
gftest is a program for automatically generating systematic test
cases for GF grammars. The basic use case is to give gftest a
PGF grammar, a concrete language and a function; then gftest generates a
representative and minimal set of example sentences for a human to look at.
There are examples of actual generated test cases later in this
document, as well as the full list of options to give to gftest.
It is recommended to compile your PGF with the gf flag --optimize-pgf, otherwise this tool can be very slow.
For example, gf -make --optimize-pgf LangEng.gf.
Check out instructions in this Travis file.
You need the library PGF2, which in turn needs the C runtime for GF. Here are instructions how to install:
- Install C runtime: go to the directory gf-core/src/runtime/c, see instructions in INSTALL
- Install PGF2 in one of the two ways:
- EITHER Go to the directory
gf-core/src/runtime/haskell-bind,
do
cabal install - OR Go to the root directory of
gf-core and compile GF
with C-runtime system support:
cabal install -fc-runtime, see more information here.
If you get problems, try the following:
- Remember that you only need the library
PGF2, nothing else (e.g. thegfexecutable doesn't need to work with the C runtime). If you tried installing GF with C-runtime system support, try the lighter version (only installing gf-core/src/runtime/haskell-bind). If that didn't work either, comment out all executables from the cabal file in gf-core/src/runtime/haskell-bind and try again. - Libraries not found? Find where they are installed, and try the cabal/stack options
--extra-lib-dirsor--extra-include-dirs. For example:stack install --extra-include-dirs="/usr/local/include" --extra-lib-dirs="/usr/local/lib"- Using Linux? Try setting up
LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/lib"in your terminal customisation file, such as.bash_profile,.bashrcor.profile
- Using Linux? Try setting up
- You don't know where to find your libraries yourself? Type
ghc-pkg listfor globally installed packages, andghc-pkg list --userfor local. Then you get an output that starts with a directory on your computer. Go to that directory (e.g./Users/<your name>/.ghc/<version>/package.conf.don a mac), open the conf file for the library you're looking for (e.g./<the previous path>/pgf2-0.1.0.0-Dlg7UYqHGJjFEoG8RlgBvb.conf) and there you find the path you're looking for underlibrary-dirs:. - Any other problem? Contact me: you can e.g. open an issue at GitHub, come to the #gf IRC channel, send an email to gf-dev list or personally to me ([email protected])
Clone this repository git clone https://github.com/GrammaticalFramework/gftest.git. In the root
directory (gftest), type cabal install or stack install. This
creates an executable gftest.
Run gftest --help of gftest -? to get the list of options.
Common flags:
-g --grammar=FILE Path to the grammar (PGF) you want to test
-l --lang="Eng Swe" Concrete syntax + optional translations
-f --function=UseN Test the given function(s)
-c --category=NP Test all functions with given goal category
-t --tree="UseN tree_N" Test the given tree
-s --start-cat=Utt Use the given category as start category
--show-cats Show all available categories
--show-funs Show all available functions
--funs-of-arity=2 Show all functions of arity 2
--show-coercions Show coercions in the grammar
--show-contexts=8140 Show contexts for a given concrete type or a range
of concrete types (given as FIds)
--concr-string=the Show all functions that include given string
-q --equal-fields Show fields whose strings are always identical
-e --empty-fields Show fields whose strings are always empty
-u --unused-fields Show fields that never make it into the top category
-r --erased-trees Show trees that are erased
-o --old-grammar=ITEM Path to an earlier version of the grammar
--only-changed-cats When comparing against an earlier version of a
grammar, only test functions in categories that have
changed between versions
--only-lexicon When comparing against an earlier version of a
grammar, only test lexical categories
-b --treebank=ITEM Path to a treebank
--count-trees=3 Number of trees of size <3>
-d --debug Show debug output
-w --write-to-file Write the results in a file (<GRAMMAR>_<FUN>.org)
-? --help Display help message
-V --version Print version information
Give the PGF grammar as an argument with -g. If the file is not in
the same directory, you need to give the full file path.
It is recommended to compile your PGF with the gf flag --optimize-pgf, otherwise this tool can be very slow.
For example, gf -make --optimize-pgf FoodsEng.gf FoodsGer.gf.
You can give the grammar with or without .pgf.
Without a concrete syntax you can't do much, but you can see the
available categories and functions with --show-cats and --show-funs
Examples:
gftest -g Foods --show-funsgftest -g /home/inari/grammars/LangEng.pgf --show-cats
Give a concrete language. It assumes the format AbsNameConcName, and you should only give the ConcName part.
You can give multiple languages, in which case it will create the test cases based on the first, and show translations in the rest.
Examples:
gftest -g Phrasebook -l Swe --show-catsgftest -g Foods -l "Spa Eng" -f Pizza
Given a grammar (-g) and a concrete language ( -l), test a function or several functions.
Examples:
gftest -g Lang -l "Dut Eng" -f UseNgftest -g Phrasebook -l Spa -f "ByTransp ByFoot"
You can use the wildcard *, if you want to match multiple functions. Examples:
gftest -g Lang -l Eng -f "*hat*"
matches hat_N, hate_V2, that_Quant, that_Subj, whatPl_IP and whatSg_IP.
gftest -g Lang -l Eng -f "*hat*u*"
matches that_Quant and that_Subj.
gftest -g Lang -l Eng -f "*"
matches all functions in the grammar. (As of March 2018, takes 13 minutes for the English resource grammar, and results in ~40k lines. You may not want to do this for big grammars.)
Give a start category for contexts. Used in conjunction with -f,
-c, -t or --count-trees. If not specified, contexts are created
for the start category of the grammar.
Example:
gftest -g Lang -l "Dut Eng" -f UseN -s Adv
This creates a hole of CN in Adv, instead of the default start category.
Given a grammar (-g) and a concrete language ( -l), test all functions that return a given category.
Examples:
gftest -g Phrasebook -l Fre -c Modalitygftest -g Phrasebook -l Fre -c ByTransport -s Action
Given a grammar (-g) and a concrete language ( -l), test a complete tree.
Example:
gftest -g Phrasebook -l Dut -t "ByTransp Bus"
You can combine it with any of the other flags, e.g. put it in a different start category:
gftest -g Phrasebook -l Dut -t "ByTransp Bus" -s Action
This may be useful for the following case. Say you tested PrepNP,
and the default NP it gave you only uses the word car, but you
would really want to see it for some other noun—maybe car_N itself
is buggy, and you want to be sure that PrepNP works properly. So
then you can call the following:
gftest -g TestLang -l Eng -t "PrepNP with_Prep (MassNP (UseN beer_N))"
Give a grammar, a concrete syntax, and an old version of the same grammar as a separate PGF file. The program generates test sentences for all functions (if no other arguments), linearises with both grammars, and outputs those that differ between the versions. It writes the differences into files.
Example:
> gftest -g TestLang -l Eng -o TestLangOld
Created file TestLangEng-ccat-diff.org
Testing functions in…
<categories flashing by>
Created file TestLangEng-lin-diff.org
Created files TestLangEng-(old|new)-funs.org
-
TestLangEng-ccat-diff.org: All concrete categories that have changed. Shows e.g. if you added or removed a parameter or a field.
-
TestLangEng-lin-diff.org (usually the most relevant file): All trees that have different linearisations in the following format.
* send_V3
** UseCl (TTAnt TPres ASimul) PPos (PredVP (UsePron we_Pron) (ReflVP (Slash3V3 ∅ (UsePron it_Pron))))
TestLangDut> we sturen onszelf ernaar
TestLangDut-OLD> we sturen zichzelf ernaar
** UseCl (TTAnt TPast ASimul) PPos (PredVP (UsePron we_Pron) (ReflVP (Slash3V3 ∅ (UsePron it_Pron))))
TestLangDut> we stuurden onszelf ernaar
TestLangDut-OLD> we stuurden zichzelf ernaar
- TestLangEng-old-funs.org and TestLangEng-new-funs.org: groups the functions by their concrete categories. Shows difference if you have e.g. added or removed parameters, and that has created new versions of some functions: say you didn't have gender in nouns, but now you have, then all functions taking nouns have suddenly a gendered version. (This is kind of hard to read, don't worry too much if the output doesn't make any sense.)
The default mode is to test all functions, but you can also give any
combination of -s, -f, -c, --treebank/-b, --only-changed-cats
and --only-lexicon.
With -s, you can change the start category in which contexts are
generated.
With -f and -c, it tests only the specified functions and
categories.
With -b FILEPATH (-b=--treebank), it tests only the trees in the file.
With --only-changed-cats, it only test functions in those categories
that have changed between the two versions.
With --only-lexicon, it only tests functions that don't take arguments.
This mostly corresponds to lexical categories (but not always: it will
also catch e.g. hungry_VP in Construction).
Note that this is pretty much overkill when you only want to test lexicon. For big grammars, even this takes a long time, so you might want to try easier alternatives, if lexicon is the only thing you need to test.
Examples:
gftest -g TestLang -l Eng -o old/TestLangtests all functionsgftest -g TestLang -l Eng -o old/TestLang -s Stests all functions in start category Sgftest -g TestLang -l Eng -o old/TestLang --only-changed-catstests only changed categories. If no categories have changed (and no other arguments specified), tests everything.gftest -g TestLang -l Eng -o old/TestLang -f "AdjCN AdvCN" -c Adv -b trees.txttests functions,AdjCNandAdvCN; same for all functions that produce anAdv, and all trees in trees.txt.gftest -g TestLang -l Eng -o old/TestLang --only-lexicontests only functions without arguments (a good proxy for lexical functions).
Show all functions that introduce the string given as an argument.
Example:
gftest -g Lang -l Eng --concr-string it
which gives the answer ==> CleftAdv, CleftNP, DefArt, ImpersCl, it_Pron
(Note that you have the same feature in GF shell, command morpho_analyse/ma.)
Writes the results into a file of format <GRAMMAR>_<FUN or CAT>.org,
e.g. TestLangEng-UseN.org. Recommended to open it in emacs org-mode,
so you get an overview, and you can maybe ignore some trees if you
think they are redundant.
-
When you open the file, you see a list of generated test cases, like this:
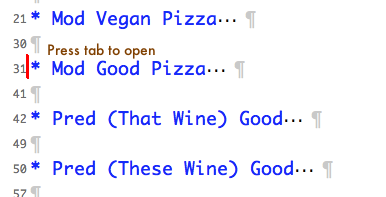
Place cursor to the left and click tab to open it. -
You get a list of contexts for the test case. Keep the cursor where it was if you want to open everything at the same time. Alternatively, scroll down to one of the contexts and press tab there, if you only want to open one.
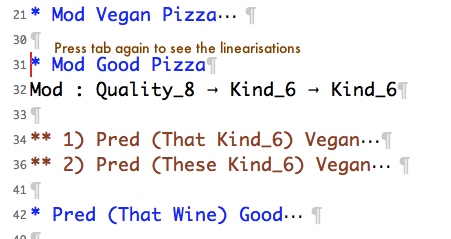
-
Now you can read the linearisations.
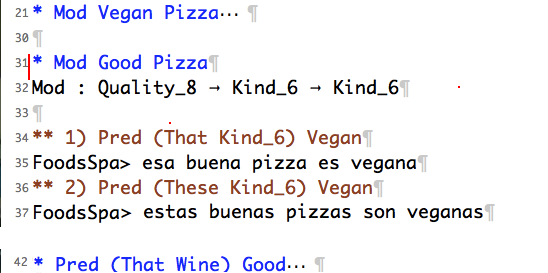
If you want to close the test case, just press tab again, keeping the cursor where it's been all the time (line 31 in the pictures).
The topics here require some more obscure GF-fu. No need to worry if the terms are not familiar to you.
Information about the fields: always empty, or always equal to each other. Example of empty fields:
> gftest -g Lang -l Dut -e
* Empty fields:
==> Ant: s
==> Pol: s
==> Temp: s
==> Tense: s
==> V: particle, prefix
The categories Ant, Pol, Temp and Tense are as expected empty;
there's no string to be added to the sentences, just a parameter that
chooses the right forms of the clause.
V having empty fields particle and prefix is in this case just
an artefact of a small lexicon: we happen to have no intransitive
verbs with a particle or prefix in the core 300-word vocabulary. But a
grammarian would know that it's still relevant to keep those fields,
because in some bigger application such a verb may show up.
On the other hand, if some other field is always empty, it might be a hint for the grammarian to remove it altogether.
Example of equal fields:
> gftest -g Lang -l Dut -q
* Equal fields:
==> RCl:
s Pres Simul Pos Utr Pl
s Pres Simul Pos Neutr Pl
==> RCl:
s Pres Simul Neg Utr Pl
s Pres Simul Neg Neutr Pl
==> RCl:
s Pres Anter Pos Utr Pl
s Pres Anter Pos Neutr Pl
==> RCl:
s Pres Anter Neg Utr Pl
s Pres Anter Neg Neutr Pl
==> RCl:
s Past Simul Pos Utr Pl
s Past Simul Pos Neutr Pl
…
Here we can see that in relative clauses, gender does not seem to play
any role in plural. This could be a hint for the grammarian to make a
leaner parameter type, e.g. param RClAgr = SgAgr <everything incl. gender> | PlAgr <no gender here>.
These fields are not empty, but they are never used in the top
category. The top category can be specified by -s, otherwise it is
the default start category of the grammar.
Note that if you give a start category from very low, such as Adv,
you get a whole lot of categories and fields that naturally have no
way of ever making it into an adverb. So this is mostly meaningful to
use for the start category.
Show trees that are erased in some function, i.e. a function F : A -> B -> C has arguments A and B, but doesn't use one of them in the resulting tree of type C. This is usually a bug.
Example:
> gftest -g Lang -l "Dut Eng" -r
* Erased trees:
** RelCl (ExistNP something_NP) : RCl
- Tree: AdvS (PrepNP with_Prep (RelNP (UsePron it_Pron) (UseRCl (TTAnt TPres ASimul) PPos (RelCl (ExistNP something_NP))))) (UseCl (TTAnt TPres ASimul) PPos (ExistNP something_NP))
- Lin: ermee is er iets
- Trans: with it, such that there is something, there is something
** write_V2 : V2
- Tree: AdvS (PrepNP with_Prep (PPartNP (UsePron it_Pron) write_V2)) (UseCl (TTAnt TPres ASimul) PPos (ExistNP something_NP))
- Lin: ermee is er iets
- Trans: with it written there is something
In the first result, an argument of type RCl is missing in the tree constructed by RelNP, and in the second result, the argument write_V2 is missing in the tree constructed by PPartNP. In both cases, the English linearisation contains all the arguments, but in the Dutch one they are missing. (This bug is already fixed, just showing it here to demonstrate the feature.)
When combined with -f, -c or -t, two things happen:
- The trees are linearised using
tabularLinearize, which shows the inflection table of all forms. - You can see traces of pruning that happens in testing functions: contexts that are common to several concrete categories are put under a separate test case.
When combined with --show-cats, also the concrete categories are
shown.
Shows the categories in the grammar. With --debug/-d, shows also
concrete categories.
Example:
> gftest -g Foods -l Spa --show-cats -d
* Categories in the grammar:
Comment
Compiles to concrete category 0
Item
Compiles to concrete categories 1—4
Kind
Compiles to concrete categories 5—6
Quality
Compiles to concrete categories 7—8
Question
Compiles to concrete category 9
Shows the functions in the grammar. (Nothing fancy happens with other flags.)
First I'll explain what coercions are, then why it may be
interesting to show them. Let's take a Spanish Foods grammar, and
consider the category Quality, e.g. Good and Vegan.
Good "bueno/buena/buenos/buenas" goes before the noun it modifies,
whereas Vegan "vegano/vegana/…" goes after, so these will become different
concrete categories in the PGF: Quality_before and
Quality_after. (In reality, they are something like Quality_7 and
Quality_8 though.)
Now, this difference is meaningful only when the adjective is modifying
the noun: "la buena pizza" vs. "la pizza vegana". But when the
adjective is in a predicative position, they both behave the same:
"la pizza es buena" and "la pizza es vegana". For this, the grammar
creates a coercion: both Quality_before and Quality_after may be
treated as Quality_whatever. To save some redundant work, this coercion Quality_whatever
appears in the type of predicative function, whereas the
modification function has to be split into two different functions,
one taking Quality_before and other Quality_after.
Now you know what coercions are, this is how it looks like in the program:
> gftest -g Foods -l Spa --show-coercions
* Coercions in the grammar:
Quality_7--->_11
Quality_8--->_11
(Just mentally replace 7 with before, 8 with after and 11 with whatever.)
Show contexts for a given concrete category, given as an FId
(i.e. Int). The concrete category may be a coercion or a normal
category. By combining with -s,
you can change the start category of the context.
(You can get a list of all concrete categories by pairing --show-cats
with --debug: see --show-cats.)
Examples:
- First, find out some concrete categories:
> gftest -g Foods -l Spa --show-cats -d
…
Quality
Compiles to concrete categories 7—8
…
- Then, list the contexts for some of them, say
Quality_7:
> gftest -g Foods -l Spa --show-contexts 7
Pred (That (Mod ∅ Wine)) Vegan
Pred (That Wine) ∅
Pred (These (Mod ∅ Wine)) Vegan
Pred (These Wine) ∅
Pred (That (Mod ∅ Pizza)) Vegan
Pred (That Pizza) ∅
Pred (These (Mod ∅ Pizza)) Vegan
Pred (These Pizza) ∅
-
You can also give it a range of arguments, with starting and ending category in quotes:
gftest -g Foods -l Spa --show-contexts "7 10" -
Check out from
--show-coercionshow to find coercions, and you can try--show-contextswith them:
> gftest -g Foods -l Spa --show-contexts 11
Pred (That Wine) ∅
Pred (These Wine) ∅
Pred (That Pizza) ∅
Pred (These Pizza) ∅
Number of trees up to given size. Gives a number how many trees, and a couple of examples from the highest size. Examples:
> gftest -g TestLang -l Eng --count-trees 10
There are 675312 trees up to size 10, and 624512 of exactly size 10.
For example:
* AdvS today_Adv (UseCl (TTAnt TPres ASimul) PPos (ExistNP (UsePron i_Pron)))
* UseCl (TTAnt TCond AAnter) PNeg (PredVP (SelfNP (UsePron they_Pron)) UseCopula)
This counts the number of trees in the start category. You can also specify a category:
> gftest -g TestLang -l Eng --count-trees 4 -s Adv
There are 2409 trees up to size 4, and 2163 of exactly size 4.
For example:
* AdAdv very_AdA (PositAdvAdj young_A)
* PrepNP above_Prep (UsePron they_Pron)
Show all functions of given arity (not up to).
Example:
> gftest -g Phrasebook --funs-of-arity 3
* Functions in the grammar of arity 3:
ADoVerbPhrasePlace
AModVerbPhrase
HowFarFromBy
QWhereModVerbPhrase