

VevestaX is an open source Python package for ML Engineers and Data Scientists. It does the following:
- Automatic EDA on the data
- ML Experiment tracking: Tracking features sourced from data, feature engineered and variables used over multiple experiments
- Checking the code into Github after every experiment runs.
The output is an excel file. The library can be used with Jupyter notebook, IDEs like spyder, Colab, Kaggle notebook or while running the python script through command line. VevestaX is framework agnostic. You can use it with any machine learning or deep learning framework.
- How to Install VevestaX
- How to import VevestaX and create the experiment object
- How to extract features present in input pandas/pyspark dataframe
- How to extract engineered features
- How to track variables used
- How to write the features and modelling variables in an given excel file
- How to commit file, features and parameters to Vevesta
- How to configure Github and Vevesta token
- Snapshots of output excel file
pip install vevestaX
#import the vevesta Library
from vevestaX import vevesta as v
V=v.Experiment()


V.start() and V.end() form a code block and can be called multiple times in the code to track variables used within the code block. Any technique such as XGBoost, decision tree, etc can be used within this code block. All computed variables will be tracked between V.start() and V.end(). When using jupyter notebook or python script, if V.start() and V.end() is not used, all the variables used in the code will be tracked.
Code snippet:
#Track variables which have been used for modelling
V.start()
# you can also use: V.startModelling()
# All the variables mentioned here will be tracked
epochs=100
seed=3
accuracy = computeAccuracy() #this will be computed variable
recall = computeRecall() #This will be computed variable
loss='rmse'
#end tracking of variables
V.end()
# or, you can also use : V.endModelling()
# Dump the datasourcing, features engineered and the variables tracked in a xlsx file
V.dump(techniqueUsed='XGBoost',filename="vevestaDump1.xlsx",message="XGboost with data augmentation was used",version=1, repoName='My_Project')
Alternatively, write the experiment into the default file, vevesta.xlsx
V.dump(techniqueUsed='XGBoost')
Vevesta is Feature and Technique Dictionary. The tool is free to use. Please create a login on vevesta . Then go to Setting section, download the access token. Place this token in the same folder as the jupyter notebook or python script. If by chance you face difficulties, please do mail [email protected].
You can commit the file(code),features and parameters to Vevesta by using the following command. You will find the project id for your project on the home page.
V.commit(techniqueUsed = "XGBoost", message="increased accuracy", filename="experimentDump.xlsx", version=1, projectId=1, repoName='My_Project')
#or you can just run the following function
V.commit(techniqueUsed = "XGBoost", projectId=1)
A sample output excel file has been uploaded on google sheets. Its url is here
The library does EDA automatically on the data.
V.EDA(data = df,Y = df["target"])
In order to check-in the code to Git and Vevesta we would be requiring the two tokens mentioned below:
- Git-Access Token
- Vevesta Access Token
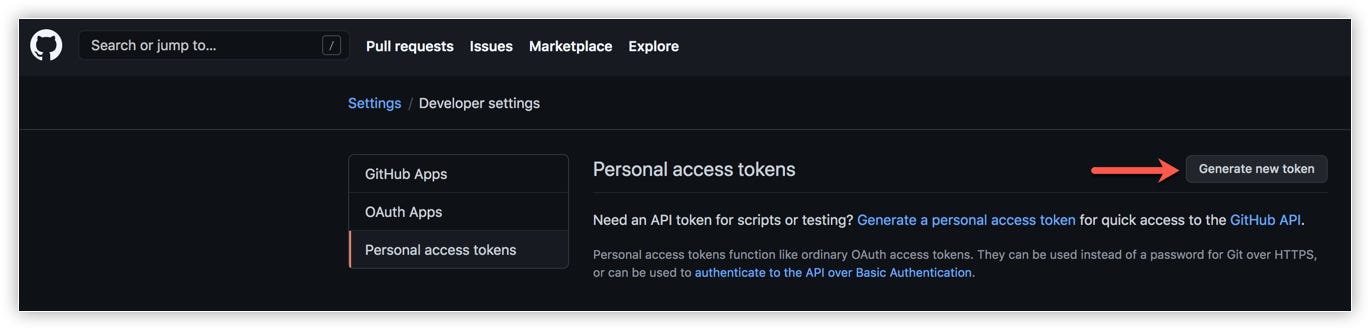
- Navigate to your Git account settings, then to Developer Settings. Click the Personal access tokens menu, then click Generate new token.
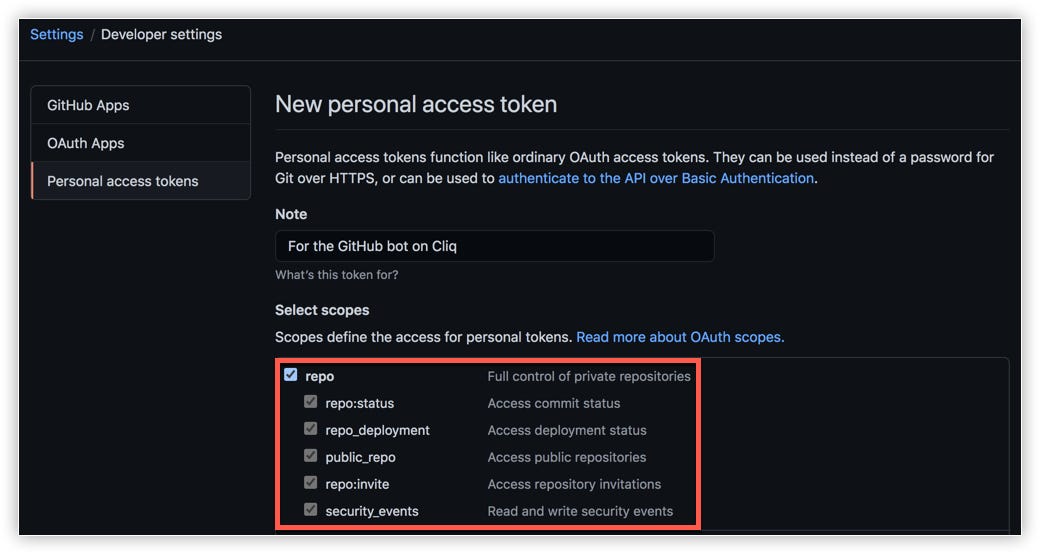
- Select repo as the scope. The token will be applicable for all the specified actions in your repositories.
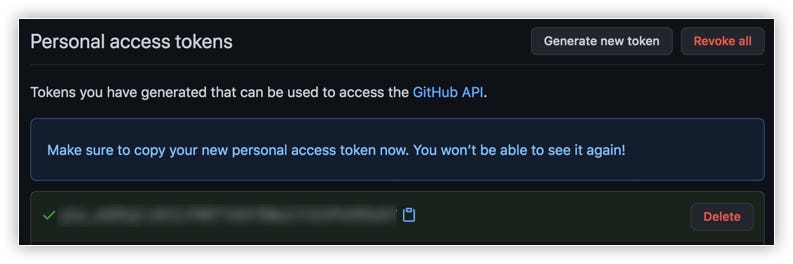
- Click Generate Token: GitHub will display the personal access token. Make sure to copy the token and store it as a txt file by renaming it to git_token.txt in the folder where the jupyter notebook or the python script is present.
We will use this token in the Integration function’s code, which will enable us to fetch the necessary information about the repositories from GitHub.
-
Create a login on vevesta.
-
Then go to the Setting section, download the access token and place this token as it is without renaming in the same folder where the jupyter notebook or python script is present.
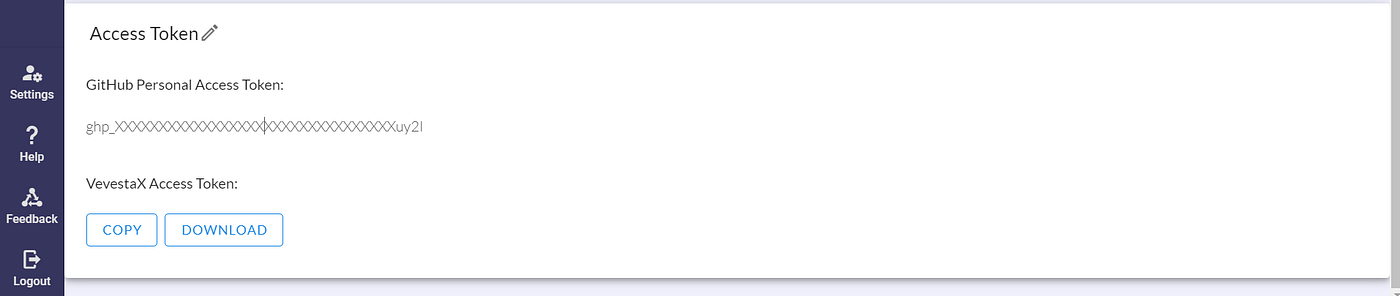
This is how our folder looks when we have downloaded the above two tokens. Along with the two tokens we have with us: the jupyter notebook named ZIP.ipynb and Dataset named fish.csv.

After running calling the dump or commit function for each run of the code. The features used, features engineered and the variables used in the experiments get logged into the excel file. In the below experiment, the commit/dump function is called 6 times and each time an experiment/code run is written into the excel sheet.
For the above code snippet, each row in the excel sheet corresponds to an experiment/code run. The excel sheet will have the following:
- Data Sourcing tab: Marks which Features (or columns) in wine.csv were read from the input file. Presence of the feature is marked as 1 and absence as 0.
- Feature Engineering tab: Features engineered such as salary_Ratio1 exist as columns in the excel. Value 1 means that feature was engineered in that particular experiment and 0 means it was absent.
- Modelling tab: This tab tracks all the variables used in the code. Say variable precision was computed in the experiment, then for the experiment ID i, precision will be a column whose value is computed precision variable. Note: V.start() and V.end() are code blocks that you might define. In that case, the code can have multiple code blocks. The variables in all these code blocks are tracked together. Let us define 3 code blocks in the code, first one with precision, 2nd one with recall and accuracy and 3rd one with epoch, seed and no of trees. Then for experiment Id , all the variables, namely precision, recall, accuracy, epoch, seed and no. of trees will be tracked as one experiment and dumped in a single row with experiment id . Note, if code blocks are not defined then it that case all the variables are logged in the excel file.
- Messages tab: Data Scientists like to create new files when they change technique or approach to the problem. So everytime you run the code, it tracks the experiment ID with the name of the file which had the variables, features and features engineered.
- EDA-correlation: correlation is calculated on the input data automatically.
- EDA-box Plot tab: Box plots for numeric features
- EDA-Numeric Feature Distribution: Scatter plot with x axis as index in the data and y axis as the value of the data point.
- EDA-Feature Histogram: Histogram of numeric features






If you liked the library, please give us a github star and retweet .
For additional features, explore our tool at Vevesta . For comments, suggestions and early access to the tool, reach out at [email protected]
We at Vevesta Labs are maintaining this library and we welcome feature requests.