Originaltext auf: blog.digidigital.de
Da es leider immer wieder vorkommt, dass die Originaldateien eingescannter Texte nicht mehr vorliegen (oder nicht mehr gefunden werden können), muss in diesen Fällen eine Texterkennung bemüht werden, um aus den Bilddateien in den PDFs editierbaren Text zu erzeugen. Das Kommandozeilentool OCRmyPDF von James Barlow hat mir diesbezüglich schon häufig das Leben im Umgang mit eingescannten Textdateien erleichtert.
Da es ich keine einfach gehaltene grafische Benutzeroberfläche finden konnte, kam mir die Idee zu OCRthyPDF – Einer Benutzeroberfläche, die Anwendern, die nicht an die Benutzung von Kommandozeilen-Tools gewöhnt sind, den Zugang zu den grundlegenden Funktionen von OCRmyPDF ermöglicht.
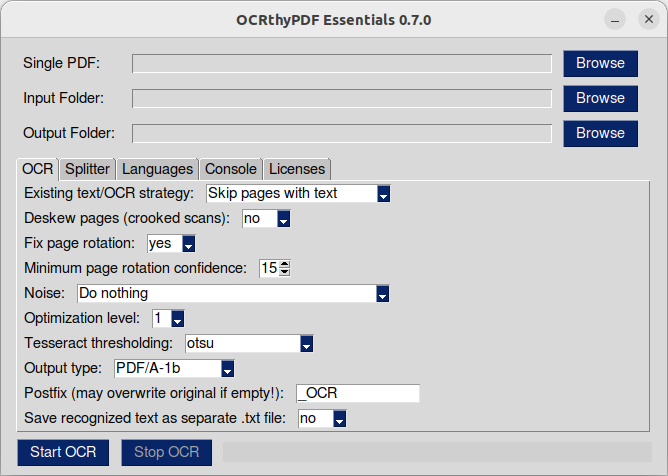
Die Splitter-Funktion erweitert die von OCRmyPDF bereitgestellte Funktionalität um die Option, gescannte Dokumente vor der Texterkennung an Trennseiten – definiert durch einen QR-Code – zu trennen. Ein QR-Code kann beispielsweise eine reine Trennseite markieren, die bei der Erstellung der Zieldokumente verworfen wird. Alternativ kann der QR-Code im Aufklebermodus (Sticker Mode) die erste Seite eines neuen Dokuments markieren und wird beibehalten.
Wenn du Ubuntu oder eine andere Linux-Distro verwendst, auf der Snap / (Gnome Software) bereits vorinstalliert ist, kannst du OCRthy PDF direkt aus dem Store installieren.

Alternativ gibst du im Terminal
sudo snap install ocrthypdf
ein.
Wenn deine Distro Gnome Software / snap nicht vorinstalliert hat, findest du hier eine Anleitung zur Installation.
Snaps werden in einer eingeschränkten Umgebung ausgeführt und benötigen Berechtigungen für den Zugriff auf Dateien auf deinem Rechner (ähnlich wie Apps auf dem Smartphone). Prüfe daher zunächst, ob du die richtigen Berechtigungen in der Benutzeroberfläche des Stores eingestellt hast.
Du kannst OCRthyPDF über das Terminal mit ocrthypdf --log INFO oder ocrthypdf --log DEBUG starten, um weitere Informationen zu erhalten, falls die Anwendung nicht wie erwartet funktioniert.
Informationen zu Unterprozessen wie OCRmyPDF, Splitter, Ghostscript usw. werden innerhalb der Registerkarte ‚Console‘ angezeigt. Setze den ‚Loglevel‘ auf DEBUG und ‚Limit console …‘ auf ’no‘ für eine detailliertere Ausgabe.
📌 Logs gecheckt und keine Ahnung, was schief gelaufen ist? Melde dein Problem hier.
Zuerst musst du ein einzelnes PDF oder einen Ordner mit PDF-Dateien auswählen, die von der Zeichenerkennung verarbeitet werden sollen. Dann gibst du einen Ordner an, in dem die neuen PDFs gespeichert werden sollen. Wenn kein Ausgabeordner ausgewählt wird, wird der Eingabeordner automatisch als Ausgabeordner vorbelegt.
Die Einstellungen in der Registerkarte „Optionen“ entsprechen den im OCRmyPDF cookbook beschriebenen Werten und funktionieren genau so. Nicht alle Kombinationen sind sinnvoll oder erlaubt. OCRthyPDF hindert dich nicht, solche Kombinationen einzustellen. In den meisten Fällen verweigert die Texterkennung einfach den Start oder bricht mit einer Fehlermeldung ab. In der Registerkarte ‚Console‘ findst du in diesen Fällen ausführliche Informationen darüber, was schief gelaufen ist.
🛑 Vorsicht! Wenn du das Postfix-Feld leer lässt und die Ausgabe in den Eingabeordner geschrieben wird, überschreibst du die Quelldatei! 🤦
Starte die Texterkennung mit der Schaltfläche „Start OCR“. Du kannst die Schaltfläche „Stop OCR“ drücken, um alle laufenden OCR-Aufträge anzuhalten.
Der Aktivitätsbalken neben den Buttons blinkt, während die OCR läuft.
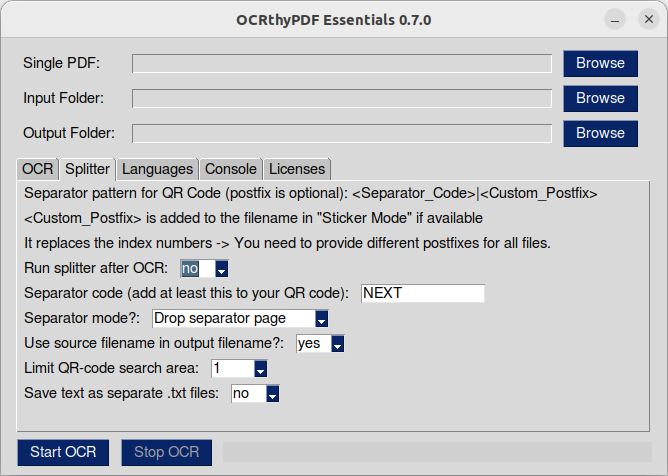
Der Splitter ermöglicht es dir, eine PDF-Datei anhand eines Barcodes / QR-Codes in einzelne Dateien aufzuteilen. Das ist praktisch, wenn du viele (mehrseitige) Dokumente scannen musst und nicht jedes Dokument einzeln in den Scanner legen möchtest. Lege einfach eine Tennseite zwischen die einzelnen Dokumente und scanne sie auf einmal!
Um den Splitter zu aktivieren, setze „Run splitter after OCR“ auf „yes“.
Im nächsten Feld musst du den Trenntext angeben. Der Splitter versucht, auf jeder Seite QR-Codes zu finden und vergleicht deren Inhalt mit diesem Text.
Der nächste Schalter wählt den Trennblattmodus aus. Standardmäßig wird die Trennseite weggelassen und nicht in die Ausgabedateien übernommen. Im Aufklebermodus (Sticker Mode) beginnt ein QR-Code ein neues Segment und die Seite wird der Ausgabe hinzugefügt. Jedes Segment/Dokument wird mit seiner Segmentnummer als Postfix gespeichert. Standard-QR-Codes mit dem Text „NEXT“ kannst du hier herunterladen.
Du kannst das Muster <SEPARATOR_TEXT>|<CUSTOM_POSTFIX> in deinen QR-Codes verwenden, um ein benutzerdefiniertes Postfix an den Dateinamen anzuhängen. Die entsprechende Funktion stellt der Sticker Modus bereit. Verwende individuelle Postfixe in jedem Code, da in diesem Modus keine Segmentnummern hinzugefügt werden, sofern ein benutzerdefiniertes Postfix gefunden wird.
📌 Beispiele für nützliche QR-Codes im Sticker-Modus:
- NEXT|Anschreiben , NEXT|Lebenslauf , NEXT|Anlagen
- NEXT|Bewerbung_Meier , NEXT|Bewerbung_Schmidt
📌 Wenn du die Option wählst, den Quelldateinamen nicht im Ausgabedateinamen zu verwenden, kannst du die Dateinamen mit Hilfe der benutzerdefinierten Postfixe festlegen (Dann auch das Postfix-Feld in der Registerkarte ‚Optionen‘ leer lassen).
Bevor Splitter mit der Analyse der Seiten einer PDF-Datei beginnt, wird die Quell-PDF-Datei mit Ghostscript umgeschrieben, um einige häufige Probleme mit PDF-Dateien, die von Scannern/MFPs erzeugt werden, zu umgehen. Splitter sucht dann in der umgeschriebenen Datei nach QR-Codes, setzt aber die geteilten Dateien direkt aus der Quelldatei zusammen.
🛑 Hinweis: Wenn du gescannte Dokumente aufteilst, die lediglich Bitmap-Bilder enthalten, sollte die Aktivierung dieser Option kein Problem darstellen. Wenn du jedoch Dokumente aufteilst, die auch andere Elemente enthalten (Text, Schriftarten, Vektorzeichnungen usw.), kann das Ergebnis von der Quelle abweichen und du verlierst ggf. einige Inhalte oder Schriften!
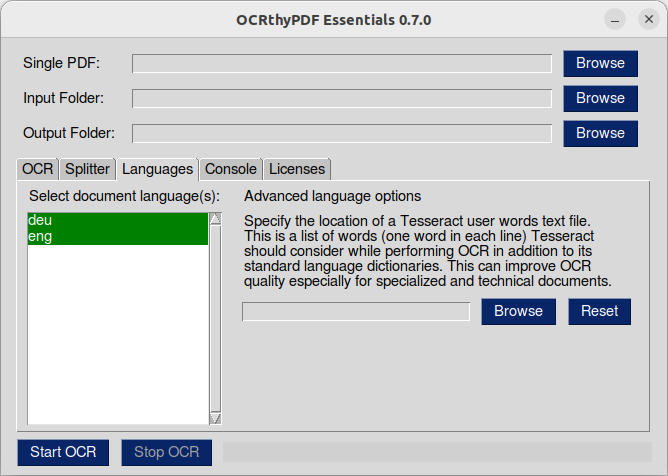
In der Registerkarte 'Languages' kannst du die Sprachen (über 100 werden unterstützt!) auswählen, die in deinen Dokumenten genutzt werden. Die Standardauswahl ist Englisch und die Sprache deiner Desktop-Umgebung. Da das Ergebnis der OCR stark von dieser Auswahl abhängt, solltest du alle Sprachen auswählen, die du benötigst, und alle anderen Sprachen abwählen!
Sprachen mit einem "best-" Prefix sollten bessere Ergebnisse erzielen, dafür dauert die Texterkennung länger.
Du kannst den Speicherort einer Textdatei für benutzerdefinierte Wörter angeben. Dies ist eine Liste von Wörtern (ein Wort in jeder Zeile), die Tesseract bei der OCR zusätzlich zu seinen Standard-Sprachwörterbüchern nutzen soll. Dies kann die Texterkennungsqualität - insbesondere bei technischen oder fachspezifischen Dokumenten - verbessern.
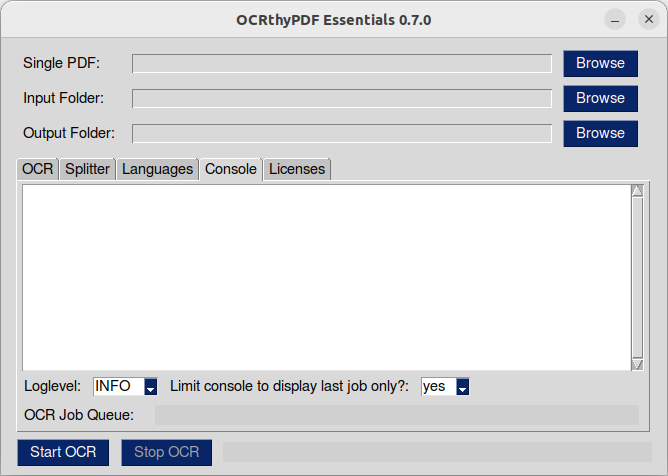
In der Konsole kannst du die Ausgabe der Prozesse sehen, die „unter der Haube“ arbeiten. Dies ist hilfreich, falls die Texterkennung anders als erwartet ausfällt oder die Anwendung mit einem Fehlercode die Dokumentenbearbeitung abbricht. du kannst zwischen den Logleveln „INFO“ (Statusmeldungen, wenn alles wie erwartet funktioniert) und „DEBUG“ (viele detaillierte Informationen) wählen. Standardmäßig zeigt die Konsole nur die Ausgabe des letzten Unterprozesses an und wird bereinigt, wenn ein neuer Unterprozess gestartet wird. Du kannst die Konsole jedoch auch so einstellen, dass sie die Informationen aller Unterprozesse eines OCR-Auftrages ohne Bereinigung anzeigt.
Der Balken am unteren Rand zeigt den Status der Warteschlang für OCR-Aufträge (Texterkennung) an. Die „Warteschlange“ bezieht sich auf Dokumente, die auf ihre Verarbeitung warten.
Alternative Software und weitere Informationen zum Thema findest du unter anderem hier: