this paper."
"There exist a vast number of Interfaces that could be used with our models. For example, the Google search engine is an example of such Interface. The search engine consumes queries (which are actions), and outputs search results. However, the search engine is not differentiable, and the model interacts with the Interface using discrete actions. This work examines the feasibility of learning to interact with discrete Interfaces using the reinforce algorithm. Discrete Interfaces cannot be trained directly with standard backpropagation because they are not differentiable. It is most natural to learn to interact with discrete Interfaces using Reinforcement Learning methods. In this work, we consider an Input Tape and a Memory Tape interface with discrete access. Our concrete proposal is to use the Reinforce algorithm to learn where to access the discrete interfaces, and to use the backpropagation algorithm to determine what to write to the memory and to the output."
"Discrete Interfaces are computationally attractive because the cost of accessing a discrete Interface is often independent of its size. It is not the case for the continuous Interfaces, where the cost of access scales linearly with size. It is a significant disadvantage since slow models cannot scale to large difficult problems that require intensive training on large datasets. In addition, an output Interface that lets the model decide when it wants to make a prediction allows the model’s runtime to be in principle unbounded. If the model has an output interface of this kind together with an interface to an unbounded memory, the model becomes Turing complete."
"At the core of the RL–NTM is an LSTM controller which receives multiple inputs and has to generate multiple outputs at each timestep. The objective function of the RL–NTM is the expected log probability of the desired outputs, where the expectation is taken over all possible sequences of actions, weighted with probability of taking these actions. Both backpropagation and REINFORCE maximize this objective. Backpropagation maximizes the log probabilities of the model’s predictions, while the REINFORCE algorithm influences the probabilities of action sequences."
"At each timestep, the RL-NTM consumes the value of the current input tape, the value of the current memory cell, and a representation of all the actions that have been taken in the previous timestep (not marked on the figures). The RL-NTM then outputs a new value for the current memory cell (marked with a star), a prediction for the next target symbol, and discrete decisions for changing the positions of the heads on the various tapes. The RL-NTM learns to make discrete decisions using the REINFORCE algorithm, and learns to produce continuous outputs using backpropagation."
"The expressive power of a machine learning model is closely related to the number of sequential computational steps it can learn. For example, Deep Neural Networks have been more successful than shallow networks because they can perform a greater number of sequential computational steps (each highly parallel). The Neural Turing Machine is a model that can compactly express an even greater number of sequential computational steps, so it is even more powerful than a DNN. Its memory addressing operations are designed to be differentiable; thus the NTM can be trained with backpropagation. While differentiable memory is relatively easy to implement and train, it necessitates accessing the entire memory content at each computational step. This makes it difficult to implement a fast NTM. In this work, we use the Reinforce algorithm to learn where to access the memory, while using backpropagation to learn what to write to the memory. We call this model the RL-NTM. Reinforce allows our model to access a constant number of memory cells at each computational step, so its implementation can be faster. The RL-NTM is the first model that can, in principle, learn programs of unbounded running time. We successfully trained the RL-NTM to solve a number of algorithmic tasks that are simpler than the ones solvable by the fully differentiable NTM. As the RL-NTM is a fairly intricate model, we needed a method for verifying the correctness of our implementation. To do so, we developed a simple technique for numerically checking arbitrary implementations of models that use Reinforce, which may be of independent interest."
videohttps://youtu.be/ezE-13X0UoM?t=39m4s (Zaremba)codehttps://github.com/ilyasu123/rlntm
"Learning Simple Algorithms from Examples" Zaremba, Mikolov, Joulin, Fergus
"We present an approach for learning simple algorithms such as copying, multi-digit addition and single digit multiplication directly from examples. Our framework consists of a set of interfaces, accessed by a controller. Typical interfaces are 1-D tapes or 2-D grids that hold the input and output data. For the controller, we explore a range of neural network-based models which vary in their ability to abstract the underlying algorithm from training instances and generalize to test examples with many thousands of digits. The controller is trained using Q-learning with several enhancements and we show that the bottleneck is in the capabilities of the controller rather than in the search incurred by Q-learning."
"We have explored the ability of neural network models to learn algorithms for simple arithmetic operations. Through experiments with supervision and reinforcement learning, we have shown that they are able to do this successfully, albeit with caveats. Q-learning was shown to work as well as the supervised case. But, disappointingly, we were not able to find a single controller that could solve all tasks. We found that for some tasks, generalization ability was sensitive to the memory capacity of the controller: too little and it would be unable to solve more complex tasks that rely on carrying state across time; too much and the resulting model would overfit the length of the training sequences. Finding automatic methods to control model capacity would seem to be important in developing robust models for this type of learning problem."
(learns to add multi-digit numbers and to multiply single-digit numbers)
videohttp://youtube.com/watch?v=GVe6kfJnRAw (demo)videohttp://youtube.com/watch?v=ezE-13X0UoM (Zaremba)videohttp://techtalks.tv/talks/learning-simple-algorithms-from-examples/62524/ (Zaremba)codehttps://github.com/wojzaremba/algorithm-learning
"Improving Policy Gradient by Exploring Under-appreciated Rewards" Nachum, Norouzi, Schuurmans
"This paper presents a novel form of policy gradient for model-free reinforcement learning with improved exploration properties. Current policy-based methods use entropy regularization to encourage undirected exploration of the reward landscape, which is ineffective in high dimensional spaces with sparse rewards. We propose a more directed exploration strategy that promotes exploration of under-appreciated reward regions. An action sequence is considered under-appreciated if its log-probability under the current policy under-estimates its resulting reward. The proposed exploration strategy is easy to implement, requiring small modifications to an implementation of the REINFORCE algorithm. We evaluate the approach on a set of algorithmic tasks that have long challenged RL methods. Our approach reduces hyper-parameter sensitivity and demonstrates significant improvements over baseline methods. Our algorithm successfully solves a benchmark multi-digit addition task and generalizes to long sequences. This is, to our knowledge, the first time that a pure RL method has solved addition using only reward feedback."
"Prominent approaches to improving exploration beyond epsilon-greedy in value-based or model-based RL have focused on reducing uncertainty by prioritizing exploration toward states and actions where the agent knows the least. This basic intuition underlies work on counter and recency methods, exploration methods based on uncertainty estimates of values, methods that prioritize learning environment dynamics, and methods that provide an intrinsic motivation or curiosity bonus for exploring unknown states. We relate the concepts of value and policy in RL and propose an exploration strategy based on the discrepancy between the two."
"To confirm whether our method is able to find the correct algorithm for multi-digit addition, we investigate its generalization to longer input sequences than provided during training. We evaluate the trained models on inputs up to a length of 2000 digits, even though training sequences were at most 33 characters. For each length, we test the model on 100 randomly generated inputs, stopping when the accuracy falls below 100%. Out of the 60 models trained on addition with UREX, we find that 5 models generalize to numbers up to 2000 digits without any observed mistakes."
(learns to add multi-digit numbers)
"Grid Long Short-Term Memory" Kalchbrenner, Danihelka, Graves
"This paper introduces Grid Long Short-Term Memory, a network of LSTM cells arranged in a multidimensional grid that can be applied to vectors, sequences or higher dimensional data such as images. The network differs from existing deep LSTM architectures in that the cells are connected between network layers as well as along the spatiotemporal dimensions of the data. The network provides a unified way of using LSTM for both deep and sequential computation. We apply the model to algorithmic tasks such as 15-digit integer addition and sequence memorization, where it is able to significantly outperform the standard LSTM. We then give results for two empirical tasks. We find that 2D Grid LSTM achieves 1.47 bits per character on the Wikipedia character prediction benchmark, which is state-of-the-art among neural approaches. In addition, we use the Grid LSTM to define a novel two-dimensional translation model, the Reencoder, and show that it outperforms a phrase-based reference system on a Chinese-to-English translation task."
allows to use LSTM cells for both deep and sequential computation
"Highway Networks have a gated connection in depth dimension analogous to gated connection LSTMs have in time dimension. Grid LSTMs have these gated connections in both dimensions."
(learns to calculate parity of bit array)
"Neural GPUs Learn Algorithms" Kaiser, Sutskever
"Learning an algorithm from examples is a fundamental problem that has been widely studied. Recently it has been addressed using neural networks, in particular by Neural Turing Machines. These are fully differentiable computers that use backpropagation to learn their own programming. Despite their appeal NTMs have a weakness that is caused by their sequential nature: they cannot be parallelized and are hard to train due to their large depth when unfolded. We present a neural network architecture to address this problem: the Neural GPU. It is based on a type of convolutional gated recurrent unit and, like the NTM, is computationally universal. Unlike the NTM, the Neural GPU is highly parallel which makes it easier to train and efficient to run. An essential property of algorithms is their ability to handle inputs of arbitrary size. We show that the Neural GPU can be trained on short instances of an algorithmic task and successfully generalize to long instances. We verified it on a number of tasks including long addition and long multiplication of numbers represented in binary. We train the Neural GPU on numbers with up to 20 bits and observe no errors whatsoever while testing it, even on much longer numbers. To achieve these results we introduce a technique for training deep recurrent networks: parameter sharing relaxation. We also found a small amount of dropout and gradient noise to have a large positive effect on learning and generalization."
"The results show clearly that there is a qualitative difference between what can be achieved with a Neural GPU and what was possible with previous archietctures. In particular, for the first time, we show a neural network that learns a non-trivial superlinear-time algorithm in a way that generalized to much higher lengths without errors. This opens the way to use neural networks in domains that were previously only addressed by discrete methods, such as program synthesis. With the surprising data efficiency of Neural GPUs it could even be possible to replicate previous program synthesis results but in a more scalable way. It is also interesting that a Neural GPU can learn symbolic algorithms without using any discrete state at all, and adding dropout and noise only improves its performance. Another promising future work is to apply Neural GPUs to language processing tasks. Good results have already been obtained on translation with a convolutional architecture over words and adding gating and recursion, like in a Neural GPU, should allow to train much deeper models without overfitting. Finally, the parameter sharing relaxation technique we introduced can be applied to any deep recurrent network and has the potential to improve RNN training in general."
"It turns out that despite its recent success the sequence-to-sequence model has limitations. In its basic architecture, the entire input is encoded into a single fixed-size vector, so the model cannot generalize to inputs much longer than this fixed capacity. One way to resolve this problem is by using an attention mechanism. This allows the network to inspect arbitrary parts of the input in every decoding step, so the basic limitation is removed. But other problems remain, and Joulin & Mikolov (2015) show a number of basic algorithmic tasks on which sequence-to-sequence LSTM networks fail to generalize."
"While the above definition is simple, it might not be immediately obvious what kind of functions a Neural GPU can compute. Why can we expect it to be able to perform long multiplication? To answer such questions it is useful to draw an analogy between a Neural GPU and a discrete 2-dimensional cellular automaton. Except for being discrete and the lack of a gating mechanism, such automata are quite similar to Neural GPUs. Of course, these are large exceptions. Dense representations have often more capacity than purely discrete states and the gating mechanism is crucial to avoid vanishing gradients during training. But the computational power of cellular automata is much better understood. In particular, it is well known that a cellular automaton can exploit its parallelism to multiply two n-bit numbers in O(n) steps using Atrubin’s algorithm."
"Neural Turing Machines are magnificient but they are sequential (= non parallelizeable) and deep (= hard to train)."
"Why are NTM so deep? At each step ("clock tick") the NTM can modify only one element in its memory. It takes many clock ticks to create a large structure in memory. Requires massive back propagation."
(learns to add and multiply long binary numbers without errors)
videohttps://youtube.com/watch?v=LzC8NkTZAF4 (demo)videohttps://youtube.com/watch?v=hVv4M0bTBJc (Sutskever)codehttps://github.com/tensorflow/models/tree/master/research/neural_gpucodehttps://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/neural_gpu.py
"Extensions and Limitations of the Neural GPU" Price, Zaremba, Sutskever
"The Neural GPU is a recent model that can learn algorithms such as multi-digit binary addition and binary multiplication in a way that generalizes to inputs of arbitrary length. We show that there are two simple ways of improving the performance of the Neural GPU: by carefully designing a curriculum, and by increasing model size. The latter requires careful memory management, as a naive implementation of the Neural GPU is memory intensive. We find that these techniques to increase the set of algorithmic problems that can be solved by the Neural GPU: we have been able to learn to perform all the arithmetic operations (and generalize to arbitrarily long numbers) when the arguments are given in the decimal representation (which, surprisingly, has not been possible before). We have also been able to train the Neural GPU to evaluate long arithmetic expressions with multiple operands that require respecting the precedence order of the operands, although these have succeeded only in their binary representation, and not with 100% accuracy. In addition, we attempt to gain insight into the Neural GPU by understanding its failure modes. We find that Neural GPUs that correctly generalize to arbitrarily long numbers still fail to compute the correct answer on highly-symmetric, atypical inputs: for example, a Neural GPU that achieves near-perfect generalization on decimal multiplication of up to 100-digit long numbers can fail on 000000 . . . 002 × 000000 . . . 002 while succeeding at 2 × 2. These failure modes are reminiscent of adversarial examples."
"In this paper, we attempt to better understand this generalization in the context of the Neural GPU. We empirically study the parameters that affect its probability of successfully generalizing to inputs much greater length, and also study its failures. We report three notable findings: first, that larger models can learn harder tasks; second, that very detailed curriculum can enable the training of otherwise un-trainable neural networks; and third, those models that achieve perfect performance on test cases from the uniform distribution over much longer inputs may still fail on highly structured inputs. This suggests that these models fail to learn the “true algorithm” as well as we’ve hoped, and that additional research is required for to learn models that can generalize much better. Such structured examples are reminiscent of adversarial examples for images."
"The phenomenon of generalization to inputs that are outside the training distribution is poorly understood. The space of problems for which such generalization is possible has not been identified, and a detailed explanation of the reasons why such generalization should succeed is missing as well. Given that the test inputs do not come from the training data distribution, we do not have a formal reason to believe that such out-of-distribution generalization should actually succeed."
"The Neural GPU is notable since it is the only model that has, thus far, been able to learn to correctly multiply integers of length much greater than it has been trained on."
"For a neural model to be able to learn an algorithm, it is essential that it is capable of running the necessary number of computational steps. Most of the above models have only been successfully used to learn algorithms that require a linear number of computational steps in the size of the input. While some models can in principle learn the correct runtime for a given algorithm, in practice it has not been possible to learn algorithms requiring superlinear runtime, such as integer multiplication. The only known neural model that can solve tasks whose runtime is truly superlinear in the size of the input is the Neural GPU."
"The Neural GPU is a cellular automaton, which is a Turing complete computational model. However, the automaton is often computationally inefficient compared to von Neumann architecture. It is difficult for a cellular automaton to move data globally as the entirety of its computation operates locally at each step."
"Can Active Memory Replace Attention" Kaiser, Bengio
"Several mechanisms to focus attention of a neural network on selected parts of its input or memory have been used successfully in deep learning models in recent years. Attention has improved image classification, image captioning, speech recognition, generative models, and learning algorithmic tasks, but it had probably the largest impact on neural machine translation. Recently, similar improvements have been obtained using alternative mechanisms that do not focus on a single part of a memory but operate on all of it in parallel, in a uniform way. Such mechanism, which we call active memory, improved over attention in algorithmic tasks, image processing, and in generative modelling. So far, however, active memory has not improved over attention for most natural language processing tasks, in particular for machine translation. We analyze this shortcoming in this paper and propose an extended model of active memory that matches existing attention models on neural machine translation and generalizes better to longer sentences. We investigate this model and explain why previous active memory models did not succeed. Finally, we discuss when active memory brings most benefits and where attention can be a better choice."
"To better understand the main shortcoming of previous active memory models, let us look at the average log-perplexities of different attention models. A pure Neural GPU model yields 3.5, a Markovian one yields 2.5, and only a model with full dependence, trained with teacher forcing, achieves 1.3. The recurrent dependence in generating the output distribution turns out to be the key to achieving good performance. We find it illuminating that the issue of dependencies in the output distribution can be disentangled from the particularities of the model or model class. In earlier works, such dependence (and training with teacher forcing) was always used in LSTM and GRU models, but very rarely in other kinds models. We show that it can be beneficial to consider this issue separately from the model architecture. It allows us to create the Extended Neural GPU and this way of thinking might also prove fruitful for other classes of models. When the issue of recurrent output dependencies is addressed, as we do in the Extended Neural GPU, an active memory model can indeed match or exceed attention models on a large-scale real-world task. Does this mean we can always replace attention by active memory? The answer could be yes for the case of soft attention. Its cost is approximately the same as active memory, it performs much worse on some tasks like learning algorithms, and – with the introduction of the Extended Neural GPU – we do not know of a task where it performs clearly better. Still, an attention mask is a very natural concept, and it is probable that some tasks can benefit from a selector that focuses on single items by definition. This is especially obvious for hard attention: it can be used over large memories with potentially much less computational cost than an active memory, so it might be indispensable for devising long-term memory mechanisms. Luckily, active memory and attention are not exclusive, and we look forward to investigating models that combine these mechanisms."
"Neural Programmer: Inducing Latent Programs with Gradient Descent" Neelakantan, Le, Sutskever
"Deep neural networks have achieved impressive supervised classification performance in many tasks including image recognition, speech recognition, and sequence to sequence learning. However, this success has not been translated to applications like question answering that may involve complex arithmetic and logic reasoning. A major limitation of these models is in their inability to learn even simple arithmetic and logic operations. For example, it has been shown that neural networks fail to learn to add two binary numbers reliably. In this work, we propose Neural Programmer, an end-to-end differentiable neural network augmented with a small set of basic arithmetic and logic operations. Neural Programmer can call these augmented operations over several steps, thereby inducing compositional programs that are more complex than the built-in operations. The model learns from a weak supervision signal which is the result of execution of the correct program, hence it does not require expensive annotation of the correct program itself. The decisions of what operations to call, and what data segments to apply to are inferred by Neural Programmer. Such decisions, during training, are done in a differentiable fashion so that the entire network can be trained jointly by gradient descent. We find that training the model is difficult, but it can be greatly improved by adding random noise to the gradient. On a fairly complex synthetic table-comprehension dataset, traditional recurrent networks and attentional models perform poorly while Neural Programmer typically obtains nearly perfect accuracy."
"We develop Neural Programmer, a neural network model augmented with a small set of arithmetic and logic operations to perform complex arithmetic and logic reasoning. The model is fully differentiable and it can be trained in an end-to-end fashion to induce programs using much lesser sophisticated human supervision than prior work. It is a general model for program induction broadly applicable across different domains, data sources and languages. Our experiments indicate that the model is capable of learning with delayed supervision and exhibits powerful compositionality."
"While DNN models are capable of learning the fuzzy underlying patterns in the data, they have not had an impact in applications that involve crisp reasoning. A major limitation of these models is in their inability to learn even simple arithmetic and logic operations. For example, Joulin & Mikolov (2015) show that recurrent neural networks fail at the task of adding two binary numbers even when the result has less than 10 bits. This makes existing DNN models unsuitable for downstream applications that require complex reasoning, e.g., natural language question answering. For example, to answer the question “how many states border Texas?”, the algorithm has to perform an act of counting in a table which is something that a neural network is not yet good at. A fairly common method for solving these problems is program induction where the goal is to find a program (in SQL or some high-level languages) that can correctly solve the task. An application of these models is in semantic parsing where the task is to build a natural language interface to a structured database. This problem is often formulated as mapping a natural language question to an executable query. A drawback of existing methods in semantic parsing is that they are difficult to train and require a great deal of human supervision. As the space over programs is non-smooth, it is difficult to apply simple gradient descent; most often, gradient descent is augmented with a complex search procedure, such as sampling. To further simplify training, the algorithmic designers have to manually add more supervision signals to the models in the form of annotation of the complete program for every question or a domain-specific grammar. For example, designing grammars that contain rules to associate lexical items to the correct operations, e.g., the word “largest” to the operation “argmax”, or to produce syntactically valid programs, e.g., disallow the program >= dog. The role of hand-crafted grammars is crucial in semantic parsing yet also limits its general applicability to many different domains."
"The goal of this work is to develop a model that does not require substantial human supervision and is broadly applicable across different domains, data sources and natural languages. We propose Neural Programmer, an end-to-end differentiable neural network augmented with a small set of basic arithmetic and logic operations. In our formulation, the neural network can run several steps using a recurrent neural network. At each step, it can select a segment in the data source and a particular operation to apply to that segment. The neural network propagates these outputs forward at every step to form the final, more complicated output. Using the target output, we can adjust the network to select the right data segments and operations, thereby inducing the correct program. Key to our approach is that the selection process (for the data source and operations) is done in a differentiable fashion (i.e., soft selection or attention), so that the whole neural network can be trained jointly by gradient descent. At test time, we replace soft selection with hard selection. By combining neural network with mathematical operations, we can utilize both the fuzzy pattern matching capabilities of deep networks and the crisp algorithmic power of traditional programmable computers."
"Neural Programmer has two attractive properties. First, it learns from a weak supervision signal which is the result of execution of the correct program. It does not require the expensive annotation of the correct program for the training examples. The human supervision effort is in the form of question, data source and answer triples. Second, Neural Programmer does not require additional rules to guide the program search, making it a general framework. With Neural Programmer, the algorithmic designer only defines a list of basic operations which requires lesser human effort than in previous program induction techniques."
"We experiment with a synthetic table-comprehension dataset, consisting of questions with a wide range of difficulty levels. Examples of natural language translated queries include “print elements in column H whose field in column C is greater than 50 and field in column E is less than 20?” or “what is the difference between sum of elements in column A and number of rows in the table?”. We find that LSTM recurrent networks and LSTM models with attention do not work well. Neural Programmer, however, can completely solve this task or achieve greater than 99% accuracy on most cases by inducing the required latent program."
"Current neural networks cannot handle complex data structures."
"Current neural networks cannot handle numbers well: treat numbers as tokens, which lead to many unknown words."
"Current neural networks cannot make use of rules well: cannot use addition, subtraction, summation, average operations."
"Authors propose a neural programmer by defining a set of symbolic operations (e.g., argmax, greater than); at each step, all possible execution results are fused by a softmax layer, which predicts the probability of each operator at the current step. The step-by-step fusion is accomplished by weighted sum and the model is trained with mean square error. Hence, such approaches work with numeric tables, but may not be suited for other operations like string matching; it also suffers from the problem of “exponential numbers of combinatorial states.”"
videohttp://youtu.be/lc68_d_DnYs?t=24m44s (Neelakantan)videohttp://youtu.be/KmOdBS4BXZ0?t=1h8m44s (Le)posthttp://distill.pub/2016/augmented-rnns/codehttps://github.com/tensorflow/models/tree/master/research/neural_programmerpaper"Learning a Natural Language Interface with Neural Programmer" by Neelakantan et al.
"Neural Programmer-Interpreters" Reed, de Freitas
"We propose the neural programmer-interpreter (NPI): a recurrent and compositional neural network that learns to represent and execute programs. NPI has three learnable components: a task-agnostic recurrent core, a persistent key-value program memory, and domain-specific encoders that enable a single NPI to operate in multiple perceptually diverse environments with distinct affordances. By learning to compose lower-level programs to express higher-level programs, NPI reduces sample complexity and increases generalization ability compared to sequence-to-sequence LSTMs. The program memory allows efficient learning of additional tasks by building on existing programs. NPI can also harness the environment (e.g. a scratch pad with read-write pointers) to cache intermediate results of computation, lessening the long-term memory burden on recurrent hidden units. In this work we train the NPI with fully-supervised execution traces; each program has example sequences of calls to the immediate subprograms conditioned on the input. Rather than training on a huge number of relatively weak labels, NPI learns from a small number of rich examples. We demonstrate the capability of our model to learn several types of compositional programs: addition, sorting, and canonicalizing 3D models. Furthermore, a single NPI learns to execute these programs and all 21 associated subprograms."
"We have shown that the NPI can learn programs in very dissimilar environments with different affordances. In the context of sorting we showed that NPI exhibits very strong generalization in comparison to sequence-to-sequence LSTMs. We also showed how a trained NPI with a fixed core can continue to learn new programs without forgetting already learned programs."
"While unsupervised and reinforcement learning play important roles in perception and motor control, other cognitive abilities are possible thanks to rich supervision and curriculum learning. This is indeed the reason for sending our children to school."
"An advantage of our approach to model building and training is that the learned programs exhibit strong generalization. Specifically, when trained to sort sequences of up to twenty numbers in length, they can sort much longer sequences at test time. In contrast, the experiments will show that more standard sequence to sequence LSTMs only exhibit weak generalization."
"Schmidhuber proposed a related meta-learning idea, whereby one learns the parameters of a slowly changing network, which in turn generates context dependent weight changes for a second rapidly changing network."
"In cognitive science, several theories of brain areas controlling other brain parts so as to carry out multiple tasks have been proposed."
"Instead of using input and output pairs, our model is trained on program execution traces at varying levels of abstraction. In exchange for this richer supervision, we get the benefit of learninng compositionality of programs, and also data efficient training of complex programs."
"In practice we found it effective to employ a curriculum learning strategy. The intuition is that we first learn the most basic subprograms such as shifting pointers left or right, followed by more challenging programs such as comparing and conditionally swapping two numbers. The knowledge of subprogram difficulty is itself a form of supervision, but there could be many reasonable heuristics such as counting the average number of low-level actions generated by the program."
"We also note that our program has a distinct memory advantage over basic LSTMs because all subprograms can be trained in parallel. For programs whose execution length grows e.g. quadratically with the input sequence length, an LSTM will be highly constrained by device memory to train on short sequences. By exploiting compositionality, an effective curriculum can often be developed with sublinear-length subprograms, enabling our NPI model to train on order of magnitude larger sequences than the LSTM."
"Neural Programmer-Interpreters is an attempt to learn libraries of programs (and by programs I mean motor behaviours, perceptual routines, logical relationships, algorithms, policies, etc.)."
"Neural Programmer-Interpreters can also be seen as a way to compile any program into a neural network by learning a model that mimic the program. While more flexible than the previous approaches, the NPI is unable to improve on a learned program due to its dependency on a non-differentiable environment."
"
- Low sample complexity and strong generalization through program re-use
- NPI has a learnable key-value program-memory and can do continual learning
- NPI uses same recurrent core parameters to solve many very different tasks
- NPI can harness the environment to cache intermediate computations
- Learning to learn: A trained NPI can continue learning new programs
- Traing with low-quantity but rich lessons and curriculum learning, instead of many data samples - think of going to school"
"
- Long-term prediction: Model potentially long sequences of actions by exploiting compositional structure.
- Continual learning: Learn new programs by composing previously-learned programs, rather than from scratch.
- Data efficiency: Learn generalizable programs from a small number of example traces.
- Interpretability: By looking at NPI's generated commands, we can understand what it is doing at multiple levels of temporal abstraction."
de Freitas:
"For me there are two types of generalisation, which I will refer to as Symbolic and Connectionist generalisation. If we teach a machine to sort sequences of numbers of up to length 10 or 100, we should expect them to sort sequences of length 1000 say. Obviously symbolic approaches have no problem with this form of generalisation, but neural nets do poorly. On the other hand, neural nets are very good at generalising from data (such as images), but symbolic approaches do poorly here. One of the holy grails is to build machines that are capable of both symbolic and connectionist generalisation. NPI is a very early step toward this. NPI can do symbolic operations such as sorting and addition, but it can also plan by taking images as input and it's able to generalise the plans to different images (e.g. in the NPI car example, the cars are test set cars not seen before)."
"Consider a new task for which you need to train a model. Suppose we have 2 data examples consisting of two 3-digit input sequences and a 3-digit output sequence, as follows: Train_Input_1={425,341}, Train_Output_1={379} Train_Input_2={312,342}, Train_Output_2={357}. Question: If the test input is: Test_Input={242,531}, What is Test_Ouput? Stop reading and see if you can answer this. Ready to move on?! OK so now let me tell you that you need to use two programs: Sort and Add to map the input sequences to the output. Can you now get the answer? Yes, much easier ;) Knowing which programs to use, at this very high cognitive level, is very helpful, and perhaps even essential. Note that NPI would have no problem solving this task as it has already learned to sort and add sequences of numbers. Thus with the core fixed, it can easily learn this new program if we tell it to re-use the sort and add programs. At this point, we don't need to provide it with entire execution traces anymore. In contrast, a sequence to sequence model or any other similar model would not be able to learn this mapping with only two examples as above. I hope this is helpful. We see NPI as a way of providing machines not with examples, but with lessons on how to solve problems."
"It is true that it's hard to train these architectures. Curriculum learning is essential. But here is the thing, when people talk about curriculum learning they often mean "learning with a curriculum" as opposed to "learning a curriculum". The latter is an extremely important problem. In the NPI paper, Scott took steps toward adapting the curriculum. I think you are absolutely right when it comes to the combinatorial challenges. However, humans also appear to be poor at this in some cases. For example, when I show folks the following training data consisting of two input sequences and an output sequence (2 data samples): Input_1: {(3,2,4),(5,2,1)} Output_1: {(3,5,9)} Input_2: {(4,1,3),(3,2,2)} Output_2:{(3,5,7)} they are not able to generalize, when I give then a third example: Input_3={(3,1,4),(2,2,2)}. However, if I tell them to use the programs SORT and ADD, they can quickly figure out the pattern. So for some problems, lots of data might be needed to deal with combinatorial issues. On the other hand, if the problem is of the form: input_1: alice Output_1: ALICE input_2: bob Output_2: ? most would know what Output_2 should be."
"I strongly agree with building the foundations of representations and skills that could give rise to communication, language and writing. Much of my work is indeed in this area. This in fact was one of the driving forces behind NPI. One part of language is procedural understanding. If I say "sort the the following numbers: 2,4,3,6 in descending order", how do you understand the meaning of the sentence? There's a few ways. One natural way requires that you know what sort means. If you can't sort in any way, I don't think you can understand the sentence properly. As Feynman said: "What I cannot create, I do not understand". Moreover, another strong part of what is explored in NPI is the ability of harnessing the environment to do computation - this I believe is very tied to writing. I believe in externalism: My mind is not something inside my head. My mind is made of many memory devices that I know how to access and write to - it is like a search engine in the real world. My mind is also made of other people, who are now extending its ability to think."
- http://www-personal.umich.edu/~reedscot/iclr_project.html
videohttp://youtube.com/watch?v=B70tT4WMyJk (overview)videohttp://youtube.com/watch?v=s7PuBqwI2YA (demo)videohttp://youtu.be/SAcHyzMdbXc?t=5m14s (de Freitas)videohttp://youtu.be/x1kf4Zojtb0?t=52m22s (de Freitas)videohttp://videolectures.net/iclr2016_reed_neural_programmer/ (Reed)videohttps://youtu.be/LsLPp7gqwA4?t=21m19s (Minervini)posthttps://pseudoprofound.wordpress.com/2016/06/07/neural-programmer-interpreters-programs-that-can-learn-programs/posthttp://near.ai/articles/2017-05-31-NPI/posthttps://reddit.com/r/MachineLearning/comments/3y4zai/ama_nando_de_freitas/cyc53gtposthttps://reddit.com/r/MachineLearning/comments/3y4zai/ama_nando_de_freitas/cydu4azcodehttps://github.com/mokemokechicken/keras_npi
"Gradient-based Hyperparameter Optimization through Reversible Learning" Maclaurin, Duvenaud, Adams
"Tuning hyperparameters of learning algorithms is hard because gradients are usually unavailable. We compute exact gradients of cross-validation performance with respect to all hyperparameters by chaining derivatives backwards through the entire training procedure. These gradients allow us to optimize thousands of hyperparameters, including step-size and momentum schedules, weight initialization distributions, richly parameterized regularization schemes, and neural network architectures. We compute hyperparameter gradients by exactly reversing the dynamics of stochastic gradient descent with momentum."
"In this paper, we derived a computationally efficient procedure for computing gradients through stochastic gradient descent with momentum. We showed how the approximate reversibility of learning dynamics can be used to drastically reduce the memory requirement for exactly backpropagating gradients through hundreds of training iterations. We showed how these gradients allow the optimization of validation loss with respect to thousands of hyperparameters, something which was previously infeasible. This new ability allows the automatic tuning of most details of training neural networks. We demonstrated the tuning of detailed training schedules, regularization schedules, and neural network architectures."
"In this paper, they consider the off-line training scenario, and propose to do gradient descent on the learning rate by unrolling the complete training procedure and treating it all as a function to optimize, with respect to the learning rate. This way, they can optimize directly the validation set loss. The paper in fact goes much further and can tune many other hyper-parameters of the gradient descent procedure: momentum, weight initialization distribution parameters, regularization and input preprocessing."
"Authors show how to backpropagate gradients for optimizing hyperparameters. It essentially reduces to performing automatic differentiation well, and the experiments they try this on are really cool, e.g., optimizing the learning rate schedule per layer of a NN, optimizing training data, and optimizing the initialization of SGD."
"There's a very fuzzy line between "learning architecture" and "tuning weights". An obvious connection is that, if you begin with a large hidden layer, then eliminating nodes -- which you'd usually think of as an "architecture" choice -- is equivalent to just setting the weights of those nodes to zero, which gradient descent could do if you use a sparsity-inducing prior. In a broad sense, weights in neural networks are really just a continuous parameterization of choices that a circuit designer would think of as architectural, e.g., how many nodes to use, which nodes should be connected to which other nodes, and what the nature of the connections should be. In principle you can do gradient descent on any architectural parameter that has a continuous relationship to the network output. The paper basically figures out all the tricks you need to apply automatic differentiation to the backprop algorithm itself, which allows them to do gradient-based optimization of hyperparameters with respect to validation set loss."
videohttp://youtube.com/watch?v=VG2uCpKJkSg (Adams)videohttp://videolectures.net/icml2015_duvenaud_reversible_learning/ (Duvenaud)noteshttp://www.shortscience.org/paper?bibtexKey=conf/icml/MaclaurinDA15codehttps://github.com/HIPS/hypergrad
"Learning to Learn by Gradient Descent by Gradient Descent" Andrychowicz, Denil, Gomez, Hoffman, Pfau, Schaul, de Freitas
"The move from hand-designed features to learned features in machine learning has been wildly successful. In spite of this, optimization algorithms are still designed by hand. In this paper we show how the design of an optimization algorithm can be cast as a learning problem, allowing the algorithm to learn to exploit structure in the problems of interest in an automatic way. Our learned algorithms, implemented by LSTMs, outperform generic, hand-designed competitors on the tasks for which they are trained, and also generalize well to new tasks with similar structure. We demonstrate this on a number of tasks, including simple convex problems, training neural networks, and styling images with neural art."
"We have shown how to cast the design of optimization algorithms as a learning problem, which enables us to train optimizers that are specialized to particular classes of functions. Our experiments have confirmed that learned neural optimizers compare favorably against state-of-the-art optimization methods used in deep learning. We witnessed a remarkable degree of transfer, with for example the LSTM optimizer trained on 12,288 parameter neural art tasks being able to generalize to tasks with 49,152 parameters, different styles, and different content images all at the same time. We observed similar impressive results when transferring to different architectures in the MNIST task. The results on the CIFAR image labeling task show that the LSTM optimizers outperform handengineered optimizers when transferring to datasets drawn from the same data distribution. In future work we plan to continue investigating the design of the NTM-BFGS optimizers. We observed that these outperformed the LSTM optimizers for quadratic functions, but we saw no benefit of using these methods in the other stochastic optimization tasks. Another important direction for future work is to develop optimizers that scale better in terms of memory usage."
videohttps://youtu.be/SAcHyzMdbXc?t=10m24s (de Freitas)videohttps://youtu.be/x1kf4Zojtb0?t=1h4m53s (de Freitas)videohttp://videolectures.net/deeplearning2017_de_freitas_learning_to_learn/#t=1669 (de Freitas)noteshttp://www.shortscience.org/paper?bibtexKey=journals/corr/1606.04474noteshttps://theneuralperspective.com/2017/01/04/learning-to-learn-by-gradient-descent-by-gradient-descent/noteshttps://blog.acolyer.org/2017/01/04/learning-to-learn-by-gradient-descent-by-gradient-descent/posthttps://hackernoon.com/learning-to-learn-by-gradient-descent-by-gradient-descent-4da2273d64f2codehttps://github.com/deepmind/learning-to-learncodehttps://github.com/ikostrikov/pytorch-meta-optimizer
"problems:
- cortical neurons do not communicate real-valued activities - they send spikes
- how do neurons know dy/dx (the gradient of their non-linear function) if this function wanders?
- the neurons need to send two different types of signal: forward pass (signal = activity = y) and backward pass (signal = dE/dx)
- neurons do not have point-wise reciprocal connections with the same weight in both directions"
"solutions:
- the fact that neurons send spikes rather than real numbers is not a problem: spikes are a great regularizer (similar to dropout)
- error derivatives can be represented as temporal derivatives: this allows a neuron to represent both its activity and its error derivative in the same axon
- spike-time-dependent plasticity is the signature of backpropagation learning
- the problem that each bottom-up connection needs to have a corresponding top-down connection in a non-problem: random top-down weights work just fine"
"Hinton starts with a discussion on how the brain probably implements something equivalent to backpropagation, despite several huge objections from neuroscience. He reviews how unsupervised learning techniques can help augment/expand the training signal. Next he discusses the brain's immense size (10^14 parameters) relative to supervision bits/training data indicates the brain is operating with a high model/data complexity ratio. He discusses how this is actually ideal in the bayesian sense - more data is always good, and a larger model is always good - provided your model is properly regularized. The best (bayesian) regularization amounts to ensembling over the entire model space. Dropout is an effective trick to approximate that, and dropout is just a particular type of multiplicative noise. He then shows how neural Poisson spiking can implement multiplicative noise - and thus dropout style ensembling. Rest of the talk focuses on how spiking nets can implement backpropagation equivalent credit assignment (error derivatives as temporal derivatives). Autoencoders that learn asymmetric but matched weights, and the 'miracle' in 2014 when Lillicrap et al showed that backpropagation can even work (almost as well) using random, fixed, untrained asymmetric back connections. Conclusion: the brain really is a deep neural network, spikes are just a form of dropout regularization, error derivatives can be represented as temporal derivatives (backpropagation with spike timing dependent plasticity), connections symmetry doesn't matter."
videohttp://youtube.com/watch?v=VIRCybGgHts (Hinton)videohttp://youtube.com/watch?v=cBLk5baHbZ8 (Hinton)videohttp://sms.cam.ac.uk/media/2017973 (38:00) (Hinton)
"Towards Biologically Plausible Deep Learning" Bengio, Lee, Bornschein, Lin
"Neuroscientists have long criticised deep learning algorithms as incompatible with current knowledge of neurobiology. We explore more biologically plausible versions of deep representation learning, focusing here mostly on unsupervised learning but developing a learning mechanism that could account for supervised, unsupervised and reinforcement learning. The starting point is that the basic learning rule believed to govern synaptic weight updates (Spike-Timing-Dependent Plasticity) can be interpreted as gradient descent on some objective function so long as the neuronal dynamics push firing rates towards better values of the objective function (be it supervised, unsupervised, or reward-driven). The second main idea is that this corresponds to a form of the variational EM algorithm, i.e., with approximate rather than exact posteriors, implemented by neural dynamics. Another contribution of this paper is that the gradients required for updating the hidden states in the above variational interpretation can be estimated using an approximation that only requires propagating activations forward and backward, with pairs of layers learning to form a denoising auto-encoder. Finally, we extend the theory about the probabilistic interpretation of auto-encoders to justify improved sampling schemes based on the generative interpretation of denoising auto-encoders, and we validate all these ideas on generative learning tasks."
"Deep learning and artificial neural networks have taken their inspiration from brains, but mostly for the form of the computation performed (with much of the biology, such as the presence of spikes remaining to be accounted for). However, what is lacking currently is a credible machine learning interpretation of the learning rules that seem to exist in biological neurons that would explain joint training of a deep neural network, i.e., accounting for credit assignment through a long chain of neural connections. Solving the credit assignment problem therefore means identifying neurons and weights that are responsible for a desired outcome and changing parameters accordingly. Whereas back-propagation offers a machine learning answer, it is not biologically plausible:
(1) the back-propagation computation (coming down from the output layer to lower hidden layers) is purely linear, whereas biological neurons interleave linear and non-linear operations,
(2) if the feedback paths known to exist in the brain (with their own synapses and maybe their own neurons) were used to propagate credit assignment by backprop, they would need precise knowledge of the derivatives of the non-linearities at the operating point used in the corresponding feedforward computation on the feedforward path,
(3) similarly, these feedback paths would have to use exact symmetric weights (with the same connectivity, transposed) of the feedforward connections,
(4) real neurons communicate by (possibly stochastic) binary values (spikes), not by clean continuous values,
(5) the computation would have to be precisely clocked to alternate between feedforward and back-propagation phases (since the latter needs the former’s results),
(6) it is not clear where the output targets would come from."
"The approach proposed in this paper has the ambition to address all these issues, although some question marks as to a possible biological implementations remain, and of course many details of the biology that need to be accounted for are not covered here. Note that back-propagation is used not just for classical supervised learning but also for many unsupervised learning algorithms, including all kinds of auto-encoders: sparse auto-encoders, denoising auto-encoders, contractive auto-encoders, and more recently, variational auto-encoders. Other unsupervised learning algorithms exist which do not rely on back-propagation, such as the various Boltzmann machine learning algorithms. Boltzmann machines are probably the most biologically plausible learning algorithms for deep architectures that we currently know, but they also face several question marks in this regard, such as the weight transport problem ((3) above) to achieve symmetric weights, and the positive-phase vs negative-phase synchronization question (similar to (5) above)."
Our starting point proposes an interpretation of the main learning rule observed in biological synapses: Spike-Timing-Dependent Plasticity. Following up on the ideas presented in Hinton’s 2007 talk, we first argue that STDP could be seen as stochastic gradient descent if only the neuron was driven by a feedback signal that either increases or decreases the neuron’s firing rate in proportion to the gradient of an objective function with respect to the neuron’s voltage potential. We then argue that the above interpretation suggests that neural dynamics (which creates the above changes in neuronal activations thanks to feedback and lateral connections) correspond to inference towards neural configurations that are more consistent with each other and with the observations (inputs, targets, or rewards). This view extends Hinton’s supervised learning proposal to the unsupervised generative setting. It naturally suggests that the training procedure corresponds to a form of variational EM, possibly based on MAP (maximum a posteriori) or MCMC (Markov Chain Monte-Carlo) approximations. Then we show how this mathematical framework suggests a training procedure for a deep generative network with many layers of latent variables. However, the above interpretation would still require to compute some gradients. Another contribution is to show that one can estimate these gradients via an approximation that only involves ordinary neural computation and no explicit derivatives, following previous work on target propagation."
"We consider this paper as an exploratory step towards explaining a central aspect of the brain’s learning algorithm: credit assignment through many layers. Departing from back-propagation could be useful not just for biological plausibility but from a machine learning point of view as well: by working on the “targets” for the intermediate layers, we may avoid the kind of reliance on smoothness and derivatives that characterizes back-propagation, as these techniques can in principle work even with highly non-linear transformations for which gradients are often near 0, e.g., with stochastic binary units. Besides the connection between STDP and variational EM, an important contribution of this paper is to show that the “targetprop” update which estimates the gradient through one layer can be used for inference, yielding systematic improvements in the joint likelihood and allowing to learn a good generative model. Another interesting contribution is that the variational EM updates, with noise added, can also be interpreted as training a denoising auto-encoder over both visible and latent variables, and that iterating from the associated Markov chain yields better samples than those obtained from the directed graphical model estimated by variational EM. Many directions need to be investigated to follow-up on the work reported here. An important element of neural circuitry is the strong presence of lateral connections between nearby neurons in the same area. In the proposed framework, an obvious place for such lateral connections is to implement the prior on the joint distribution between nearby neurons, something we have not explored in our experiments. For example, Garrigues & Olshausen have discussed neural implementations of the inference involved in sparse coding based on the lateral connections. Although we have found that “injecting noise” helped training a better model, more theoretical work needs to be done to explore this replacement of a MAP-based inference by an MCMC-like inference, which should help determine how and how much of this noise should be injected. Whereas this paper focused on unsupervised learning, these ideas could be applied to supervised learning and reinforcement learning as well. For reinforcement learning, an important role of the proposed algorithms is to learn to predict rewards, although a more challenging question is how the MCMC part could be used to simulate future events. For both supervised learning and reinforcement learning, we would probably want to add a mechanism that would give more weight to minimizing prediction (or reconstruction) error for some of the observed signals (e.g. y is more important to predict than x). Finally, a lot needs to be done to connect in more detail the proposals made here with biology, including neural implementation using spikes with Poisson rates as the source of signal quantization and randomness, taking into account the constraints on the sign of the weights depending on whether the pre-synaptic neuron is inhibitory or excitatory, etc. In addition, although the operations proposed here are backprop-free, they may still require some kinds of synchronizations (or control mechanism) and specific connectivity to be implemented in brains."
"We explore the following crucial question: how could brains potentially perform the kind of powerful credit assignment that allows hidden layers of a very deep network to be trained and that has been so successful with deep learning recently? Global reinforcement learning signals have too much variance (scaling with the number of neurons or synapses) to be credible (by themselves) from a machine learning point of view. Concerns have been raised about how something like back-propagation could be implemented in brains. We present several intriguing results all aimed at answering this question and possibly providing pieces of this puzzle. We start with an update rule that yields updates similar to STDP but that is anchored in quantities such as pre-synaptic and post-synaptic firing rates and temporal rates of change. We then show that if neurons are connected symmetrically and thus define an energy function, (a) their behaviour corresponds to inference, i.e., going down the energy, and (b) after a prediction is made on a sensor and an actual value is observed, the early phases of inference in this network actually propagate prediction error gradients, and (c) using the above STDP-inspired rule yields a gradient descent step on prediction error for feedforward weights. This is based on a new mathematical result which provides a more general framework for machine learning to train dynamical systems at equilibrium. Finally, we discuss some of the limitations of the current model (such as the forced symmetry of synaptic weights and the question of learning the full joint distribution and not just a point prediction, and how to train dynamical systems which are generally not near their equilibrium points) as well as ideas around them."
"My perspective is that we know that there are certain ways in which backpropagation is limited to such an extent that it can't be close to what the brain does, so it's interesting to explore biological inspirations for how we can get around these limitations. Here are the major limitations, in my view:
- Backpropagation doesn't really work in an online setting, because you need to traverse the whole graph of nodes every time you make an update. Of course, you can truncate the update to recently computed nodes (truncated BPTT) but this limits the length of the dependencies that can be learned.
- Backpropagation requires all nodes to be stored in memory.
- I think this is a less important limitation, but many neural architectures require parameter sharing, which isn't necessarily achievable in the brain."
videohttps://youtube.com/watch?v=TvZLAyOByMQ (Bengio)videohttps://youtube.com/watch?v=W86H4DpFnLY (Bengio)videohttps://archive.org/details/Redwood_Center_2016_09_27_Yoshua_Bengio (Bengio)videohttp://youtube.com/watch?v=lKVIXI8Djv4 (Bengio)videohttp://youtu.be/exhdfIPzj24?t=59m13s (Bengio)slideshttp://iro.umontreal.ca/~bengioy/talks/Brains+Bits-NIPS2016Workshop.pptx.pdf
"Random Feedback Weights Support Learning in Deep Neural Networks" Lillicrap, Cownden, Tweed, Akerman
"The brain processes information through many layers of neurons. This deep architecture is representationally powerful, but it complicates learning by making it hard to identify the responsible neurons when a mistake is made. In machine learning, the backpropagation algorithm assigns blame to a neuron by computing exactly how it contributed to an error. To do this, it multiplies error signals by matrices consisting of all the synaptic weights on the neuron’s axon and farther downstream. This operation requires a precisely choreographed transport of synaptic weight information, which is thought to be impossible in the brain. Here we present a surprisingly simple algorithm for deep learning, which assigns blame by multiplying error signals by random synaptic weights. We show that a network can learn to extract useful information from signals sent through these random feedback connections. In essence, the network learns to learn. We demonstrate that this new mechanism performs as quickly and accurately as backpropagation on a variety of problems and describe the principles which underlie its function. Our demonstration provides a plausible basis for how a neuron can be adapted using error signals generated at distal locations in the brain, and thus dispels long-held assumptions about the algorithmic constraints on learning in neural circuits."
paperhttp://www.nature.com/articles/ncomms13276.epdf ("Nature")videohttp://youtu.be/-kHLKLLxIF4?t=20m28s (Lillicrap)
"Artificial neural networks are most commonly trained with the back-propagation algorithm, where the gradient for learning is provided by back-propagating the error, layer by layer, from the output layer to the hidden layers. A recently discovered method called feedback-alignment shows that the weights used for propagating the error backward don't have to be symmetric with the weights used for propagation the activation forward. In fact, random feedback weights work evenly well, because the network learns how to make the feedback useful. In this work, the feedback alignment principle is used for training hidden layers more independently from the rest of the network, and from a zero initial condition. The error is propagated through fixed random feedback connections directly from the output layer to each hidden layer. This simple method is able to achieve zero training error even in convolutional networks and very deep networks, completely without error back-propagation. The method is a step towards biologically plausible machine learning because the error signal is almost local, and no symmetric or reciprocal weights are required. Experiments show that the test performance on MNIST and CIFAR is almost as good as those obtained with back-propagation for fully connected networks. If combined with dropout, the method achieves 1.45% error on the permutation invariant MNIST task."
"Assessing the Scalability of Biologically-motivated Deep Learning Algorithms and Architectures" Bartunov, Santoro, Richards, Hinton, Lillicrap
Simplified Difference Target Propagation
"The backpropagation of error algorithm is often said to be impossible to implement in a real brain. The recent success of deep networks in machine learning and AI, however, has inspired a number of proposals for understanding how the brain might learn across multiple layers, and hence how it might implement or approximate BP. As of yet, none of these proposals have been rigorously evaluated on tasks where BP-guided deep learning has proved critical, or in architectures more structured than simple fully-connected networks. Here we present the first results on scaling up a biologically motivated model of deep learning to datasets which need deep networks with appropriate architectures to achieve good performance. We present results on CIFAR-10 and ImageNet. For CIFAR-10 we show that our algorithm, a straightforward, weight-transport-free variant of difference target-propagation modified to remove backpropagation from the penultimate layer, is competitive with BP in training deep networks with locally defined receptive fields that have untied weights. For ImageNet we find that both DTP and our algorithm perform significantly worse than BP, opening questions about whether different architectures or algorithms are required to scale these approaches. Our results and implementation details help establish baselines for biologically motivated deep learning schemes going forward."
"- No weight transport (i.e. weight transposes)
- No weight tying (i.e. convolutional kernels)
- No feedback of signed errors
But still:- Use continuous rather than spiking signals
- Use separate forward and backward passes
- Use local activation derivatives"
videohttp://youtu.be/-kHLKLLxIF4?t=32m37s (Lillicrap)videohttp://youtube.com/watch?v=XzSRtu413CY (Lillicrap)
interesting papers - reinforcement learning - applications
"Learning Representations for Counterfactual Inference" Johansson, Shalit, Sontag
"Domain-Adversarial Training of Neural Networks" Ganin, Ustinova, Ajakan, Germain, Larochelle, Laviolette, Marchand, Lempitsky
"We introduce a new representation learning approach for domain adaptation, in which data at training and test time come from similar but different distributions. Our approach is directly inspired by the theory on domain adaptation suggesting that, for effective domain transfer to be achieved, predictions must be made based on features that cannot discriminate between the training (source) and test (target) domains. The approach implements this idea in the context of neural network architectures that are trained on labeled data from the source domain and unlabeled data from the target domain (no labeled target-domain data is necessary). As the training progresses, the approach promotes the emergence of features that are (i) discriminative for the main learning task on the source domain and (ii) indiscriminate with respect to the shift between the domains. We show that this adaptation behaviour can be achieved in almost any feed-forward model by augmenting it with few standard layers and a new gradient reversal layer. The resulting augmented architecture can be trained using standard backpropagation and stochastic gradient descent, and can thus be implemented with little effort using any of the deep learning packages. We demonstrate the success of our approach for two distinct classification problems (document sentiment analysis and image classification), where state-of-the-art domain adaptation performance on standard benchmarks is achieved. We also validate the approach for descriptor learning task in the context of person re-identification application."
videohttp://videolectures.net/icml2015_ganin_domain_adaptation/ (Ganin)videohttp://youtu.be/FpZqmnOB-R8?t=9m (Lempitsky)in russiannoteshttp://www.shortscience.org/paper?bibtexKey=journals/corr/1409.7495codehttps://github.com/pumpikano/tf-dannpaper"Unsupervised Domain Adaptation by Backpropagation" by Ganin and Lempitsky
"Unsupervised Cross-Domain Image Generation" Taigman, Polyak, Wolf
"We study the problem of transferring a sample in one domain to an analog sample in another domain. Given two related domains, S and T, we would like to learn a generative function G that maps an input sample from S to the domain T, such that the output of a given function f, which accepts inputs in either domains, would remain unchanged. Other than the function f, the training data is unsupervised and consist of a set of samples from each domain. The Domain Transfer Network (DTN) we present employs a compound loss function that includes a multiclass GAN loss, an f-constancy component, and a regularizing component that encourages G to map samples from T to themselves. We apply our method to visual domains including digits and face images and demonstrate its ability to generate convincing novel images of previously unseen entities, while preserving their identity."
"Given separated but otherwise unlabeled samples from domains S and T and a multivariate function f, learn a mapping G: S→ T such that f(x)∼ f(G(x)). In order to solve this problem, we make use of deep neural networks of a specific structure in which the function G is a composition of the input function f and a learned function g. A compound loss that integrates multiple terms is used. One term is a Generative Adversarial Network (GAN) term that encourages the creation of samples G(x) that are indistinguishable from the training samples of the target domain, regardless of x∈ S or x∈ T. The second loss term enforces that for every x in the source domain training set, ||f(x)−f(G(x))|| is small. The third loss term is a regularizer that encourages G to be the identity mapping for all x∈ T."
"The type of problems we focus on in our experiments are visual, although our methods are not limited to visual or even to perceptual tasks. Typically, f would be a neural network representation that is taken as the activations of a network that was trained, e.g., by using the cross entropy loss, in order to classify or to capture identity."
"As a main application challenge, we tackle the problem of emoji generation for a given facial image. Despite a growing interest in emoji and the hurdle of creating such personal emoji manually, no system has been proposed, to our knowledge, that can solve this problem. Our method is able to produce face emoji that are visually appealing and capture much more of the facial characteristics than the emoji created by well-trained human annotators who use the conventional tools."
"Asymmetry is central to our work. Not only does our solution handle the two domains S and T differently, the function f is unlikely to be equally effective in both domains since in most practical cases, f would be trained on samples from one domain. While an explicit domain adaptation step can be added in order to make f more effective on the second domain, we found it to be unnecessary. Adaptation of f occurs implicitly due to the application of D downstream."
"Using the same function f, we can replace the roles of the two domains, S and T. For example, we can synthesize an SVHN image that resembles a given MNIST image, or synthesize a face that matches an emoji."
"Unsupervised domain adaptation addresses the following problem: given a labeled training set in S×Y, for some target space Y, and an unlabeled set of samples from domain T, learn a function h:T → Y (Chen et al., 2012; Ganin et al., 2016). One can solve the sample transfer problem using domain adaptation and vice versa. In both cases, the solution is indirect. In order to solve domain adaptation using domain transfer, one would learn a function from S to Y and use it as the input method of the domain transfer algorithm in order to obtain a map from S to T. The training samples could then be transferred to T and used to learn a classifier there. In the other direction, given the function f, one can invert f in the domain T by generating training samples (f(x), x) for x∈ T and learn from them a function h from f(T) = {f(x)|x∈ T} to T. Domain adaptation can then be used in order to map f(S) = {f(x)|x∈ S} to T, thus achieving domain transfer."
"Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation" Wu et al.
"Neural Machine Translation is an end-to-end learning approach for automated translation, with the potential to overcome many of the weaknesses of conventional phrase-based translation systems. Unfortunately, NMT systems are known to be computationally expensive both in training and in translation inference. Also, most NMT systems have difficulty with rare words. These issues have hindered NMT's use in practical deployments and services, where both accuracy and speed are essential. In this work, we present GNMT, Google's Neural Machine Translation system, which attempts to address many of these issues. Our model consists of a deep LSTM network with 8 encoder and 8 decoder layers using attention and residual connections. To improve parallelism and therefore decrease training time, our attention mechanism connects the bottom layer of the decoder to the top layer of the encoder. To accelerate the final translation speed, we employ low-precision arithmetic during inference computations. To improve handling of rare words, we divide words into a limited set of common sub-word units ("wordpieces") for both input and output. This method provides a good balance between the flexibility of "character"-delimited models and the efficiency of "word"-delimited models, naturally handles translation of rare words, and ultimately improves the overall accuracy of the system. Our beam search technique employs a length-normalization procedure and uses a coverage penalty, which encourages generation of an output sentence that is most likely to cover all the words in the source sentence. On the WMT'14 English-to-French and English-to-German benchmarks, GNMT achieves competitive results to state-of-the-art. Using a human side-by-side evaluation on a set of isolated simple sentences, it reduces translation errors by an average of 60% compared to Google's phrase-based production system."
"A Neural Network for Factoid Question Answering over Paragraphs" Iyyer, Boyd-Graber, Claudino, Socher, Daume
"A Neural Conversational Model" Vinyals, Le
"Conversational modeling is an important task in natural language understanding and machine intelligence. Although previous approaches exist, they are often restricted to specific domains (e.g., booking an airline ticket) and require hand-crafted rules. In this paper, we present a simple approach for this task which uses the recently proposed sequence to sequence framework. Our model converses by predicting the next sentence given the previous sentence or sentences in a conversation. The strength of our model is that it can be trained end-to-end and thus requires much fewer hand-crafted rules. We find that this straightforward model can generate simple conversations given a large conversational training dataset. Our preliminary suggest that, despite optimizing the wrong objective function, the model is able to extract knowledge from both a domain specific dataset, and from a large, noisy, and general domain dataset of movie subtitles. On a domain-specific IT helpdesk dataset, the model can find a solution to a technical problem via conversations. On a noisy open-domain movie transcript dataset, the model can perform simple forms of common sense reasoning. As expected, we also find that the lack of consistency is a common failure mode of our model."
"In this paper, we show that a simple language model based on the seq2seq framework can be used to train a conversational engine. Our modest results show that it can generate simple and basic conversations, and extract knowledge from a noisy but open-domain dataset. Even though the model has obvious limitations, it is surprising to us that a purely data driven approach without any rules can produce rather proper answers to many types of questions. However, the model may require substantial modifications to be able to deliver realistic conversations. Amongst the many limitations, the lack of a coherent personality makes it difficult for our system to pass the Turing test."
"We find it encouraging that the model can remember facts, understand contexts, perform common sense reasoning without the complexity in traditional pipelines. What surprises us is that the model does so without any explicit knowledge representation component except for the parameters in the word vectors. Perhaps most practically significant is the fact that the model can generalize to new questions. In other words, it does not simply look up for an answer by matching the question with the existing database. In fact, most of the questions presented above, except for the first conversation, do not appear in the training set. Nonetheless, one drawback of this basic model is that it only gives simple, short, sometimes unsatisfying answers to our questions as can be seen above. Perhaps a more problematic drawback is that the model does not capture a consistent personality. Indeed, if we ask not identical but semantically similar questions, the answers can sometimes be inconsistent."
"Unlike easier tasks like translation, however, a model like sequence to sequence will not be able to successfully “solve” the problem of modeling dialogue due to several obvious simplifications: the objective function being optimized does not capture the actual objective achieved through human communication, which is typically longer term and based on exchange of information rather than next step prediction. The lack of a model to ensure consistency and general world knowledge is another obvious limitation of a purely unsupervised model."
noteshttp://www.shortscience.org/paper?bibtexKey=journals/corr/VinyalsL15codehttps://github.com/macournoyer/neuralconvocodehttps://github.com/deepcoord/seq2seqcodehttps://github.com/farizrahman4u/seq2seqcodehttps://github.com/nicolas-ivanov/lasagne_seq2seqcodehttps://github.com/pbhatia243/Neural_Conversation_Models
"Learning to Discover Efficient Mathematical Identities" Zaremba, Kurach, Fergus
"In this paper we explore how machine learning techniques can be applied to the discovery of efficient mathematical identities. We introduce an attribute grammar framework for representing symbolic expressions. Given a grammar of math operators, we build trees that combine them in different ways, looking for compositions that are analytically equivalent to a target expression but of lower computational complexity. However, as the space of trees grows exponentially with the complexity of the target expression, brute force search is impractical for all but the simplest of expressions. Consequently, we introduce two novel learning approaches that are able to learn from simpler expressions to guide the tree search. The first of these is a simple n-gram model, the other being a recursive neural network. We show how these approaches enable us to derive complex identities, beyond reach of brute-force search, or human derivation."
videohttp://youtube.com/watch?v=Hx20MUmWAfg (Fergus)
"Convolutional Networks on Graphs for Learning Molecular Fingerprints" Duvenaud, Maclaurin, Aguilera-Iparraguirre, Gomez-Bombarelli, Hirzel, Aspuru-Guzik, Adams
"We introduce a convolutional neural network that operates directly on graphs. These networks allow end-to-end learning of prediction pipelines whose inputs are graphs of arbitrary size and shape. The architecture we present generalizes standard molecular feature extraction methods based on circular fingerprints. We show that these data-driven features are more interpretable, and have better predictive performance on a variety of tasks."
"We generalized existing hand-crafted molecular features to allow their optimization for diverse tasks. By making each operation in the feature pipeline differentiable, we can use standard neural-network training methods to scalably optimize the parameters of these neural molecular fingerprints end-toend. We demonstrated the interpretability and predictive performance of these new fingerprints. Data-driven features have already replaced hand-crafted features in speech recognition, machine vision, and natural-language processing. Carrying out the same task for virtual screening, drug design, and materials design is a natural next step."
"Automatic Chemical Design using a Data-driven Continuous Representation of Molecules" Gomez-Bombarelli, Duvenaud, Hernandez-Lobato, Aguilera-Iparraguirre, Hirzel, Adams, Aspuru-Guzik
"We report a method to convert discrete representations of molecules to and from a multidimensional continuous representation. This generative model allows efficient search and optimization through open-ended spaces of chemical compounds. We train deep neural networks on hundreds of thousands of existing chemical structures to construct two coupled functions: an encoder and a decoder. The encoder converts the discrete representation of a molecule into a real-valued continuous vector, and the decoder converts these continuous vectors back to the discrete representation from this latent space. Continuous representations allow us to automatically generate novel chemical structures by performing simple operations in the latent space, such as decoding random vectors, perturbing known chemical structures, or interpolating between molecules. Continuous representations also allow the use of powerful gradient-based optimization to efficiently guide the search for optimized functional compounds. We demonstrate our method in the design of drug-like molecules as well as organic light-emitting diodes."
"End to End Learning for Self-Driving Cars" Bojarski et al.
"We trained a convolutional neural network to map raw pixels from a single front-facing camera directly to steering commands. This end-to-end approach proved surprisingly powerful. With minimum training data from humans the system learns to drive in traffic on local roads with or without lane markings and on highways. It also operates in areas with unclear visual guidance such as in parking lots and on unpaved roads. The system automatically learns internal representations of the necessary processing steps such as detecting useful road features with only the human steering angle as the training signal. We never explicitly trained it to detect, for example, the outline of roads. Compared to explicit decomposition of the problem, such as lane marking detection, path planning, and control, our end-to-end system optimizes all processing steps simultaneously. We argue that this will eventually lead to better performance and smaller systems. Better performance will result because the internal components self-optimize to maximize overall system performance, instead of optimizing human-selected intermediate criteria, e.g., lane detection. Such criteria understandably are selected for ease of human interpretation which doesn’t automatically guarantee maximum system performance. Smaller networks are possible because the system learns to solve the problem with the minimal number of processing steps."
posthttps://devblogs.nvidia.com/parallelforall/deep-learning-self-driving-cars/videohttps://youtube.com/watch?v=-96BEoXJMs0 + https://drive.google.com/file/d/0B9raQzOpizn1TkRIa241ZnBEcjQ/view (demo)posthttps://blog.piekniewski.info/2016/11/03/reactive-vs-predictive-ai/codehttps://github.com/SullyChen/Nvidia-Autopilot-TensorFlow
"DeepSpeech: Scaling up end-to-end speech recognition" Hannun, Case, Casper, Catanzaro, Diamos, Elsen, Prenger, Satheesh, Sengupta, Coates, Ng
"We present a state-of-the-art speech recognition system developed using end-to-end deep learning. Our architecture is significantly simpler than traditional speech systems, which rely on laboriously engineered processing pipelines; these traditional systems also tend to perform poorly when used in noisy environments. In contrast, our system does not need hand-designed components to model background noise, reverberation, or speaker variation, but instead directly learns a function that is robust to such effects. We do not need a phoneme dictionary, nor even the concept of a "phoneme." Key to our approach is a well-optimized RNN training system that uses multiple GPUs, as well as a set of novel data synthesis techniques that allow us to efficiently obtain a large amount of varied data for training. Our system, called DeepSpeech, outperforms previously published results on the widely studied Switchboard Hub5'00, achieving 16.5% error on the full test set. DeepSpeech also handles challenging noisy environments better than widely used, state-of-the-art commercial speech systems."
videohttp://youtube.com/watch?v=kAnJdvf_KeE (demo)videohttp://on-demand.gputechconf.com/gtc/2015/video/S5631.html (Catanzaro)videohttp://youtube.com/watch?v=P9GLDezYVX4 (Hannun)
"Multiple Object Recognition With Visual Attention" Ba, Mnih, Kavukcuoglu
"We present an attention-based model for recognizing multiple objects in images. The proposed model is a deep recurrent neural network trained with reinforcement learning to attend to the most relevant regions of the input image. We show that the model learns to both localize and recognize multiple objects despite being given only class labels during training. We evaluate the model on the challenging task of transcribing house number sequences from Google Street View images and show that it is both more accurate than the state-of-the-art convolutional networks and uses fewer parameters and less computation."
"Applying convolutional neural networks to large images is computationally expensive because the amount of computation scales linearly with the number of image pixels. We present a novel recurrent neural network model that is capable of extracting information from an image or video by adaptively selecting a sequence of regions or locations and only processing the selected regions at high resolution. Like convolutional neural networks, the proposed model has a degree of translation invariance built-in, but the amount of computation it performs can be controlled independently of the input image size. While the model is non-differentiable, it can be trained using reinforcement learning methods to learn task-specific policies. We evaluate our model on several image classification tasks, where it significantly outperforms a convolutional neural network baseline on cluttered images, and on a dynamic visual control problem, where it learns to track a simple object without an explicit training signal for doing so."
videohttp://youtube.com/watch?v=xzM7eI7caRk (Mnih)videohttp://youtu.be/kUiR0RLmGCo?t=15m30s (de Freitas)
"Deep Structured Output Learning For Unconstrained Text Recognition" Jaderberg, Simonyan, Vedaldi, Zisserman
"We develop a representation suitable for the unconstrained recognition of words in natural images, where unconstrained means that there is no fixed lexicon and words have unknown length. To this end we propose a convolutional neural network based architecture which incorporates a Conditional Random Field graphical model, taking the whole word image as a single input. The unaries of the CRF are provided by a CNN that predicts characters at each position of the output, while higher order terms are provided by another CNN that detects the presence of N-grams. We show that this entire model (CRF, character predictor, N-gram predictor) can be jointly optimised by back-propagating the structured output loss, essentially requiring the system to perform multi-task learning, and training requires only synthetically generated data. The resulting model is a more accurate system on standard real-world text recognition benchmarks than character prediction alone, setting a benchmark for systems that have not been trained on a particular lexicon. In addition, our model achieves state-of-the-art accuracy in lexicon-constrained scenarios, without being specifically modelled for constrained recognition. To test the generalisation of our model, we also perform experiments with random alpha-numeric strings to evaluate the method when no visual language model is applicable."
"In this work we tackle the problem of unconstrained text recognition – recognising text in natural images without restricting the words to a fixed lexicon or dictionary. Usually this problem is decomposed into a word detection stage followed by a word recognition stage. The word detection stage generates bounding boxes around words in an image, while the word recognition stage takes the content of these bounding boxes and recognises the text within."
"The dictionary-free joint model proposed here is trained by defining a structured output learning problem, and back-propagating the corresponding structured output loss. This formulation results in multi-task learning of both the character and N-gram predictors, and additionally learns how to combine their representations in the CRF, resulting in more accurate text recognition. The result is a highly flexible text recognition system that achieves excellent unconstrained text recognition performance as well as state-of-the-art recognition performance when using standard dictionary constraints. While performance is measured on real images as contained in standard text recognition benchmarks, all results are obtained by training the model purely on synthetic data."
"In this paper we have introduced a new formulation for word recognition, designed to be used identically in language and non-language scenarios. By modelling character positions and the presence of common N-grams, we can define a joint graphical model. This can be trained effectively by backpropagating structured output loss, and results in a more accurate word recognition system than predicting characters alone. We show impressive results for unconstrained text recognition with the ability to generalise recognition to previously unseen words, and match state-of-the-art accuracy when comparing in lexicon constrained scenarios."
videohttp://youtube.com/watch?v=NYkG38RCoRg (Jaderberg)
"Deep Value Networks Learn to Evaluate and Iteratively Refine Structured Outputs" Gygli, Norouzi, Angelova
"We approach structured output prediction by learning a deep value network (DVN) that evaluates different output structures for a given input. For example, when applied to image segmentation, the value network takes an image and a segmentation mask as inputs and predicts a scalar score evaluating the mask quality and its correspondence with the image. Once the value network is optimized, at inference, it finds output structures that maximize the score of the value net via gradient descent on continuous relaxations of structured outputs. Thus DVN takes advantage of the joint modeling of the inputs and outputs. Our framework applies to a wide range of structured output prediction problems. We conduct experiments on multi-label classification based on text data and on image segmentation problems. DVN outperforms several strong baselines and the state-of-the-art results on these benchmarks. In addition, on image segmentation, the proposed deep value network learns complex shape priors and effectively combines image information with the prior to obtain competitive segmentation results."
"To enable effective iterative refinement of structured outputs via gradient descent on the score of a DVN, we relax our outputs to live in a continuous space instead of a discrete space, and extend the domain of loss function so the loss applies to continuous variable outputs. Then, we train a DVN on many output examples encouraging the network to predict very accurate (negative) loss scores for any output hypothesis. We generate the output hypotheses via gradient descent at training time, so that the value net’s estimate around the inference trajectory is as accurate as possible. We also generate output hypotheses by finding adversarial cases. Once the value network is optimized, at inference, it finds output structures that maximize the score via gradient ascent on continuous relaxations of structured outputs."
"deep value network that evaluates different output structures for a given input + gradient descent inference algorithm for structured output prediction"
videohttps://vimeo.com/238243269 (Norouzi)
"Show, Attend and Tell: Neural Image Caption Generation with Visual Attention" Xu, Ba, Kiros, Cho, Courville, Salakhutdinov, Zemel, Bengio
"Inspired by recent work in machine translation and object detection, we introduce an attention based model that automatically learns to describe the content of images. We describe how we can train this model in a deterministic manner using standard backpropagation techniques and stochastically by maximizing a variational lower bound. We also show through visualization how the model is able to automatically learn to fix its gaze on salient objects while generating the corresponding words in the output sequence. We validate the use of attention with state-of-the-art performance on three benchmark datasets: Flickr8k, Flickr30k and MS COCO."
videohttp://videolectures.net/deeplearning2015_salakhutdinov_deep_learning_2/#t=739 (Salakhutdinov)videohttp://videolectures.net/icml2015_xu_visual_attention/ (Xu)videohttps://youtu.be/_XRBlhzb31U?t=3m27s (Figurnov)in russiancodehttps://github.com/kelvinxu/arctic-captions
"Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks" Denton, Chintala, Szlam, Fergus
"In this paper we introduce a generative parametric model capable of producing high quality samples of natural images. Our approach uses a cascade of convolutional networks within a Laplacian pyramid framework to generate images in a coarse-to-fine fashion. At each level of the pyramid, a separate generative convnet model is trained using the Generative Adversarial Nets approach. Samples drawn from our model are of significantly higher quality than alternate approaches. In a quantitative assessment by human evaluators, our CIFAR10 samples were mistaken for real images around 40% of the time, compared to 10% for samples drawn from a GAN baseline model. We also show samples from models trained on the higher resolution images of the LSUN scene dataset."
"We have proposed a conceptually simple generative model that is able to produce high-quality sample images that are both qualitatively and quantitatively better than other deep generative modeling approaches. A key point in our work is giving up any “global” notion of fidelity, and instead breaking the generation into plausible successive refinements. We note that many other signal modalities have a multiscale structure that may benefit from a similar approach."
"One of the easiest thing a generative network can do to generate realistic samples is to simply copy the training images. This is not a true generative model that generalizes to all natural images, but one that overfit heavily on the training set. This is something we meticulously checked while training our networks, i.e. that our network is simply not copying the training samples."
"Drawing samples conditioned on the same initial image gives us the ability to see if the variability in producing the samples is trivial (copying), or non-trivial. We did a few experiments on the LSUN database and concluded that our samples are fairly different for every draw. For example, the network changes the building architectures, places and removes windows, adds extra tunnels and hulls (and sometimes extra towers) and creates details that are different everytime a sample is drawn."
"There are so many things to explore, as follow-up work to this paper. A list of simple ideas would be: instead of one-hot coding, give word-embeddings as the conditional vector. Imagine the awesomeness of going from image captions to images. Apply the same exact method to generate audio and video."
- http://soumith.ch/eyescream/ (demo)
videohttp://youtube.com/watch?v=JEJk-Ug_ebI + http://research.microsoft.com/apps/video/default.aspx?id=260051 (Denton)videohttp://93.180.23.59/videos/video/2487/in/channel/1/ (Gitman)posthttp://inference.vc/generative-image-models-via-laplacian-pyramids/codehttps://github.com/facebook/eyescream
"Generative Adversarial Text to Image Synthesis" Reed, Akata, Yan, Logeswaran, Schiele, Lee
"Automatic synthesis of realistic images from text would be interesting and useful, but current AI systems are still far from this goal. However, in recent years generic and powerful recurrent neural network architectures have been developed to learn discriminative text feature representations. Meanwhile, deep convolutional generative adversarial networks have begun to generate highly compelling images of specific categories, such as faces, album covers, and room interiors. In this work, we develop a novel deep architecture and GAN formulation to effectively bridge these advances in text and image modeling, translating visual concepts from characters to pixels. We demonstrate the capability of our model to generate plausible images of birds and flowers from detailed text descriptions."
"In this work we developed a simple and effective model for generating images based on detailed visual descriptions. We demonstrated that the model can synthesize many plausible visual interpretations of a given text caption. Our manifold interpolation regularizer substantially improved the text to image synthesis on CUB. We showed disentangling of style and content, and bird pose and background transfer from query images onto text descriptions. Finally we demonstrated the generalizability of our approach to generating images with multiple objects and variable backgrounds with our results on MS-COCO dataset. In future work, we aim to further scale up the model to higher resolution images and add more types of text."